
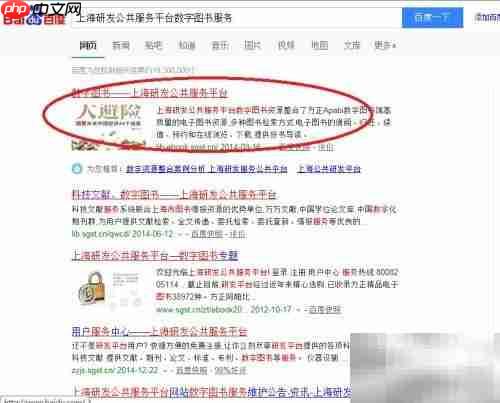
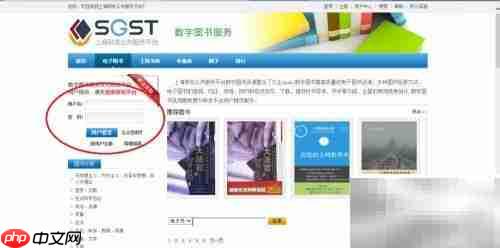
首先,访问上海研发公共服务平台的数字图书服务页面,进入官网后可开始查找所需电子资源。
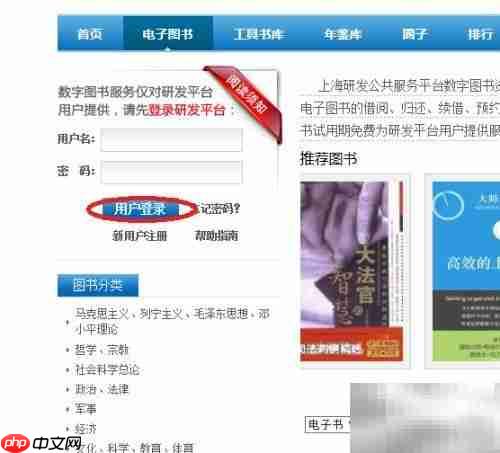
登录时需在页面右上角填写已注册的账号和密码。若尚未注册,需先前往上海市研发公共服务平台完成用户注册,具体步骤可参考百度经验中关于该平台账号注册的相关教程。
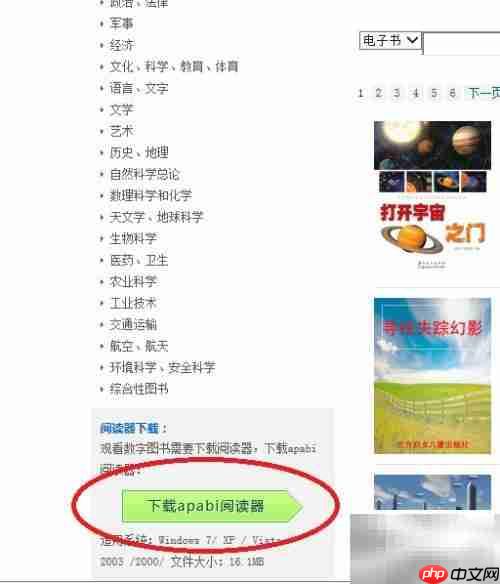
登录成功后,在网页左下角下载Apabi阅读器,并将其安装到个人计算机上,以便后续阅读使用。
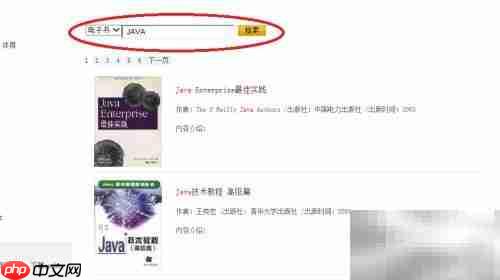
安装完成后,在搜索框中输入想阅读的书籍名称,例如“Java”,然后点击查询按钮进行检索。
接下来可以浏览搜索结果,选择感兴趣的图书查看其详细信息,包括作者、出版时间、内容简介等。
如果对某本书籍感兴趣,点击“在线阅读”即可立即开始阅读,享受流畅的正版电子书体验。

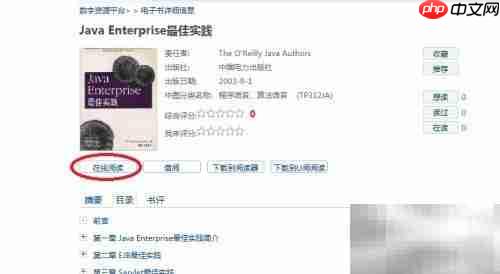
借阅成功后,还可将图书下载至本地,通过Apabi阅读器实现离线阅读,方便随时随地学习提升。
以上就是毕业后高效利用电子书库的详细内容,更多请关注创想鸟其它相关文章!
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 chuangxiangniao@163.com 举报,一经查实,本站将立刻删除。
发布者:程序猿,转转请注明出处:https://www.chuangxiangniao.com/p/190734.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 





















