
上海交大、中科大及上海人工智能实验室团队研发出无需训练的视频重打光技术light-a-video,该技术突破了传统方法的高训练成本和数据稀缺瓶颈,实现了零样本视频重打光。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

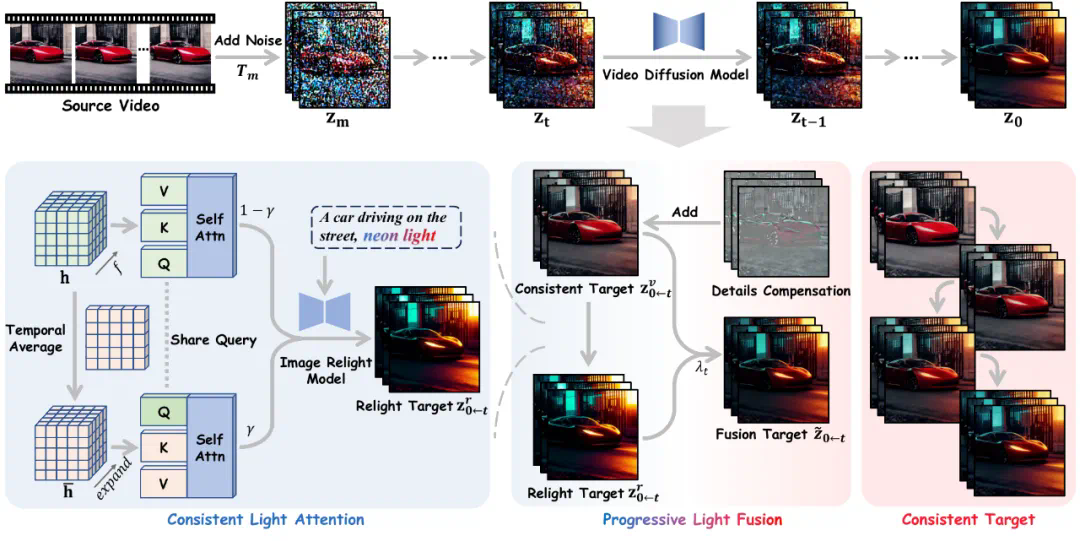
Light-A-Video的核心在于巧妙地结合了预训练的图像重打光模型(例如IC-Light)和视频扩散模型(例如AnimateDiff和CogVideoX)。通过Consistent Light Attention (CLA)模块和Progressive Light Fusion (PLF)策略,该技术有效地解决了视频重打光中的光照一致性和时间连贯性问题。

Light-A-Video 的主要优势:
无需训练,高效便捷: 直接利用预训练模型,省去了耗时的训练过程,极大提升效率。端到端流程,确保一致性: CLA模块稳定背景光源,PLF策略保证时间连贯性,避免闪烁等问题。广泛适用性: 支持完整视频或前景序列重打光,并可根据文字描述生成背景,兼容多种视频生成框架。
论文地址:https://www.php.cn/link/6563f4cdc1f2ef1ad710ad6772ea022b项目主页:https://www.php.cn/link/e14f2c0c9152f1c78681652ff1189f2b代码地址:https://www.php.cn/link/1194292054da355d3be4c0d3b69b9d9f
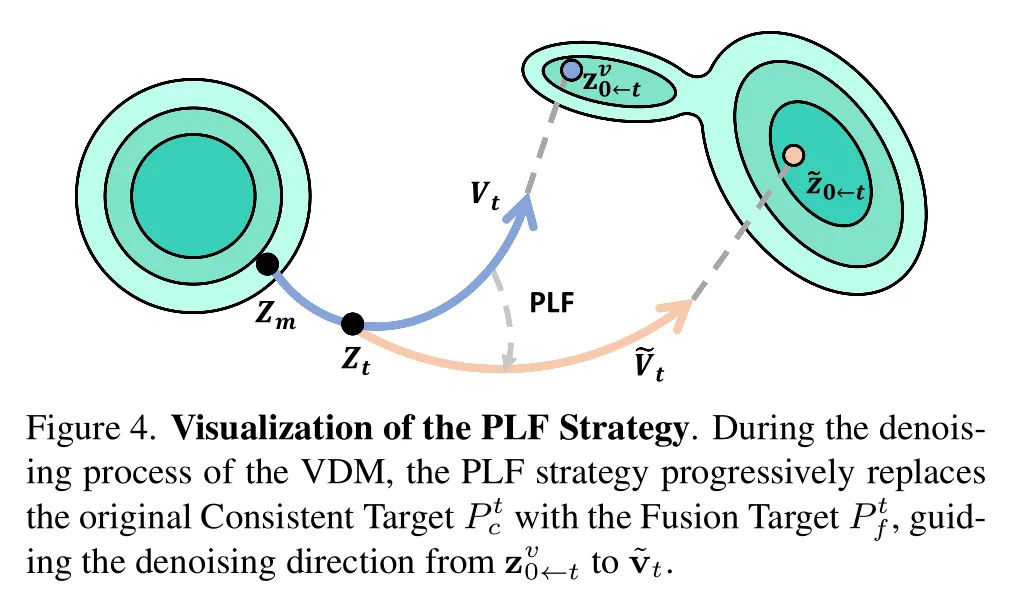
CLA和PLF模块详解:
CLA模块通过双重注意力融合,保留细节的同时减少光照抖动,实现稳定光照效果。PLF策略则通过逐步混合的方式,平滑地过渡光照,保持时间连贯性。
Light-A-Video架构图:
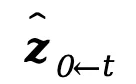
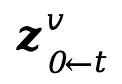
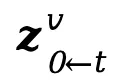
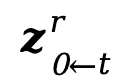
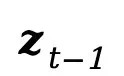
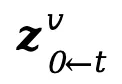
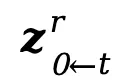
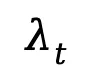
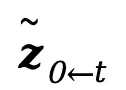
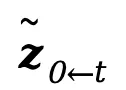
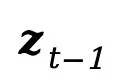
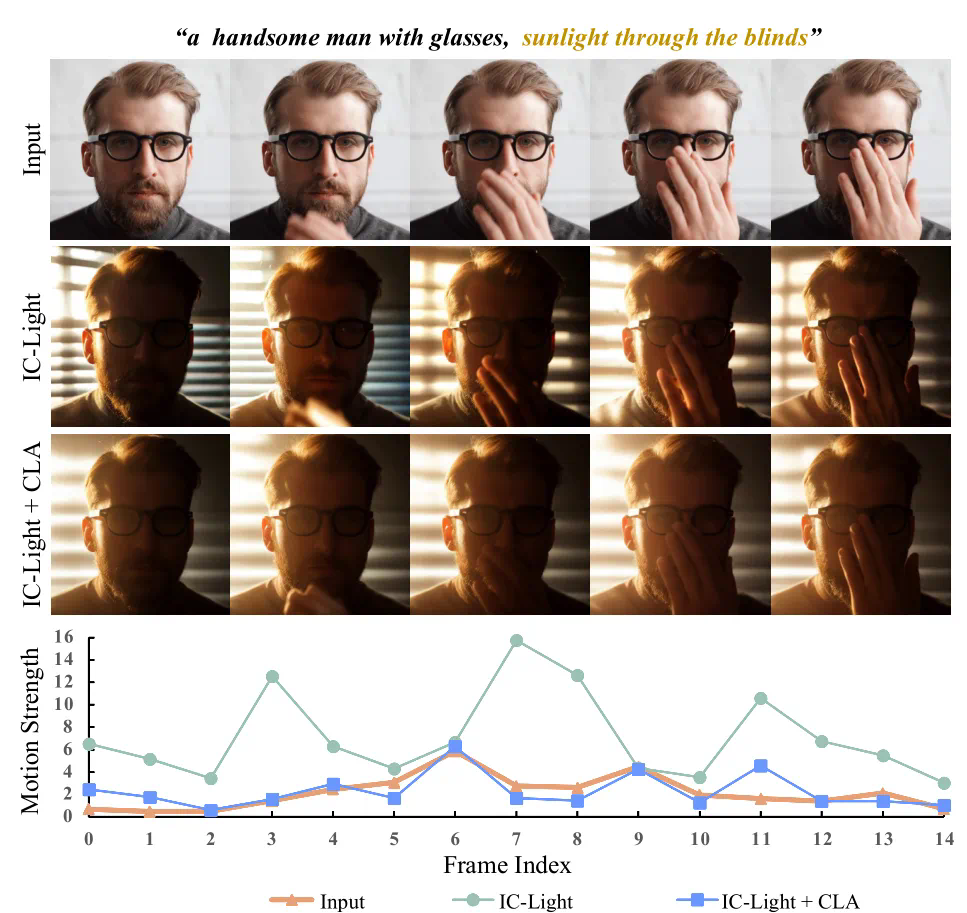
实验结果:
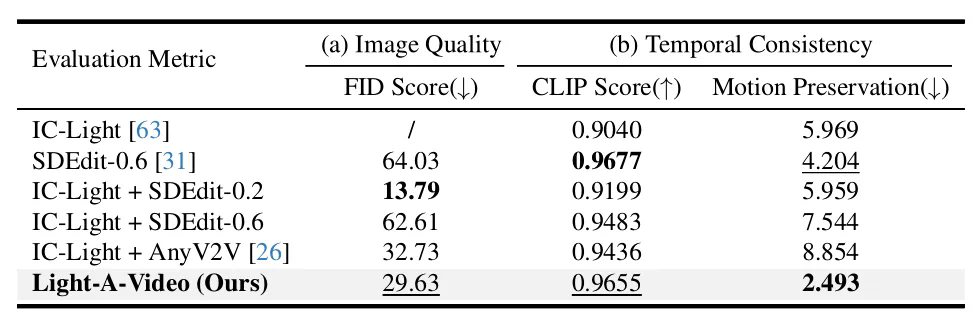
Light-A-Video在多个指标上超越现有方法,尤其在动作保留方面表现出色,实现了高质量、时间连贯的重打光效果。 该技术也支持仅用前景序列进行背景生成和重打光。

未来发展:
团队将进一步改进Light-A-Video,以更好地处理动态光照,拓展其应用范围。 Light-A-Video有望在视频编辑领域带来革命性变革。
以上就是视频版IC-Light来了!Light-A-Video提出渐进式光照融合,免训练一键视频重打光的详细内容,更多请关注创想鸟其它相关文章!
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 chuangxiangniao@163.com 举报,一经查实,本站将立刻删除。
发布者:程序猿,转转请注明出处:https://www.chuangxiangniao.com/p/175703.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 





























