google deepmind 和 google research 联合发表的论文提出了一种名为 infalign (推理感知型对齐) 的新框架,旨在优化生成式语言模型在特定推理过程下的胜率。 传统的 kl 正则化强化学习 (kl-rl) 方法通常忽略推理阶段,导致训练目标与实际应用脱节。infalign 则直接针对推理时间胜率进行优化。
该论文指出,直接优化推理时间胜率非常困难,但可以通过巧妙地设计奖励函数来实现。InfAlign 的核心思想是:设计一个新的奖励函数 R,该函数基于原始奖励模型 r、推理过程 T 和参考策略 π_ref。通过求解带有变换后奖励 R 的 KL-RL 问题,InfAlign 能够有效地逼近最优解,从而最大化推理时间胜率。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

论文中给出了一个数学框架,证明了对于特定类型的语言模型(δ 限定模型),存在一个最优的奖励变换 R,能够将推理时间胜率优化问题转化为一个可解的 KL-RL 问题。 该框架的核心是一个耦合方程组,描述了最优策略和变换后奖励之间的关系。
然而,直接求解该方程组在计算上存在挑战。因此,论文提出了一种更实用的方法:CTRL (校准和变换式强化学习)。CTRL 算法包含三个步骤:奖励校准、奖励变换和标准 KL-RL 求解。 论文中详细介绍了如何通过经验校准和分位数方法来近似计算校准奖励,以及如何选择合适的奖励变换函数 Φ 来优化不同推理过程(例如 best-of-N 和 worst-of-N)下的胜率。
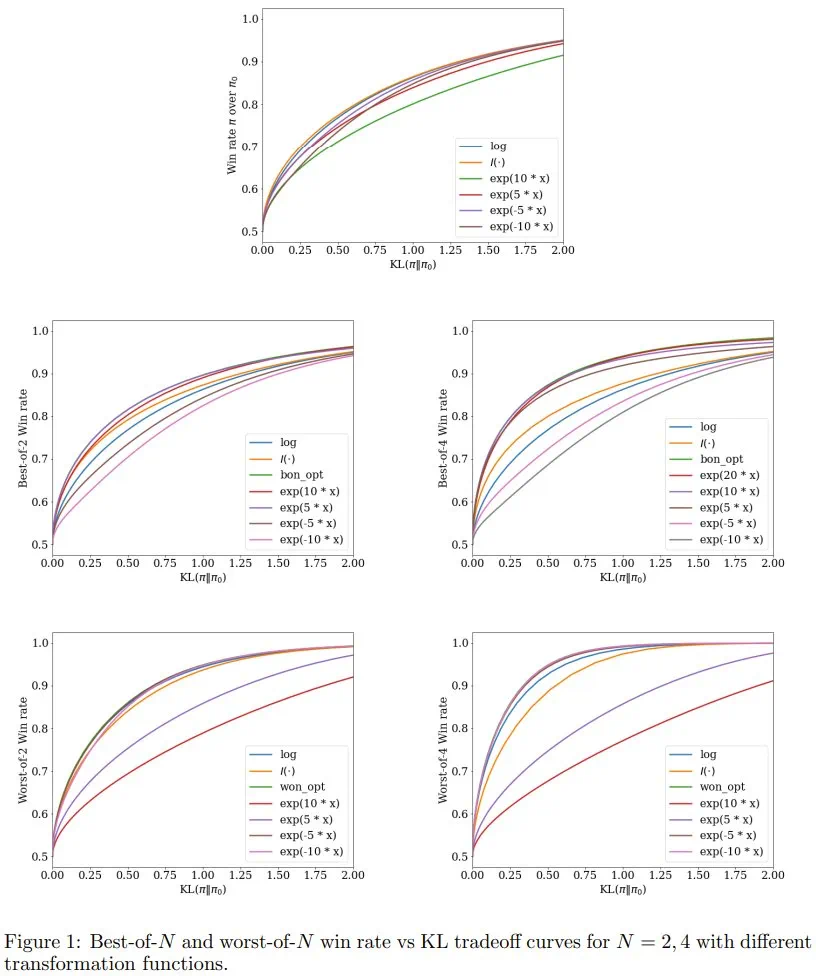
实验结果表明,InfAlign 框架和 CTRL 算法能够显著提升语言模型在 best-of-N 和 worst-of-N 推理过程下的胜率,并且相比于传统的 KL-RL 方法具有更好的胜率-KL 散度权衡。 特别是,论文发现奖励模型通常没有正确校准,而经过校准的奖励能够显著提高模型的性能。 论文还探讨了不同奖励变换函数的有效性,并为 best-of-N 和 worst-of-N 过程推荐了最佳的变换函数。
论文地址:https://www.php.cn/link/7fb15019103809d7311d26d2e8bb47ed
以上就是执行推理时能对齐语言模型吗?谷歌InfAlign带来一种对齐新思路的详细内容,更多请关注创想鸟其它相关文章!
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 chuangxiangniao@163.com 举报,一经查实,本站将立刻删除。
发布者:程序猿,转转请注明出处:https://www.chuangxiangniao.com/p/188598.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫