
北京大学aixcoder团队的代码大模型aixcoder-7b,在软件工程领域顶级会议icse 2025上发表论文,并将于4月27日至5月3日在加拿大渥太华分享研究成果。该模型将抽象语法树(ast)结构与大规模预训练相结合,提升了对代码结构和上下文的理解能力,并在企业应用中获得广泛认可。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

代码大模型训练的挑战与aiXcoder-7B的创新
训练代码大模型看似简单,但实际需要从实际开发场景出发。现有模型常将代码视为自然语言文本,忽略了代码的结构性和上下文关系。aiXcoder-7B则创新性地将软件工程方法融入大规模预训练中,主要体现在以下几个方面:
数据预处理: 利用软件工程工具,确保代码数据语法正确,并去除Bug、漏洞和敏感信息。这包括语法分析和静态分析,分别检测语法错误和潜在的运行时错误。

结构化FIM(Fill-in-the-middle): 基于AST结构组织预训练任务,而非简单的字符序列预测。这使得模型能够更好地学习代码的语法结构。
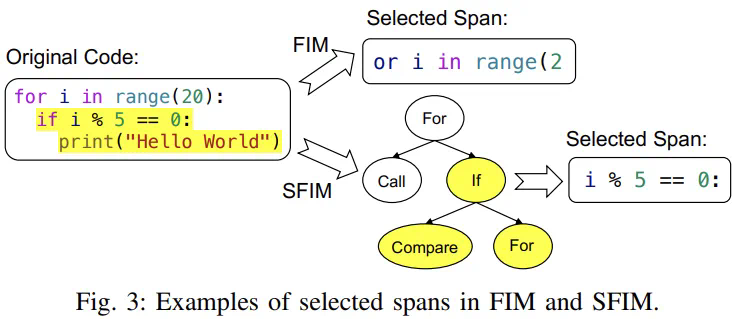
多文件排序: 以项目为单位组织数据,并根据文件内容相似性和依赖关系进行排序,提升模型对项目内多文件关系的理解。

aiXcoder-7B的优势与未来方向
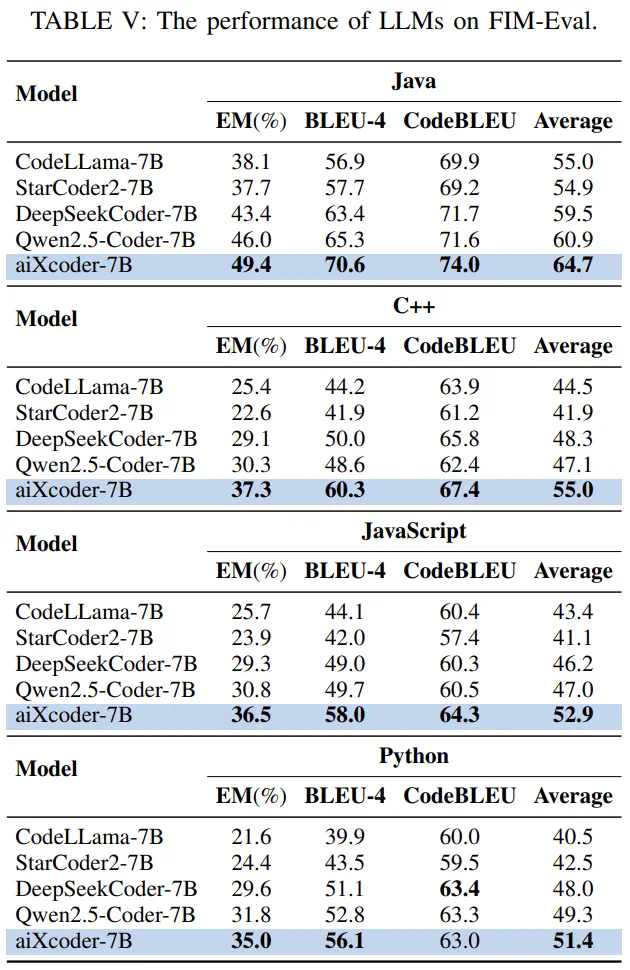
aiXcoder-7B在代码补全任务上展现出显著优势,尤其在处理不同代码结构和跨文件上下文方面。实验结果表明,其在多种语言的代码补全准确率和效率上均优于其他模型。
未来,团队将继续改进模型,以更好地处理复杂的代码上下文,提升代码补全的准确率和效率,最终实现软件开发的自动化。

论文地址:https://www.php.cn/link/4fa87f4ab207dc8c3e6126a0b7734d3c开源项目地址:https://www.php.cn/link/f69a675d7f12614552304ed2636e7044
以上就是如何训练最强代码大模型?北大aiXcoder-7B贡献前沿实践的详细内容,更多请关注创想鸟其它相关文章!
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 chuangxiangniao@163.com 举报,一经查实,本站将立刻删除。
发布者:程序猿,转转请注明出处:https://www.chuangxiangniao.com/p/179737.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 
























