
本篇文章带大家深入解析一下mysql中的查询优化器,带大家理解一下mysql查询优化器工作原理,希望对大家有所帮助!

对于一个SQL语句,查询优化器先看是不是能转换成JOIN,再将JOIN进行优化
优化分为:1. 条件优化,2.计算全表扫描成本,3. 找出所有能用到的索引,4. 针对每个索引计算不同的访问方式的成本,5. 选出成本最小的索引以及访问方式
一、开启查询优化器日志
-- 开启set optimizer_trace="enabled=on"; -- 执行sql-- 查看日志信息select * from information_schema.OPTIMIZER_TRACE;-- 关闭set optimizer_trace="enabled=off";
二、优化器原则
1、常量传递(constant_propagation)
a = 1 AND b > a
上面这个sql可以转换为:
a = 1 AND b > 1
2、等值传递(equality_propagation)
a = b and b = c and c = 5
上面这个sql可以转换为:
a = 5 and b = 5 and c = 5
3、移除没用的条件(trivial_condition_removal)
a = 1 and 1 = 1
上面这个sql可以转换为:
a = 1
4、基于成本
一个查询可以有不同的执行方案,可以选择某个索引进行查询,也可以选择全表扫描,查询优化器会选择其中成本最低的方案去执行查询。
1)I/O成本
InnoDB存储引擎都是将数据和索引都存储到磁盘上的,当我们想查询表中的记录时,需要先把数据或者索引加载到内存中然后再操作。这个从磁盘到内存这个加载的过程损耗的时间称之为I/O成本
2)CPU成本
读取以及检测记录是否满足对应的搜索条件、对结果集进行排序等这些操作损耗的时间称之为CPU成本。
InnoDB存储引擎规定读取一个页面花费的成本默认是1.0,读取以及检测一条记录是否符合搜索条件的成本默认是0.2。
三、基于成本的优化步骤
在一条单表查询语句真正执行之前,MySQL的查询优化器会找出执行该语句所有可能使用的方案,对比之后找出成本最低的方案,这个成本最低的方案就是所谓的执行计划,之后才会调用存储引擎提供的接口真正的执行查询。
下边我们就以一个实例来分析一下这些步骤,单表查询语句如下:
select * from employees.titles where emp_no > '10101' and emp_no < '20000' and to_date = '1991-10-10';
1、根据搜索条件,找出所有可能使用的索引
• emp_no > ‘10101’,这个搜索条件可以使用主键索引PRIMARY。
• to_date = ‘1991-10-10’,这个搜索条件可以使用二级索引idx_titles_to_date。
综上所述,上边的查询语句可能用到的索引,也就是possible keys只有PRIMARY和idx_titles_to_date。
2、计算全表扫描的代价
对于InnoDB存储引擎来说,全表扫描的意思就是把聚簇索引中的记录都依次和给定的搜索条件做一下比较,把符合搜索条件的记录加入到结果集,所以需要将聚簇索引对应的页面加载到内存中,然后再检测记录是否符合搜索条件。由于查询成本=I/O成本+CPU成本,所以计算全表扫描的代价需要两个信息:
1)聚簇索引占用的页面数
2)该表中的记录数
MySQL为每个表维护了一系列的统计信息,SHOW TABLE STATUS语句来查看表的统计信息。
SHOW TABLE STATUS LIKE 'titles';
Rows
表示表中的记录条数。对于使用MyISAM存储引擎的表来说,该值是准确的,对于使用InnoDB存储引擎的表来说,该值是一个估计值。
Data_length
表示表占用的存储空间字节数。使用MyISAM存储引擎的表来说,该值就是数据文件的大小,对于使用InnoDB存储引擎的表来说,该值就相当于聚簇索引占用的存储空间大小,也就是说可以这样计算该值的大小:
Data_length = 聚簇索引的页面数量 x 每个页面的大小
我们的titles使用默认16KB的页面大小,而上边查询结果显示Data_length的值是20512768,所以我们可以反向来推导出聚簇索引的页面数量:
聚簇索引的页面数量 = Data_length ÷ 16 ÷ 1024 = 20512768 ÷ 16 ÷ 1024 = 1252
我们现在已经得到了聚簇索引占用的页面数量以及该表记录数的估计值,所以就可以计算全表扫描成本了。但是MySQL在真实计算成本时会进行一些微调。
I/O成本:12521 = 1252。1252指的是聚簇索引占用的页面数,1.0指的是加载一个页面的成本常数。
CPU成本:4420700.2=88414。442070指的是统计数据中表的记录数,对于InnoDB存储引擎来说是一个估计值,0.2指的是访问一条记录所需的成本常数
总成本:1252+88414 = 89666。
综上所述,对于titles的全表扫描所需的总成本就是89666。
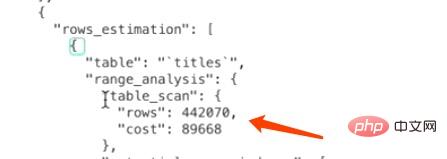
我们前边说过表中的记录其实都存储在聚簇索引对应B+树的叶子节点中,所以只要我们通过根节点获得了最左边的叶子节点,就可以沿着叶子节点组成的双向链表把所有记录都查看一遍。也就是说全表扫描这个过程其实有的B+树内节点是不需要访问的,但是MySQL在计算全表扫描成本时直接使用聚簇索引占用的页面数作为计算I/O成本的依据,是不区分内节点和叶子节点的。
3、计算PRIMARY需要成本
计算PRIMARY需要多少成本的关键问题是:需要预估出根据对应的where条件在主键索引B+树中存在多少条符合条件的记录。
范围区间数
当我们从索引中查询记录时,不管是=、in、>、<这些操作都需要从索引中确定一个范围,不论这个范围区间的索引到底占用了多少页面,查询优化器粗暴的认为读取索引的一个范围区间的I/O成本和读取一个页面是相同的。
本例中使用PRIMARY的范围区间只有一个:(10101, 20000),所以相当于访问这个范围区间的索引付出的I/O成本就是:1 x 1.0 = 1.0
预估范围内的记录数
优化器需要计算索引的某个范围区间到底包含多少条记录,对于本例来说就是要计算PRIMARY在(10101, 20000)这个范围区间中包含多少条数据记录,计算过程是这样的:
步骤1:先根据emp_no > 10101这个条件访问一下PRIMARY对应的B+树索引,找到满足emp_no > 10101这个条件的第一条记录,我们把这条记录称之为区间最左记录。步骤2:然后再根据emp_no ‘10101’ and emp_no < '20000'条件的记录条数。否则只沿着区间最左记录向右读10个页面,计算平均每个页面中包含多少记录,然后用这个平均值乘以区间最左记录和区间最右记录之间的页面数量就可以了。那么问题又来了,怎么估计区间最左记录和区间最右记录之间有多少个页面呢?计算它们父节点中对应的目录项记录之间隔着几条记录就可以了。
根据上面的步骤可以算出来PRIMARY索引的记录条数,所以读取记录的CPU成本为:26808*0.2=5361.6,其中26808是预估的需要读取的数据记录条数,0.2是读取一条记录成本常数。
PRIMARY的总成本
确定访问的IO成本+过滤数据的CPU成本=1+5361.6=5362.6
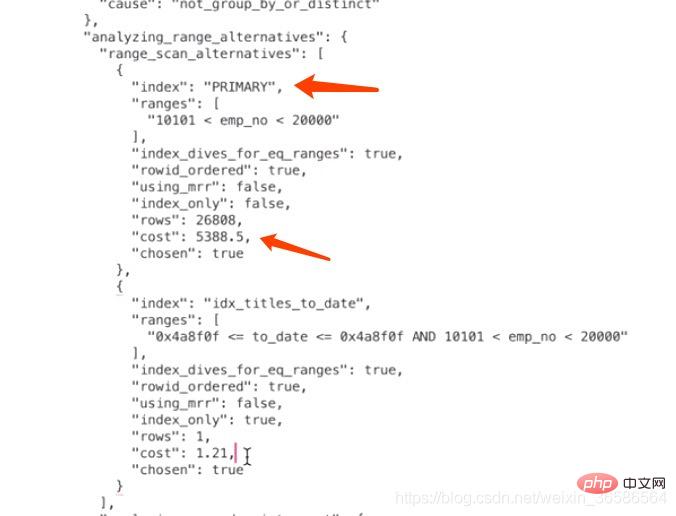
4、计算idx_titles_to_date需要成本
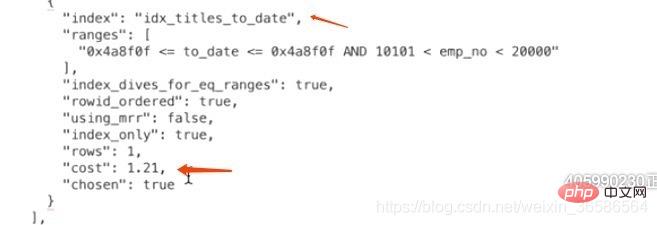
因为通过二级索引查询需要回表,所以在计算二级索引需要成本时还要加上回表的成本,而回表的成本就相当于下面这个SQL执行:
select * from employees.titles where 主键字段 in (主键值1,主键值2,。。。,主键值3);
所以idx_titles_to_date的成本 = 辅助索引的查询成本 + 回表查询的成本
5、比较各成本选出最优者
选择成本最小的索引
四、基于索引统计数据的成本计算
有时候使用索引执行查询时会有许多单点区间,比如使用IN语句就很容易产生非常多的单点区间,比如下边这个查询:
select * from employees.titles where to_date in ('a','b','c','d', ..., 'e');
很显然,这个查询可能使用到的索引就是idx_titles_to_date,由于这个索引并不是唯一二级索引,所以并不能确定一个单点区间对应的二级索引记录的条数有多少,需要我们去计算。计算方式我们上边已经介绍过了,就是先获取索引对应的B+树的区间最左记录和区间最右记录,然后再计算这两条记录之间有多少记录(记录条数少的时候可以做到精确计算,多的时候只能估算)。这种通过直接访问索引对应的B+树来计算某个范围区间对应的索引记录条数的方式称之为index pe。
如果只有几个单点区间的话,使用index pe的方式去计算这些单点区间对应的记录数也不是什么问题,可是如果很多呢,比如有20000次,MySQL的查询优化器为了计算这些单点区间对应的索引记录条数,要进行20000次index pe操作,那么这种情况下是很耗性能的,所以MySQL提供了一个系统变量eq_range_index_pe_limit,我们看一下这个系统变量的默认值:SHOW VARIABLES LIKE ‘%pe%’;为200。
也就是说如果我们的IN语句中的参数个数小于200个的话,将使用index pe的方式计算各个单点区间对应的记录条数,如果大于或等于200个的话,可就不能使用index pe了,要使用所谓的索引统计数据来进行估算。像会为每个表维护一份统计数据一样,MySQL也会为表中的每一个索引维护一份统计数据,查看某个表中索引的统计数据可以使用SHOW INDEX FROM 表名的语法。
Cardinality属性表示索引列中不重复值的个数。比如对于一个一万行记录的表来说,某个索引列的Cardinality属性是10000,那意味着该列中没有重复的值,如果Cardinality属性是1的话,就意味着该列的值全部是重复的。不过需要注意的是,对于InnoDB存储引擎来说,使用SHOW INDEX语句展示出来的某个索引列的Cardinality属性是一个估计值,并不是精确的。可以根据这个属性来估算IN语句中的参数所对应的记录数:
1)使用SHOW TABLE STATUS展示出的Rows值,也就是一个表中有多少条记录。
2)使用SHOW INDEX语句展示出的Cardinality属性。
3)根据上面两个值可以算出idx_key1索引对于的key1列平均单个值的重复次数:Rows/Cardinality
4)所以总共需要回表的记录数就是:IN语句中的参数个数*Rows/Cardinality。
NULL值处理
上面知道在统计列不重复值的时候,会影响到查询优化器。
对于NULL,有三种理解方式:
NULL值代表一个未确定的值,每一个NULL值都是独一无二的,在统计列不重复值的时候应该都当作独立的。
NULL值在业务上就是代表没有,所有的NULL值代表的意义是一样的,所以所有的NULL值都一样,在统计列不重复值的时候应该只算一个。
NULL完全没有意义,在统计列不重复值的时候应该忽略NULL。
innodb提供了一个系统变量:
show global variables like '%innodb_stats_method%';
这个变量有三个值:
nulls_equal:认为所有NULL值都是相等的。这个值也是innodb_stats_method的默认值。如果某个索引列中NULL值特别多的话,这种统计方式会让优化器认为某个列中平均一个值重复次数特别多,所以倾向于不使用索引进行访问。
nulls_unequal:认为所有NULL值都是不相等的。如果某个索引列中NULL值特别多的话,这种统计方式会让优化器认为某个列中平均一个值重复次数特别少,所以倾向于使用索引进行访问。
nulls_ignored:直接把NULL值忽略掉。
最好不在索引列中存放NULL值才是正解
五、统计数据
InnoDB提供了两种存储统计数据的方式:
• 统计数据存储在磁盘上。
• 统计数据存储在内存中,当服务器关闭时这些这些统计数据就都被清除掉了。
MySQL给我们提供了系统变量innodb_stats_persistent来控制到底采用哪种方式去存储统计数据。在MySQL 5.6.6之前,innodb_stats_persistent的值默认是OFF,也就是说InnoDB的统计数据默认是存储到内存的,之后的版本中innodb_stats_persistent的值默认是ON,也就是统计数据默认被存储到磁盘中。
不过InnoDB默认是以表为单位来收集和存储统计数据的,也就是说我们可以把某些表的统计数据(以及该表的索引统计数据)存储在磁盘上,把另一些表的统计数据存储在内存中。我们可以在创建和修改表的时候通过指定STATS_PERSISTENT属性来指明该表的统计数据存储方式。
1、基于磁盘的永久性统计数据
当我们选择把某个表以及该表索引的统计数据存放到磁盘上时,实际上是把这些统计数据存储到了两个表里:
• innodb_table_stats存储了关于表的统计数据,每一条记录对应着一个表的统计数据
• innodb_index_stats存储了关于索引的统计数据,每一条记录对应着一个索引的一个统计项的统计数据2、定期更新统计数据
• 系统变量innodb_stats_auto_recalc决定着服务器是否自动重新计算统计数据,它的默认值是ON,也就是该功能默认是开启的。每个表都维护了一个变量,该变量记录着对该表进行增删改的记录条数,如果发生变动的记录数量超过了表大小的10%,并且自动重新计算统计数据的功能是打开的,那么服务器会重新进行一次统计数据的计算,并且更新innodb_table_stats和innodb_index_stats表。不过自动重新计算统计数据的过程是异步发生的,也就是即使表中变动的记录数超过了10%,自动重新计算统计数据也不会立即发生,可能会延迟几秒才会进行计算。
•如果innodb_stats_auto_recalc系统变量的值为OFF的话,我们也可以手动调用ANALYZE TABLE语句来重新计算统计数据。ANALYZE TABLE single_table;3、控制执行计划
Index Hints
•USE INDEX:限制索引的使用范围,在数据表里建立了很多索引,当MySQL对索引进行选择时,这些索引都在考虑的范围内。但有时我们希望MySQL只考虑几个索引,而不是全部的索引,这就需要用到USE INDEX对查询语句进行设置。
•IGNORE INDEX :限制不使用索引的范围
•FORCE INDEX:我们希望MySQL必须要使用某一个索引(由于 MySQL在查询时只能使用一个索引,因此只能强迫MySQL使用一个索引)。这就需要使用FORCE INDEX来完成这个功能。
基本语法格式:
SELECT * FROM table1 USE|IGNORE|FORCE INDEX (col1_index,col2_index) WHERE col1=1 AND col2=2 AND col3=3
【相关推荐:mysql视频教程】
以上就是深入解析MySQL中的查询优化器(工作原理详解)的详细内容,更多请关注创想鸟其它相关文章!
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 chuangxiangniao@163.com 举报,一经查实,本站将立刻删除。
发布者:程序猿,转转请注明出处:https://www.chuangxiangniao.com/p/172190.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 



















