
本文主要和大家讲述linux操作系统原理,这是一篇非常好的linux系统基础教程,我们总结了相关的全部精选内容,一起来学习下。希望能帮助到大家。
linux操作系统原理文字版
一.计算机经历的四个时代
1.第一代:
真空管计算机,输入和输出:穿孔卡片,对计算机操作起来非常不便,做一件事可能需要十几个人去共同去完成,年份大概是:1945-1955。而且耗电量特别大,如果那个时候你家里有台计算机的话,可能你一开计算机你家的电灯泡亮度就会变暗,哈哈~
2.第二代:
晶体管计算机,批处理(串行模式运行)系统出现。相比第一台省电多了。典型代表是Mainframe。年份大概是:1955-1965。在那个年代:Fortran语言也就诞生啦~一门非常古老的计算机语言。
3.第三代:
集成电路出现,多道处理程序(并行模式运行)设计,比较典型的代表就是:分时系统(把CPU的运算分成了时间片)。年份大概是:1965-1980年左右。
4.第四代:
PC机出现,大概是从:1980年左右。相信这个时代典型人物代表:比尔盖茨,乔布斯。
二.计算机的工作体系
虽然说计算机经过了四个时代的演变,但是到今天为止,计算机的工作体系还是比较简单的。一般而言,我们的计算机有五大基本部件。
1.MMU(内存控制单元,实现内存分页【memory page】)
运算机制被独立在CPU(计算控制单元)上,在CPU当中有一个独特的芯片叫MMU。他是用来计算进程的线线地址和物理地址的对应关系的。它还用于访问保护的,即一个进程先要访问到不是它的内存地址,是会被拒绝的!
2.存储器(memory)
3.显示设备(VGA接口,显示器等等)【属于IO设备】
4.输入设备(keyboard,键盘设备)【属于IO设备】
5.硬盘设备(Hard dish control ,硬盘控制器或适配器)【属于IO设备】
扩充小知识:
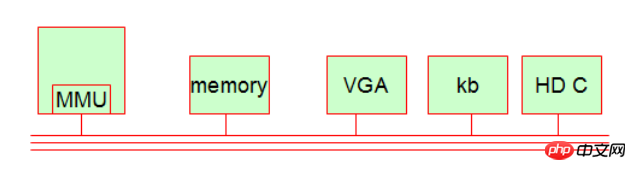
这些硬件设备在一条总线上链接,他们通过这条线进行数据交互,里面的带头大哥就是CPU,拥有最高指挥权。那么它是如何工作的呢?
A.取指单元(从内存中取得指令);
B.解码单元(完成解码[讲内存中取到的数据转换成CPU真正能运行的指令]);
C.执行单元(开始执行指令,根据指令的需求去调用不同的硬件去干活。);
我们通过上面知道了MMU是CPU的一部分,但是CPU有还要其他的部件吗?当然是有的啦,比如指令寄存器芯片,指令计数器芯片,堆栈指针。
指令寄存器芯片:就是CPU用于将内存中的数据取出来存放的地方;
指令计数器芯片:就是CPU为了记录上一次在内存中取数据的位置,方便下一次取值;
堆栈指针:CPU每次取完指令后,就会把堆栈指针指向下一个指令在内存中的位置。
他们的工作周期和CPU是一样快的速度,跟CPU的工作频率是在同一个时钟周期下,因此他的性能是非常好的,在CPU内部总线上完成数据通信。指令寄存器芯片,指令计数器芯片,堆栈指针。这些设备通常都被叫做CPU的寄存器。
寄存器其实就是用于保存现场的。尤其是在时间多路复用尤为明显。比如说CPU要被多个程序共享使用的时候,CPU经常会终止或挂起一个进程,操作系统必须要把它当时的运行状态给保存起来(方便CPU一会回来处理它的时候可以继续接着上次的状态干活。)然后继续运行其他进程(这叫计算机的上下文切换)。
三.计算机的存储体系。
1.对称多处理器SMP
CPU里面除了有MMU和寄存器(接近cpu的工作周期)等等,还有cpu核心,正是专门处理数据的,一颗CPU有多个核心,可以用于并行跑你的代码。工业上很多公司采用多颗CPU,这种结构我们称之为对称多处理器。
2.程序局部性原理
空间局部性:
程序是由指令和数据组成的。空间局部性指的是一个数据被访问到之后,那么离这个数据很近的其他数据随后也可能会被访问到。
时间局部性:
一般而言当一个程序执行完毕后,可能很快会被访问到。数据也是同样的原理,一个数据的被访问到,很可能会再次访问到。
正是因为程序局部性的存在,所以使得无论是在空间局部性或者时间的局部性的角度来考虑,一般而言我们都需要对数据做缓存。
扩充小知识:
由于CPU内部的寄存器存储的空间有限,于是就用了内存来存储数据,但是由于CPU和速度和内存的速度完全不在一个档次上,因此在处理的数据的时候回到多数都在等(CPU要在内存中取一个数据,cpu转一圈的时间就可以处理完,内存可能是需要转20圈)。为了解决使得效率更加提高,就出现了缓存这个概念。
既然我们知道了程序的局部性原理,有知道了CPU为了获得更多的空间其实就是用时间去换空间,但是缓存就是可以直接让cpu拿到数据,节省了时间,所以说缓存就是用空间去换时间
3.就算进存储体系
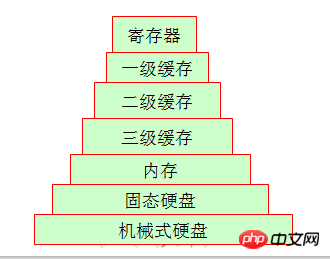
工作时间就的朋友可能见过磁带机,现在基本上都被OUT了,企业很多都用机硬盘来替代磁带机了,所以我们这里就从我们最熟悉的家用电脑的结构来说,存下到上一次存储数据是不一样。我们可以简单举个例子,他们的周存储周期是有很大差距的。尤为明显的是机械硬盘和内存,他们两个存取熟读差距是相当大的。
扩充小知识:
相比自己家用的台式机或是笔记本可能自己拆开过,讲过机械式硬盘,固态硬盘或是内存等等。但是可能你没有见过缓存物理设备,其实他是在CPU上的。因此我们对它的了解可能会有些盲区。
先说说一级缓存和耳机缓存吧,他们的CPU在这里面取数据的时候时间周期基本上查不了多少,因一级缓存和二级缓存都在CPU核心内部资源。(在其他硬件条件相同的情况下。一级缓存128k可能市场价格会买到300元左右,、一级缓存256k可能会买到600元左右,一级缓存512k可能市场价格就得过四位数这个具体价格可以参考京东啊。这足以说明缓存的造价是非常高的!)这个时候你可能会问那三级缓存呢?其实三级缓存就是就是多颗CPU共享的空间。当然多颗cpu也是共享内存的。
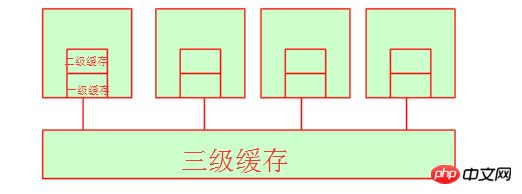
4.非一致性内存访问(NUMA)
我们知道当多颗cpu共享三级缓存或是内存的时候,他们就会出现了一个问题,即资源征用。我们知道变量或是字符串在内存中被保存是有内存地址的。他们是如何去领用内存地址呢?我们可以参考下图:
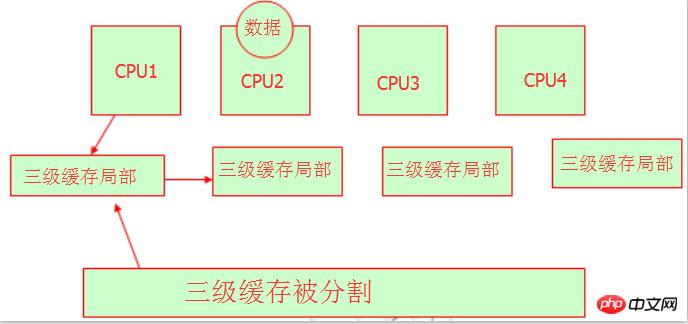
没错,这些玩硬件的大牛们将三级缓存分割,分别让不同的CPU占用不同的内存地址,这样我们可以理解他们都有自己的三级缓存区域,不会存在资源抢夺的问题,但是要注意的是他们还是同一块三级缓存。就好像北京市有朝阳区,丰台区,大兴区,海淀区等等,但是他们都是北京的所属地。我们可以这里理解。这就是NUMA,他的特性就是:非一致性内存访问,都有自己的内存空间。
扩展小知识:
那么问题来了,基于重新负载的结果,如果cpu1运行的进程被挂起,其地址在他自己的它的缓存地址是有记录的,但是当cpu2再次运行这个程序的时候被CPU2拿到的它是如何处理的呢?
这就没法了,只能从CPU1的三级换粗区域中复制一份地址过来一份或是移动过来一份让CPU2来处理,这个时候是需要一定时间的。所以说重新负载均衡会导致CPU性能降低。这个时候我们就可以用进程绑定来实现,让再次处理该进程的时候还是用之前处理的CPU来处理。即进程的CPU的亲缘性。
5.缓存中的通写和回写机制。
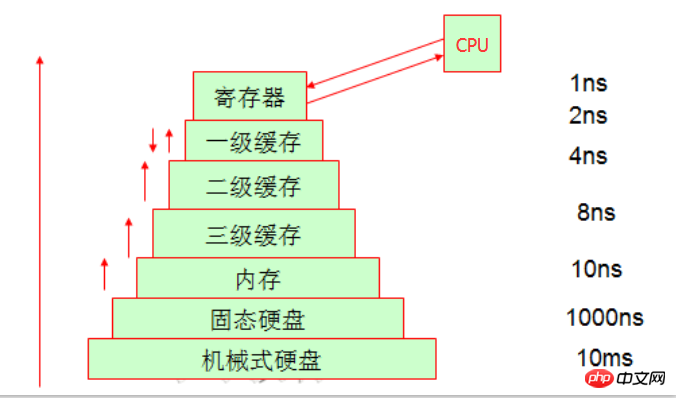
CPU在处理数据的地方就是在寄存器中修改,当寄存器没有要找的数据是,就会去一级缓存找,如果一级缓存中没有数据就会去二级缓存中找,依次查找知道从磁盘中找到,然后在加载到寄存器中。当三级缓存从内存中取数据发现三级缓存不足时,就会自动清理三级缓存的空间。
我们知道数据最终存放的位置是硬盘,这个存取过程是由操作系统来完成的。而我们CPU在处理数据是通过两种写入方式将数据写到不同的地方,那就是通写(写到内存中)和回写(写到一级缓存中)。很显然回写的性能好,但是如果断电的话就尴尬了,数据会丢失,因为他直接写到一级缓存中就完事了,但是一级缓存其他CPU是访问不到的,因此从可靠性的角度上来说通写方式会更靠谱。具体采用哪种方式得你自己按需而定啦。
四.IO设备
1.IO设备由设备控制器和设备本身组成。
设备控制器:集成在主板的一块芯片活一组芯片。负责从操作系统接收命令,并完成命令的执行。比如负责从操作系统中读取数据。
设备本身:其有自己的接口,但是设备本身的接口并不可用,它只是一个物理接口。如IDE接口。
扩展小知识:
每个控制器都有少量的用于通信的寄存器(几个到几十个不等)。这个寄存器是直接集成到设备控制器内部的。比方说,一个最小化的磁盘控制器,它也会用于指定磁盘地址,扇区计数,读写方向等相关操作请求的寄存器。所以任何时候想要激活控制器,设备驱动程序从操作系统中接收操作指令,然后将它转换成对应设备的基本操作,并把操作请求放置在寄存器中才能完成操作的。每个寄存器表现为一个IO端口。所有的寄存器组合称为设备的I/O地址空间,也叫I/O端口空间,
2.驱动程序
真正的硬件操作是由驱动程序操作完成的。驱动程序通常应该由设备生产上完成,通常驱动程序位于内核中,虽然驱动程序可以在内核外运行,但是很少有人这么玩,因为它太低效率啦!
3.实现输入和输出
设备的I/O端口没法事前分配,因为各个主板的型号不一致,所以我们需要做到动态指定。电脑在开机的时候,每个IO设备都要想总线的I/o端口空间注册使用I/O端口。这个动态端口是由所有的寄存器组合成为设备的I/O地址空间,有2^16次方个端口,即65535个端口。
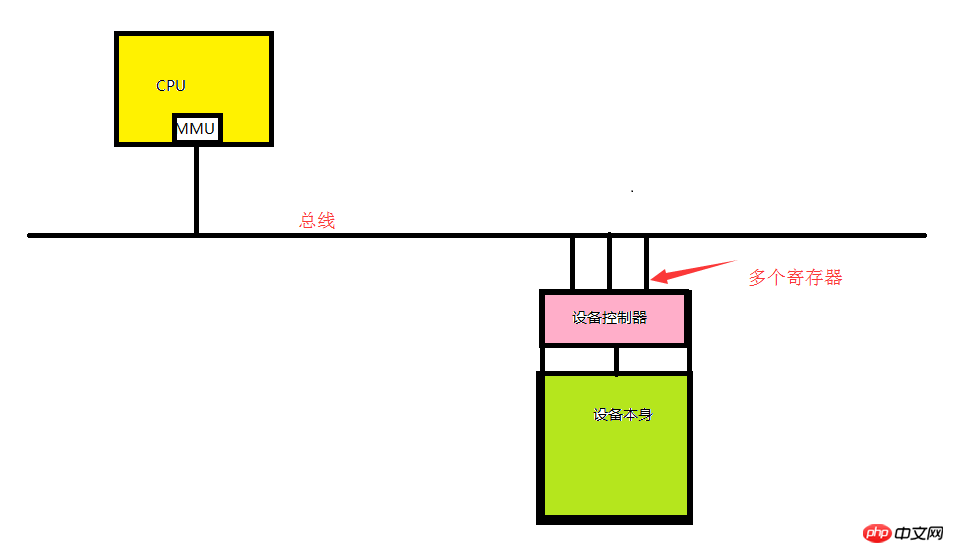
如上图所示,我们的CPU有要想跟指定设备打交道,就需要把指令传给驱动,然后驱动讲CPU的指令转换成设备能理解的信号放在寄存器中(也可以叫套接字,socket).所以说寄存器(I/O端口)是CPU通过总线和设备打交道的地址(I/O端口)。
扩展小知识:
三种方式实现I/O设备的输入和输出:
A..轮询:
通常指的是用户程序发起一个系统调用,内核将其翻译成一个内核对应驱动的过程调用,然后设备驱动程序启动I/O,并在一个连续循环不断中检查该设备,并看该设备是否完成了工作。这有点类似于忙等待(就是cpu会用固定周期不断通过遍历的方式去查看每一个I/O设备去查看是否有数据, 显然这种效率并不理想。),
B..中断:
中断CPU正在处理的程序,中断CPU正在执行的操作,从而通知内核来获取中断请求。在我们的主板通常有一个独特的设备,叫做可编程中断控制器。这个中断控制器可以通过某个针脚和CPU直接进行通信,能够出发CPU发生某个位置偏转,进而让CPU知道某个信号到达。中断控制器上会有一个中断向量(我们每一个I/O设备在启动时,要想中断控制器注册一个中断号,这个号通常是唯一的。通常中断向量的每一个针脚都是可以识别多个中断号的),也可以叫中断号。
因此当这个设备真正发生中断时,这个设备不会把数据直接放到总线上,这个设备会立即向中断控制器发出中断请求,中断控制器通过中断向量识别这个请求是哪个设备发来的,然后通过某种方式通知给CPU,让CPU知道具体哪个设备中断求情到达了。这个时候CPU可以根据设备注册使用I/O端口号,从而就能获取到设备的数据了。(注意,CPU是不能直接取数据的哟,因为他只是接收到了中断信号,它只能通知内核,让内核自己运行在CPU上,由内核来获取中断请求。)举个例子,一个网卡接收到外来IP的请求,网卡也有自己的缓存区,CPU讲网卡中的缓存拿到内存中进行去读,先判断是不是自己的IP,如果是就开始拆报文,最后会获取到一个端口号,然后CPIU在自己的中断控制器去找这个端口,并做相应的处理。
内核中断处理分为两步:中断上半部分(立即处理)和中断下半部分(不一定)。还是从网卡接收数据为例,当用户请求到达网卡时,CPU会命令讲网卡缓存区的数据直接拿到内存中来,也就是接收到数据后会立即处理(此处的处理就是将网卡的数据读到内存中而已,不做下一步处理,以方便以后处理的。),这个我们称之为中断的上半部分,而后来真正来处理这个请求的叫做下半部份
C.DMA:
直接内存访问,大家都知道数据的传输都是在总线上实现的,CPU是控制总线的使用者,在某一时刻到底是有哪个I/O设备使用总线是由CPU的控制器来决定的。总线有三个功能分别是:地址总线(完成对设备的寻址功能),控制总线(控制各个设备地址使用总线的功能)以及数据总线(实现数据传输)。
通常是I/O设备自带的一个具有智能型的控制芯片(我们称之为直接内存访问控制器),当需要处理中断上半部分时,CPU会告知DMA设备,接下来总线归DMA设备使用,并且告知其可以使用的内存空间,用于将I/O设备的数据读取到内存空间中去。当DMA的I/O设备将数据读取完成后,会发送消息告诉CPU以及完成了读取操作,这个时候CPU再回通知内核数据已经加载完毕,具体中断下半部分的处理就来交个内核处理了。现在大多数设备都是用DMA控制器的,比如:网卡,硬盘等等。
五.操作系统概念
通过上面的学习,我们知道了的计算机有五大基本部件。操作系统主要就是把这五个部件给它抽象为比较直观的接口,由上层程序员或者用户直接使用的。那事实上在操作系统中被抽象出来的东西又该是什么呢?
1.CPU(time slice)
在操作系统中,CPU被抽象成了时间片,而后将程序抽象成进程,通过分配时间片让程序运行起来。CPU有寻址单元用于来识别变量在内存的中所保存的集体内存地址。
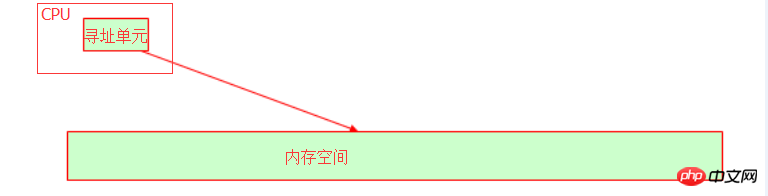
而我们主机内部的总线是取决于CPU的位宽(也叫字长),比如32bit的地址总线,它能表示2的32次方个内存地址,转换成10进制就是4G内存空间,这个时候你应该就明白为什么32位的操作系统中只能识别4G内存了吧?即使你的物理内存是16G,但是可用的还是4G,所以,你如果发现你的操作系统能识别4G以上的内存地址,那么你的操作系统一定就不是32位的啦!
2.内存(memory)
在操作系统中,内存的实现是通过虚拟地址空间来实现的。
3.I/O设备
在操作系统中,最核心的I/O设备就是磁盘,大家都知道磁盘是提供存储空间的,在内核中把它抽象成了文件。
4.进程
说白了,计算机存在的主要目的不就是运行程序吗?程序跑起来,我们统一叫进程(我们暂时不用理会线程)。那如果多个进程同时运行就意味着把这些有限的抽象资源(cpu,memory等等)分配给多个进程。我们把这些抽象资源统称为资源集。
资源集包括:
1>.cpu时间;
2>.内存地址:抽象成虚拟地址空间(如32位操作系统,支持4G空间,内核占用1G空间,进程也会默认自己有3G可用,事实上未必有3G空间,因为你的电脑可能会是小于4G的内存。)
3>.I/O:一切皆文件打开的多个文件,通过fd(文件描述符,file descriptor)打开指定的文件。我们把文件分为三类:正常文件、设备文件、管道文件。
每一个进行都有自己作业地址结构,即:task struct。其就是内核为每个进程维护的一个数据结构(一个数据结构就是用来保存数据的,说白了就是内存空间,记录着该进程所拥有的资源集,当然还有它的父进程,保存现场【用于进程切换】,内存映射等待)。task struct模拟出来了线性地址,让进程去使用这些线性地址,但是它会记录着线性地址和物理内存地址的映射关系的。
5.内存映射-页框
只要不是内核使用的物理内存空间我们称之为用户空间。内核会吧用户空间的物理内存切割成固定大小的页框(即page frame),欢聚话说,就是且更成一个固定大小的存储单位,比默认的单个存储单元(默认是一个字节,即8bit)要大.通常每4k一个存储单位。每一个页框作为一个独立的单元向外进行分配,且每一个页框也都其编号。【举个例子:假设有4G空间可用,每一个页框是4K,一共有1M个页框。】这些页框要分配给不同的进程使用。
我们假设你有4G内存,操作系统占用了1个G,剩余的3G物理内存分配给用户空间使用。每一进程启动之后,都会认为自己有3G空间可用,但是实际上它压根就用不完3G。进程进行写入内存是被离散存储的。哪有空余内存就往哪存取。具体的存取算法不要问我,我也没有研究过。
进程空间结构:
1>.预留空间
2>.栈(变量存放处)
3>.共享库
4>.堆(打开一个文件,文件中的数据流存放处)
5>.数据段(全局的静态变量存放处)
6>.代码段
进程和内存的存储关系如下:
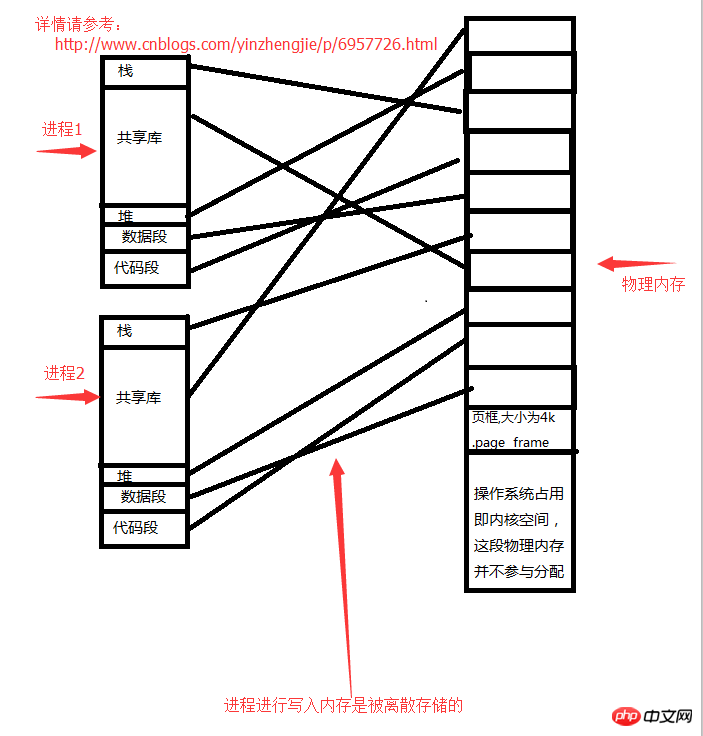
每个进程空间都有预留空间,当某个进程发现自己打开的数据已经不够用,它需要打开一个新文件(打开一个新文件就需要在进程的地址空间存放数据),很显然我们上图的进程地址空间是线性的并不是真正意义上的。当一个进程真正去申请使用一个内存时,需要向内核发起系统调用,由内核在物理内存上找一个物理空间,并告诉该进程可以使用的内存地址。比方说进程要在堆上打开一个文件,它需要向操作系统(内核)申请使用内存空间,且在物理内存允许的范围内(即请求的内存需要小于空闲物理内存),内核会分配给该进程内存地址。
每一进程都有自己想线性地址,这个地址是操作系统虚拟出来的,并不真实存在,它需要把这个虚拟地址和真正的物理内存做一个映射关系,如图“进程和内存的存储关系”,最终的进程数据的存放处位置还是映射到内存中了。这就意味着,当一个进行跑到CPU上执行时,它告诉CPU的是自己的线性地址,这时候CPU不会直接去找这个线性地址(因为线性地址是虚拟出来的,不真实存在,真正存放地址进程的是物理内存地址。),它会先去找这歌进程的“task struct”,并装载页表(page table)[记录着线性地址到物理内存的映射关系,每一个对应关系叫做一个页表项。],以读取到进程的所拥有的线性地址所对应的真正的物理内存地址。
扩展小知识:
CPU访问进程的地址时,首先获取到的是进程的线性地址,它将这个线性地址交给自己的芯片MMU进行计算,得到真正的物理内存地址,从而达到访问进程内存地址的目的。换句话说,只要他想要访问一个进程的内存地址,就必须经过MMU运算,这样导致效率很低,因此他们有引进了一个缓存,用于存放频繁访问的数据,这样就可以提高效率,不用MMU进行计算,直接拿到数据去处理就OK了,这个缓存器我们称之为:TLB:转换后援缓冲器(缓存页表的查询结果)
注意:在32bit的操作系统是线线地址到物理内存的映射。而在64bit操作系统是恰恰相反的!
6.用户态和内核态
操作系统运行时为了呢能够实现协调多任务,操作系统被分割成了2段,其中接近于硬件一段具有特权权限的叫做内核空间,而进程运行在用户空间当中。所以说,应用程序需要使用特权指令或是要访问硬件资源时需要系统调用。
只要是被开发成应用程序的,不是作为操作系统本身的一部分而存在的,我们称之为用户空间的程序。他们运行状态称之为用户态。
需要在内核(我们可以认为是操作系统)空间运行的程序,我们称之他们运行在内核空间,他们运行的状态为用户态,也叫核心态。注意:内核不负责完成具体工作。在内核空间可用执行任何特权操作。
每一个程序要想真正运行起来,它最终是向内核发起系统调用来完成的,或者有一部分的程序不需要内核的参与,有我们的应用程序就能完成。我们打个比方,你要计算2的32次方的结果,是否需要运行在内核态呢?答案是否定的,我们知道内核是不负责完成具体工作的,我们只是想要计算一个运算结果,也不需要调用任何的特权模式,因此,如果你写了一些关于计算数值的代码,只需要把这个代码交给CPU运行就可以了。
如果一个应用程序需要调用内核的功能而不是用户程序的功能的话,应用程序会发现自己需要做一个特权操作,而应用程序自身没有这个能力,应用程序会向内核发申请,让内核帮忙完成特权操作。内核发现应用程序是有权限使用特权指令的,内核会运行这些特权指令并把执行结果返回给应用程序,然后这个应用程序拿到特权指令的执行结果后,继续后续的代码。这就是模式转换。
因此一个程序员想要让你的程序具有生产力,就应该尽量让你的代码运行在用户空间,如果你的代码大多数都运行在内核空间的话,估计你的应用程序并不会给你打来太大的生产力哟。因为我们知道内核空间不负责产生生产力。
扩充小知识:
我们知道计算机的运行就是运行指定的。指令还分特权指令级别和非特权指令级别。了解过计算机的朋友可能知道X86的CPU架构大概分成了四个层次,由内之外共有四个环,被称为环0,环1,环2,环3。我们知道环0的都是特权指令,环3的都是用户指令。一般来讲,特权指令级别是指操作硬件,控制总线等等。
一个程序的执行,需要在内核的协调下,有可能在用户态和内核态互相切换,所以说一个程序的执行,一定是内核调度它到CPU上去执行的 。有些应用程序是操作系统运行过程当中,为了完成基本功能而运行的,我们就让他在后台自动运行,这叫守护进程。但是有的程序是用户需要的时候才运行的,那如何通知内核讲我们需要的应用程序运行起来呢?这个时候你就需要一个解释器,它能和操作系统打交道,能够发起指令的执行。说白了就是能够把用户需要的运行请求提交给内核,进而内核给它开放其运行所需要的有赖于的基本条件。从而程序就执行起来了。
相关推荐:
操作系统知识中关于线程的理解
Linux操作系统下CPU的中断
Linux操作系统安全加固的实例教程
以上就是linux操作系统原理基础的详细内容,更多请关注创想鸟其它相关文章!
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 chuangxiangniao@163.com 举报,一经查实,本站将立刻删除。
发布者:程序猿,转转请注明出处:https://www.chuangxiangniao.com/p/183258.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 

























