
deepseek开源盛宴:高效moe通信库deepep震撼登场!继高效mla解码核开源后,deepseek在开源周的第二天重磅推出deepep——首个用于moe模型训练和推理的ep通信库,短短时间内star数已突破千!
DeepEP针对分布式系统中MoE模型的通信瓶颈,进行了多项关键优化:
高效All-to-All通信: 显著提升数据传输效率。支持NVLink和RDMA: 实现节点内/跨节点的高速通信。高吞吐量训练/推理预填充核心: 优化预填充阶段的计算速度。低延迟推理解码核心: 降低延迟敏感的推理解码阶段的耗时。原生支持FP8数据分发: 提升计算效率。灵活的GPU资源控制: 实现计算与通信的高效重叠,避免等待。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜
 项目链接:https://www.php.cn/link/043e734f76edb5743d9b26ef5c372c51
项目链接:https://www.php.cn/link/043e734f76edb5743d9b26ef5c372c51
DeepEP的优异性能已获得广泛认可,众多开发者称其为MoE模型领域的突破性进展,尤其是在NVLink和RDMA支持方面,更是被誉为革命性的突破。

DeepEP的开源,进一步印证了DeepSeek在AI基础设施领域的创新实力,也为MoE模型的训练和推理效率提升提供了强有力的支撑。此前关于DeepSeek-R1的质疑,也因DeepEP等项目的开源而得到部分解答。
DeepEP核心功能详解:
DeepEP是一个为MoE和EP量身打造的通信库,提供高吞吐量和低延迟的all-to-all GPU内核(MoE分发和合并)。支持FP8低精度操作,并针对DeepSeek-V3论文中提出的group-limited gating算法,优化了跨不同带宽域(如NVLink到RDMA)的数据转发,兼顾训练和推理的高效性。此外,还包含一套纯RDMA低延迟内核,用于对延迟敏感的推理解码任务。通过hook-based的通信-计算重叠方法,最大限度地提升效率。
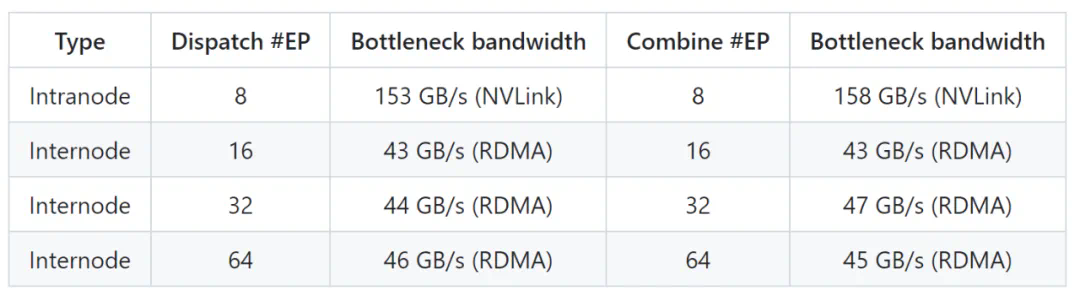
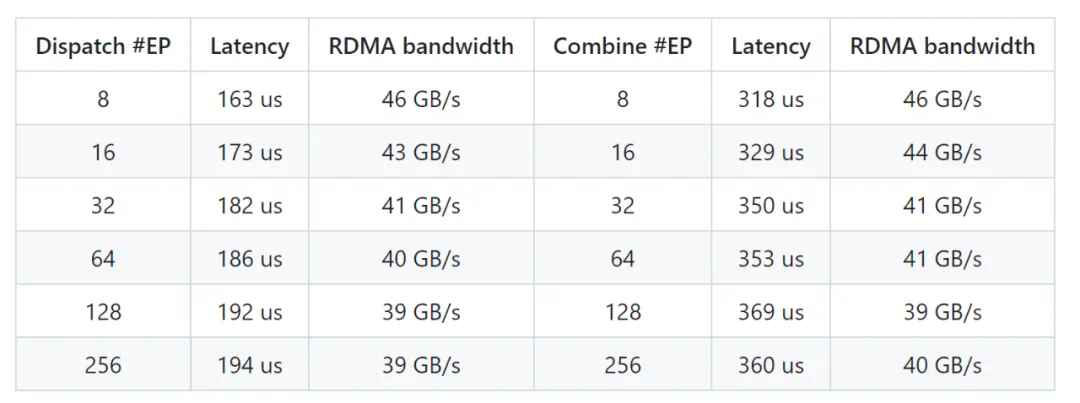
性能测试结果: 文中包含了DeepEP在H800平台上,使用常规内核和低延迟内核的性能测试数据图表(包含NVLink和RDMA转发)。
注意事项: DeepEP使用了未公开的PTX指令,可能在某些平台上存在兼容性问题,开发者可根据文档中的说明进行调整。
DeepSeek开源行动仍在继续,让我们拭目以待明天将会有哪些惊喜!

以上就是刚刚,DeepSeek开源MoE训练、推理EP通信库DeepEP,真太Open了!的详细内容,更多请关注创想鸟其它相关文章!
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 chuangxiangniao@163.com 举报,一经查实,本站将立刻删除。
发布者:程序猿,转转请注明出处:https://www.chuangxiangniao.com/p/172735.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 



























