
腾讯ai lab联合苏州大学、上海交通大学团队的研究揭示了长推理模型的“思考不足”现象,并提出了一种改进方法。这项研究发表于arxiv,通讯作者为腾讯专家研究员涂兆鹏。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

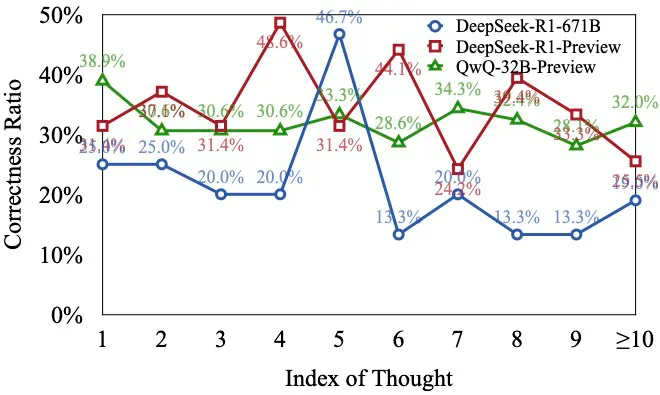
研究发现,类似OpenAI o1等长推理模型,虽然展现出强大的深度思考能力,但在解决复杂问题时,往往会频繁切换思路,无法深入思考某个方向,导致最终答案错误。 研究团队将这种现象称为“思考不足”(Underthinking),并将其比喻为模型的“注意力缺陷多动障碍”。

论文题目:Thoughts Are All Over the Place: On the Underthinking of o1-Like LLMs论文地址:https://www.php.cn/link/3e33f40836bd425bbdf92b71cc707cee
研究团队通过分析不同难度级别的数学问题,发现模型在难题上的错误答案往往伴随着更多的思路切换和更长的 token 数量,但准确率并未提升。 他们进一步提出了一种“思考不足”评分机制,定量评估模型在错误回答中推理效率的低下程度。

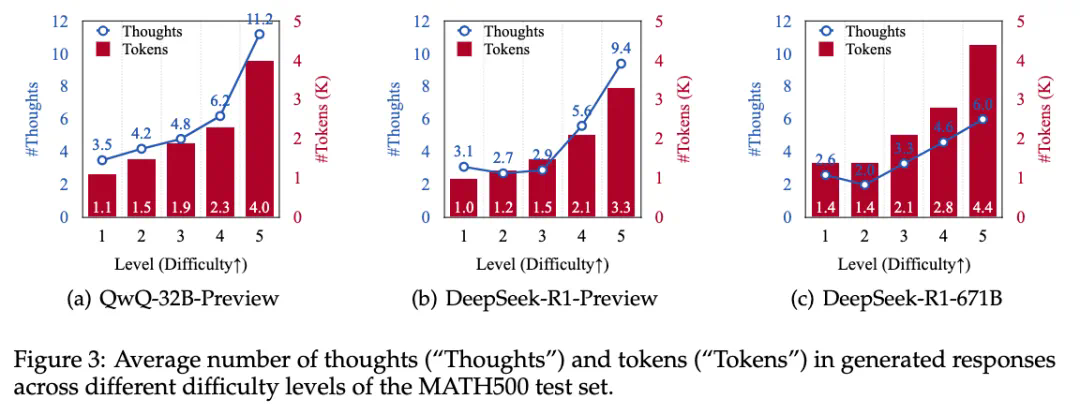
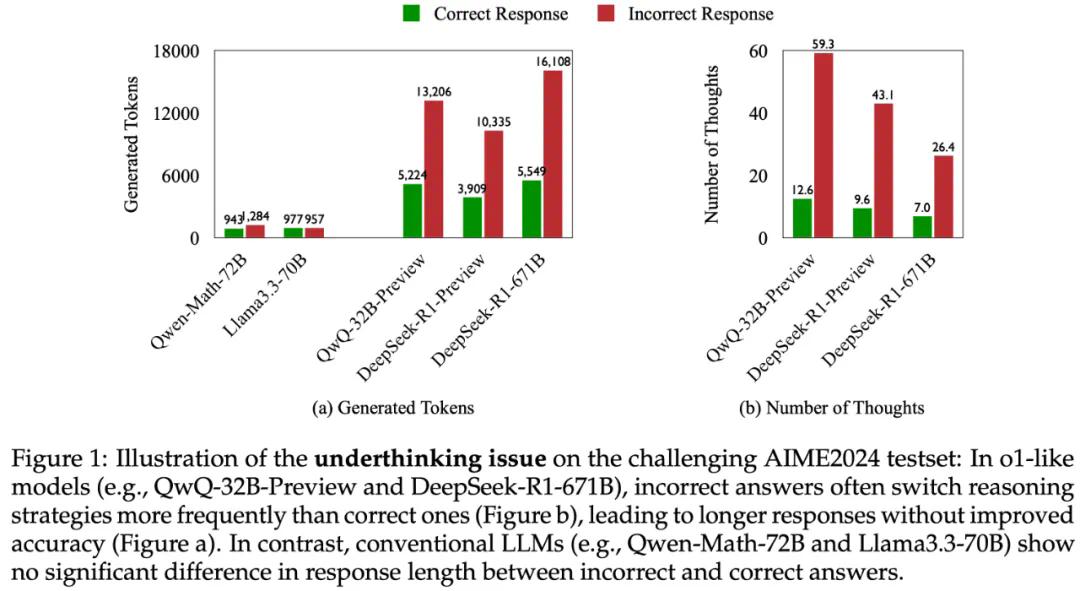
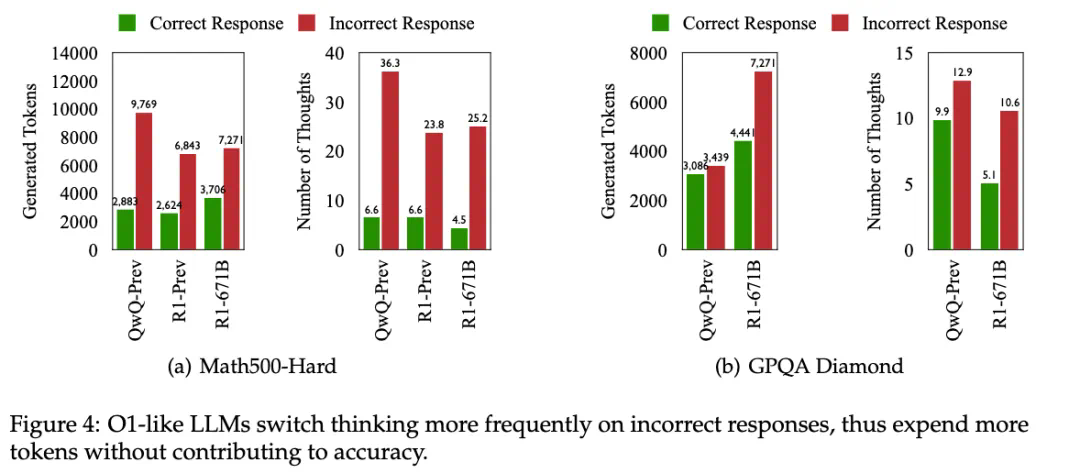
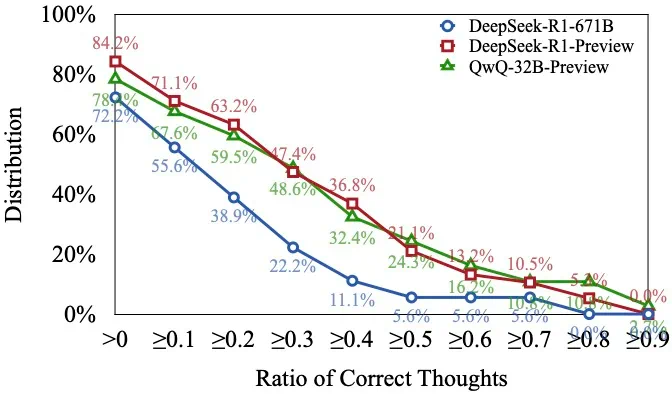
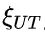
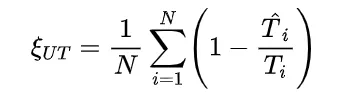
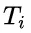
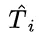
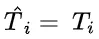
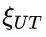
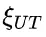
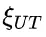
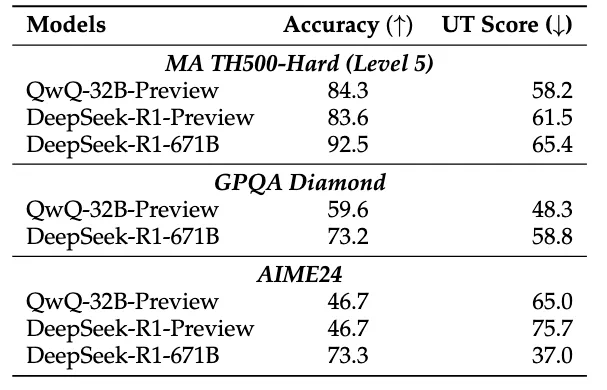
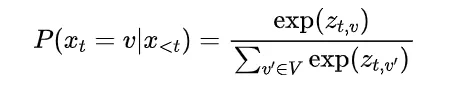
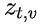
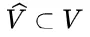

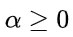
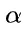
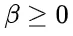
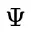
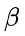
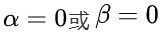
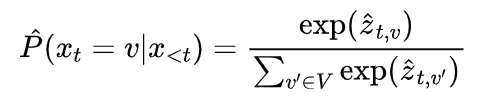
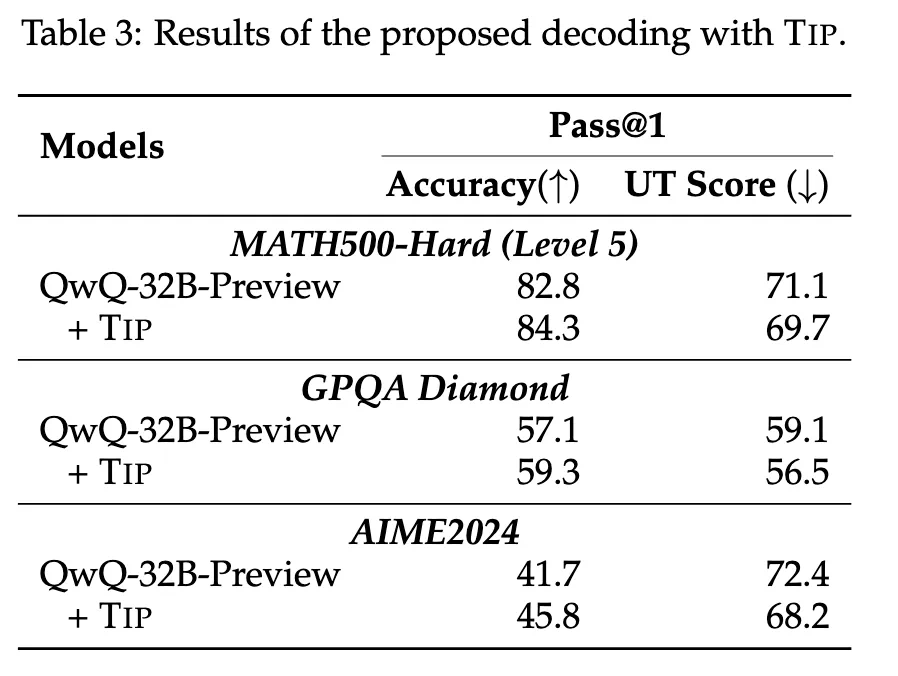
为解决这个问题,研究团队提出了一种名为“思路转换惩罚”(Thought Switching Penalty,TIP)的解码策略,通过惩罚思路切换行为来鼓励模型更深入地思考。实验结果表明,TIP策略能够有效提升模型的准确率并降低“思考不足”现象。 这项研究为改进长推理模型提供了新的思路和方法。
以上就是从想太多到想不透?DeepSeek-R1等长推理模型也存在「思考不足」问题的详细内容,更多请关注创想鸟其它相关文章!
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 chuangxiangniao@163.com 举报,一经查实,本站将立刻删除。
发布者:程序猿,转转请注明出处:https://www.chuangxiangniao.com/p/179365.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 



























