
以下是关于zfs和zpool的伪原创内容,保持了原文的结构和大意,同时进行了改写:
// 创建一个zpool$ modprobe zfs$ zpool create -f -m /sample sample -o ashift=12 /dev/sdc$ zfs create sample/fs1 -o mountpoint=/sample/fs1 -o atime=off -o canmount=on -o compression=lz4 -o quota=100G -o recordsize=8k -o logbias=throughput// 手动卸载和挂载$ umount /sample/fs1$ zfs mount sample/fs1
zpool和zfs参数获取:
// 获取zfs pool的默认参数$ zpool get all// 获取zfs pool挂载文件系统的参数$ zfs get all
zfs和内核之间的桥梁super_operations:
const struct super_operations zpl_super_operations = {.alloc_inode = zpl_inode_alloc,.destroy_inode = zpl_inode_destroy,.dirty_inode = zpl_dirty_inode,.write_inode = NULL,.evict_inode = zpl_evict_inode,.put_super = zpl_put_super,.sync_fs = zpl_sync_fs,.statfs = zpl_statfs,.remount_fs = zpl_remount_fs,.show_devname = zpl_show_devname,.show_options = zpl_show_options,.show_stats = NULL,};struct file_system_type zpl_fs_type = {.owner = THIS_MODULE,.name = ZFS_DRIVER,.mount = zpl_mount,.kill_sb = zpl_kill_sb,};
inode_operations:
extern const struct inode_operations zpl_inode_operations;extern const struct inode_operations zpl_dir_inode_operations;extern const struct inode_operations zpl_symlink_inode_operations;extern const struct inode_operations zpl_special_inode_operations;extern dentry_operations_t zpl_dentry_operations;extern const struct address_space_operations zpl_address_space_operations;extern const struct file_operations zpl_file_operations;extern const struct file_operations zpl_dir_file_operations;/ zpl_super.c /extern void zpl_prune_sb(int64_t nr_to_scan, void *arg);extern const struct super_operations zpl_super_operations;extern const struct export_operations zpl_export_operations;extern struct file_system_type zpl_fs_type;
const struct inode_operations zpl_inode_operations = {.setattr = zpl_setattr,.getattr = zpl_getattr,
ifdef HAVE_GENERIC_SETXATTR
.setxattr = generic_setxattr,.getxattr = generic_getxattr,.removexattr = generic_removexattr,endif
.listxattr = zpl_xattr_list,if defined(CONFIG_FS_POSIX_ACL)
if defined(HAVE_SET_ACL)
.set_acl = zpl_set_acl,endif / HAVE_SET_ACL /
.get_acl = zpl_get_acl,endif / CONFIG_FS_POSIX_ACL /
};
const struct inode_operations zpl_dir_inode_operations = {.create = zpl_create,.lookup = zpl_lookup,.link = zpl_link,.unlink = zpl_unlink,.symlink = zpl_symlink,.mkdir = zpl_mkdir,.rmdir = zpl_rmdir,.mknod = zpl_mknod,
if defined(HAVE_RENAME_WANTS_FLAGS) || defined(HAVE_IOPS_RENAME_USERNS)
.rename = zpl_rename2,else
.rename = zpl_rename,endif
ifdef HAVE_TMPFILE
.tmpfile = zpl_tmpfile,endif
.setattr = zpl_setattr,.getattr = zpl_getattr,ifdef HAVE_GENERIC_SETXATTR
.setxattr = generic_setxattr,.getxattr = generic_getxattr,.removexattr = generic_removexattr,endif
.listxattr = zpl_xattr_list,if defined(CONFIG_FS_POSIX_ACL)
if defined(HAVE_SET_ACL)
.set_acl = zpl_set_acl,endif / HAVE_SET_ACL /
.get_acl = zpl_get_acl,endif / CONFIG_FS_POSIX_ACL /
};
const struct inode_operations zpl_symlink_inode_operations = {
ifdef HAVE_GENERIC_READLINK
.readlink = generic_readlink,endif
if defined(HAVE_GET_LINK_DELAYED) || defined(HAVE_GET_LINK_COOKIE)
.get_link = zpl_get_link,elif defined(HAVE_FOLLOW_LINK_COOKIE) || defined(HAVE_FOLLOW_LINK_NAMEIDATA)
.follow_link = zpl_follow_link,endif
if defined(HAVE_PUT_LINK_COOKIE) || defined(HAVE_PUT_LINK_NAMEIDATA)
.put_link = zpl_put_link,endif
.setattr = zpl_setattr,.getattr = zpl_getattr,ifdef HAVE_GENERIC_SETXATTR
.setxattr = generic_setxattr,.getxattr = generic_getxattr,.removexattr = generic_removexattr,endif
.listxattr = zpl_xattr_list,};
const struct inode_operations zpl_special_inode_operations = {.setattr = zpl_setattr,.getattr = zpl_getattr,
ifdef HAVE_GENERIC_SETXATTR
.setxattr = generic_setxattr,.getxattr = generic_getxattr,.removexattr = generic_removexattr,endif
.listxattr = zpl_xattr_list,if defined(CONFIG_FS_POSIX_ACL)
if defined(HAVE_SET_ACL)
.set_acl = zpl_set_acl,endif / HAVE_SET_ACL /
.get_acl = zpl_get_acl,endif / CONFIG_FS_POSIX_ACL /
};
dentry_operations_t zpl_dentry_operations = {.d_revalidate = zpl_revalidate,};
file_operations:
extern const struct inode_operations zpl_inode_operations;extern const struct inode_operations zpl_dir_inode_operations;extern const struct inode_operations zpl_symlink_inode_operations;extern const struct inode_operations zpl_special_inode_operations;extern dentry_operations_t zpl_dentry_operations;extern const struct address_space_operations zpl_address_space_operations;extern const struct file_operations zpl_file_operations;extern const struct file_operations zpl_dir_file_operations;const struct address_space_operations zpl_address_space_operations = {.readpages = zpl_readpages,.readpage = zpl_readpage,.writepage = zpl_writepage,.writepages = zpl_writepages,.direct_IO = zpl_direct_IO,};
const struct file_operations zpl_file_operations = {.open = zpl_open,.release = zpl_release,.llseek = zpl_llseek,
ifdef HAVE_VFS_RW_ITERATE
ifdef HAVE_NEW_SYNC_READ
.read = new_sync_read,.write = new_sync_write,endif
.read_iter = zpl_iter_read,.write_iter = zpl_iter_write,ifdef HAVE_VFS_IOV_ITER
.splice_read = generic_file_splice_read,.splice_write = iter_file_splice_write,endif
else
.read = do_sync_read,.write = do_sync_write,.aio_read = zpl_aio_read,.aio_write = zpl_aio_write,endif
.mmap = zpl_mmap,.fsync = zpl_fsync,ifdef HAVE_FILE_AIO_FSYNC
.aio_fsync = zpl_aio_fsync,endif
.fallocate = zpl_fallocate,.unlocked_ioctl = zpl_ioctl,ifdef CONFIG_COMPAT
.compat_ioctl = zpl_compat_ioctl,endif
};
const struct file_operations zpl_dir_file_operations = {.llseek = generic_file_llseek,.read = generic_read_dir,
if defined(HAVE_VFS_ITERATE_SHARED)
.iterate_shared = zpl_iterate,elif defined(HAVE_VFS_ITERATE)
.iterate = zpl_iterate,else
.readdir = zpl_readdir,endif
.fsync = zpl_fsync,.unlocked_ioctl = zpl_ioctl,ifdef CONFIG_COMPAT
.compat_ioctl = zpl_compat_ioctl,endif
};
dentry_operations:
typedef const struct dentry_operations dentry_operations_t;dentry_operations_t zpl_dops_snapdirs = {/*
- 仅在2.6.37及更高版本的内核中支持快照的自动挂载。
- 在此之前,ops->follow_link() 回调被用作触发挂载的hack。
- 结果的vfsmount然后被明确地移植到名称空间中。
- 虽然可能添加兼容代码来实现这一点,但需要相当小心。*/.d_automount = zpl_snapdir_automount,.d_revalidate = zpl_snapdir_revalidate,};
dentry_operations_t zpl_dentry_operations = {.d_revalidate = zpl_revalidate,};
zfs io(zio) pipeline概述基本功能:
zio服务zfs的所有IO操作,负责将dva(数据虚拟地址)转换为硬件磁盘地址,通过vdevs提供动态压缩、去重、加密和校验等用户空间应用策略,实现镜像和raid z功能。
zfs文件写入过分分析:
zfs系统架构
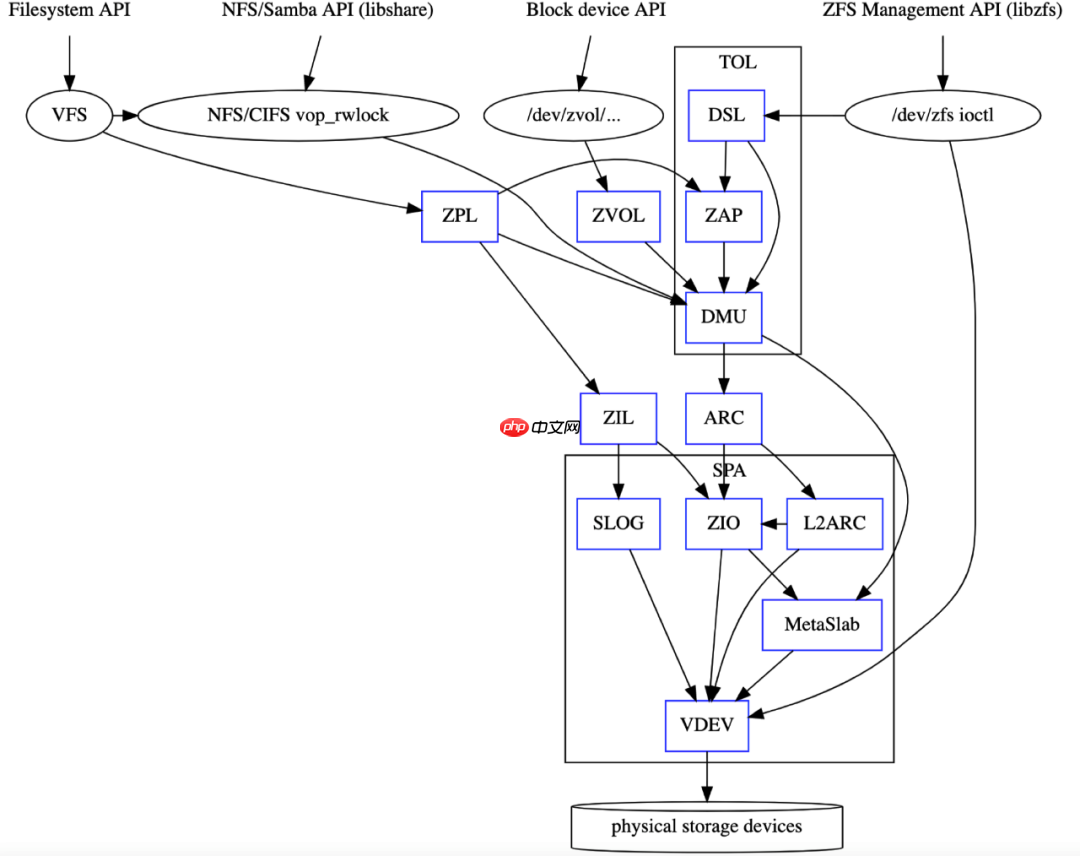
-------------------system calls---------------------------| |kernel +-------------------++-----------| VFS |------------+| File +-------------------+ || Systems | | || +-----------------------+ || | ZFS | | | || | +---------+ | || | | ZIO | | || | +---------+ | || | | vdevs | | || +------+---------+------+ || | | |+--------------------------------------------+| |+----------------+| block device |+----------------+| |+------------+| SCSI |+------------+| |+------------+| SAS |+------------+| |V |.-----------.-----------| disk |-----------
linux kernelsys_write:
当应用程序执行write函数时,会触发sys_write系统调用,具体的系统调用表可参考https://www.php.cn/link/1b7314ae41df37842b9d4e5e279caec1。
vfs_write:
vfs层提供统一的写接口,这里提供不同文件系统write的统一接口。
do_sync_write:
同步写接口。其中sys_write/vfs_write/do_sync_write是内核提供的抽象写接口,do_sync_write是内核4.x版本的函数,在5.x版本中是new_sync_write函数。不同版本的linux内核会导致部分系统函数存在差异。以下是参考linux kernel 5的内核代码分析:
// libc提供的write接口SYSCALL_DEFINE3(write, unsigned int, fd, const char __user *, buf, size_t, count) {return ksys_write(fd, buf, count);}// write函数的系统调用ssize_t ksys_write(unsigned int fd, const char __user *buf, size_t count) {ret = vfs_write(f.file, buf, count, ppos);return ret;}
// 调用实际文件系统的file的write_iter函数,到这里基本完成kernel内核层面的系统调用,接下来就是实际zfs的写函数static inline ssize_t call_write_iter(struct file file, struct kiocb kio, struct iov_iter iter) {// struct file 的f_op是struct file_operations 指针,这个指针保存每个实际文件系统的文件操作的函数,这里需要查看zfs对应的file_opertions函数操作表return file->f_op->write_iter(kio, iter);}
zfs kernel:
zfs写数据过程分为两个阶段:open context和sync context。
open context阶段通过系统调用将数据从用户态拷贝到zfs的缓冲区,同时zfs将这些脏数据缓存在DMU中;sync context阶段判断脏数据是否超过4G,如果超过则通过zio批量将数据刷新到磁盘。DMU将数据写入ZIO,在ARC中缓存特定数据,并通知DSL层追踪空间使用。
第一阶段open context阶段是从zfs_write开始。zfs_write分为一个block的全部写和部分写;整块写首先针对块加锁,然后读取,在更改的新数据关联新的buffer;如果是部分写,首先也是读取操作,更改block中的部分内容,标记为脏页。
// z_node代表zfs中的inode,zfs_uio_t 是偏移量和长度// 函数是经过省略的部分。int zfs_write(znode_t zp, zfs_uio_t uio, int ioflag, cred_t cr) {int error = 0;ssize_t start_resid = zfs_uio_resid(uio);ssize_t n = start_resid;if (n == 0)return (0);zfsvfs_t *zfsvfs = ZTOZSB(zp);const uint64_t max_blksz = zfsvfs->z_max_blksz;if (zfs_uio_prefaultpages(MIN(n, max_blksz), uio)) { ZFS_EXIT(zfsvfs); return (SET_ERROR(EFAULT));}const rlim64_t limit = MAXOFFSET_T;if (woff >= limit) { zfs_rangelock_exit(lr); ZFS_EXIT(zfsvfs); return (SET_ERROR(EFBIG));}if (n > limit - woff) n = limit - woff;uint64_t end_size = MAX(zp->z_size, woff + n);zilog_t *zilog = zfsvfs->z_log;// 文件分割为多个文件chunkwhile (n > 0) { woff = zfs_uio_offset(uio); arc_buf_t *abuf = NULL; if (n >= max_blksz && woff >= zp->z_size && P2PHASE(woff, max_blksz) == 0 && zp->z_blksz == max_blksz) { size_t cbytes; abuf = dmu_request_arcbuf(sa_get_db(zp->z_sa_hdl), max_blksz); if ((error = zfs_uiocopy(abuf->b_data, max_blksz, UIO_WRITE, uio, &cbytes))) { dmu_return_arcbuf(abuf); break; } ASSERT3S(cbytes, ==, max_blksz); // 创建一个事务,表示准备更改操作,是否有空闲的空间 dmu_tx_t *tx = dmu_tx_create(zfsvfs->z_os); dmu_tx_hold_sa(tx, zp->z_sa_hdl, B_FALSE); dmu_buf_impl_t *db = (dmu_buf_impl_t *)sa_get_db(zp->z_sa_hdl); DB_DNODE_ENTER(db); dmu_tx_hold_write_by_dnode(tx, DB_DNODE(db), woff, MIN(n, max_blksz)); // 等到喜爱一个可用的事务组,检查是否有足够空间和内存 error = dmu_tx_assign(tx, TXG_WAIT) { dmu_tx_wait(tx) { dmu_tx_delay(tx, dirty); } } if (error) { dmu_tx_abort(tx); if (abuf != NULL) dmu_return_arcbuf(abuf); break; } if (lr->lr_length == UINT64_MAX) { uint64_t new_blksz; if (zp->z_blksz > max_blksz) { new_blksz = MIN(end_size, zp->z_blksz)); } else { new_blksz = MIN(end_size, max_blksz); } zfs_grow_blocksize(zp, new_blksz, tx); zfs_rangelock_reduce(lr, woff, n); } const ssize_t nbytes = MIN(n, max_blksz - P2PHASE(woff, max_blksz)); ssize_t tx_bytes; if (abuf == NULL) { tx_bytes = zfs_uio_resid(uio); zfs_uio_fault_disable(uio, B_TRUE); // 数据从uio写入到DMU error = dmu_write_uio_dbuf(sa_get_db(zp->z_sa_hdl), uio, nbytes, tx); zfs_uio_fault_disable(uio, B_FALSE);
ifdef linux
if (error == EFAULT) { dmu_tx_commit(tx); if (tx_bytes != zfs_uio_resid(uio)) n -= tx_bytes - zfs_uio_resid(uio); if (zfs_uio_prefaultpages(MIN(n, max_blksz), uio)) { break; } continue; }
endif
if (error != 0) { dmu_tx_commit(tx); break; } tx_bytes -= zfs_uio_resid(uio); } else { error = dmu_assign_arcbuf_by_dbuf(sa_get_db(zp->z_sa_hdl), woff, abuf, tx) { dmu_assign_arcbuf_by_dnode(DB_DNODE(dbuf), offset, buf, tx) { dbuf_assign_arcbuf(db, buf, tx) { // 标记脏的dbuf (void) dbuf_dirty(db, tx); } } } if (error != 0) { dmu_return_arcbuf(abuf); dmu_tx_commit(tx); break; } } error = sa_bulk_update(zp->z_sa_hdl, bulk, count, tx); // zfs log写入 zfs_log_write(zilog, tx, TX_WRITE, zp, woff, tx_bytes, ioflag, NULL, NULL); dmu_tx_commit(tx); } if (ioflag & (O_SYNC | O_DSYNC) || zfsvfs->z_os->os_sync == ZFS_SYNC_ALWAYS) // zfs intent log写入,更改数据写到磁盘之前必须先保证日志罗盘 zil_commit(zilog, zp->z_id); ZFS_EXIT(zfsvfs); return (0);}
}
第二个阶段是sync context阶段,zfs会启动内核线程来同步事务组,然后进入dsl层的同步,在进入DMU层的同步,最后是ZIO的pipeline:
void txg_sync_start(dsl_pool_t dp) {tx->tx_sync_thread = thread_create(NULL, 0, txg_sync_thread, 0) {static void txg_sync_thread(void arg) {for (;;) {clock_t timeout = zfs_txg_timeout * hz;spa_sync(spa, txg);// 找到脏的数据集,call dsl_datasetsync->dmu_objset_sync->zio pipelinetxg_dispatch_callbacks(dp, txg);}}}}
以上就是聊聊zfs中的write的详细内容,更多请关注创想鸟其它相关文章!
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 chuangxiangniao@163.com 举报,一经查实,本站将立刻删除。
发布者:程序猿,转转请注明出处:https://www.chuangxiangniao.com/p/18586.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 



























