
北京大学彭宇新教授团队在细粒度多模态大模型领域取得突破性进展,其研究成果已被iclr 2025接收并开源。该团队研发的finedefics模型显著提升了多模态大模型的细粒度视觉识别能力,在六个权威数据集上的平均准确率达到76.84%,超越了现有模型。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

挑战与突破:细粒度视觉识别的瓶颈
现有多模态大模型在通用视觉任务中表现出色,但在细粒度视觉识别方面存在不足。细粒度识别要求区分同一大类下的细微差别,例如区分不同鸟类、汽车品牌和型号等。 这主要是因为缺乏足够的细粒度标注数据,导致模型难以学习到细微的视觉特征。
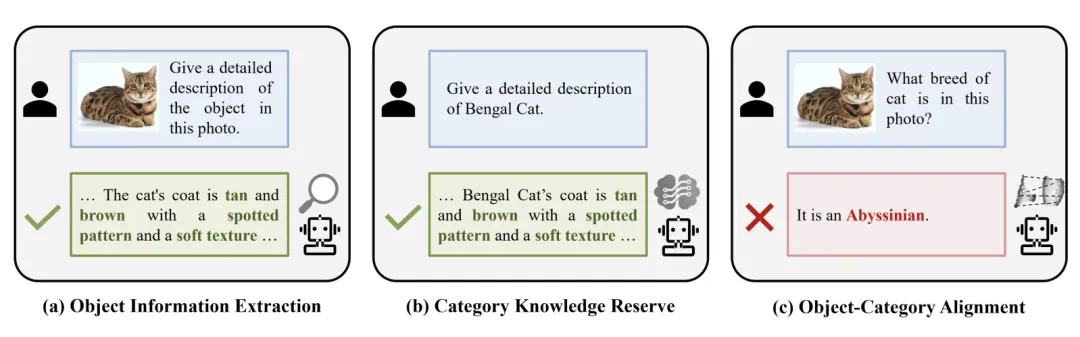
Finedefics模型正是为了解决这一难题而生。该团队深入分析了多模态大模型在细粒度识别中所需的三个关键能力:对象信息提取、类别知识储备和对象-类别对齐。研究发现,对象与类别的错位匹配是制约模型性能的关键。
Finedefics:巧妙的对齐策略
Finedefics模型通过两阶段训练策略巧妙地解决了对象-类别对齐问题:
属性描述构建: 利用大语言模型挖掘细粒度属性,例如描述鸟类的羽毛颜色、形状等,并将其与图像特征结合,生成更精细的图像描述。
属性增强对齐: 通过对比学习,将图像特征、属性描述和类别信息进行对齐,强化模型学习细微视觉特征与类别标签之间的对应关系。 这包括对象-属性、属性-类别和类别-类别三个层次的对比学习。 此外,模型还进行了以识别为中心的指令微调,进一步提升了模型的识别准确性。

显著成果与未来展望
Finedefics在六个权威数据集上取得了显著成果,平均准确率达到76.84%,相比于Idefics2模型提升了10.89%。 这表明Finedefics有效地提升了多模态大模型的细粒度视觉识别能力。
资源链接:
论文标题: Analyzing and Boosting the Power of Fine-Grained Visual Recognition for Multi-modal Large Language Models论文链接: https://www.php.cn/link/352d47cf1a528e7f85aca7ef55669802开源代码: https://www.php.cn/link/78785f4debd23c24e93850db2f58b88e模型地址: https://www.php.cn/link/fbb25c1fc3c9ad12a80d06b6218932d8实验室网址: https://www.php.cn/link/bef5b4d93c3ae02ace550506a9a936de
Finedefics的成功为多模态大模型在细粒度视觉识别领域的应用提供了新的方向,也为后续研究提供了宝贵的经验。 该团队的研究成果为推动细粒度视觉识别技术的发展做出了重要贡献。
以上就是北大彭宇新教授团队开源细粒度多模态大模型Finedefics的详细内容,更多请关注创想鸟其它相关文章!
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 chuangxiangniao@163.com 举报,一经查实,本站将立刻删除。
发布者:程序猿,转转请注明出处:https://www.chuangxiangniao.com/p/177880.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 




























