
阿里云通义千问团队在最新论文中揭示了混合专家模型(moe)训练中的一个关键问题,并提出了一种创新的解决方案。该问题在于现有moe训练框架普遍采用局部负载均衡损失(lbl),导致专家激活不均衡,限制了模型性能和专家特异性。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

该团队提出的方法通过轻量级通信机制,将局部负载均衡提升为全局负载均衡。这使得模型能够更好地利用数据多样性,从而提高专家特异化程度和整体模型性能。
 – 论文:《Demons in the Detail: On Implementing Load Balancing Loss for Training Specialized Mixture-of-Expert Models》
– 论文:《Demons in the Detail: On Implementing Load Balancing Loss for Training Specialized Mixture-of-Expert Models》
论文链接:https://www.php.cn/link/b294fccdfe95bc7f7dd813216a821a76
立即进入“豆包AI人工智官网入口”;
立即学习“豆包AI人工智能在线问答入口”;
MoE训练中的挑战与解决方案
MoE通过路由机制动态激活模型参数,提升了模型容量。然而,基于TopK的稀疏激活容易导致专家激活不均衡,少数专家被过度利用,其余专家资源浪费。为此,通常引入LBL来平衡专家激活。
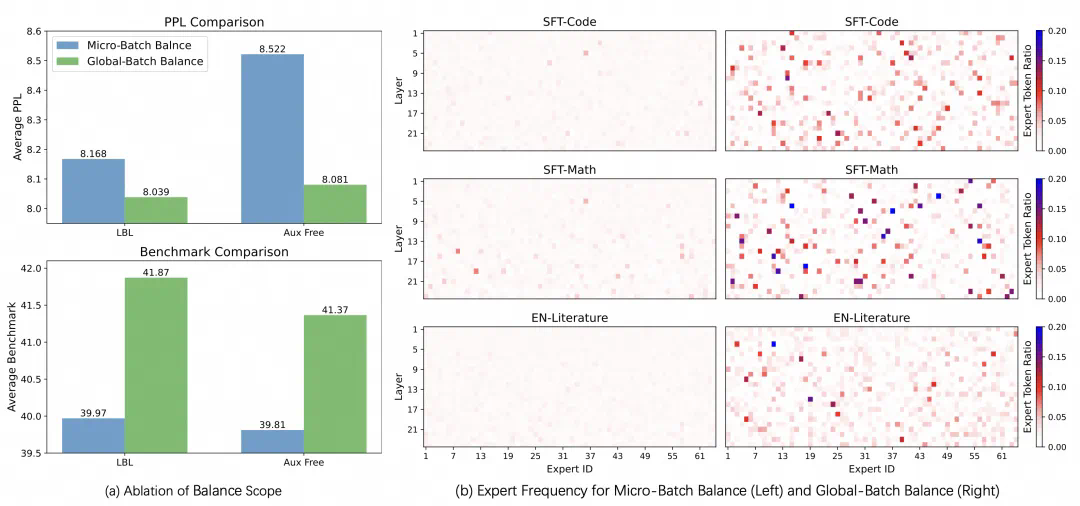
现有框架的LBL通常在局部(mini-batch)层面计算,这在mini-batch数据缺乏多样性时会限制专家特异化。 阿里云团队的方案通过跨mini-batch同步专家激活频率,实现全局LBL计算,有效解决了这个问题。
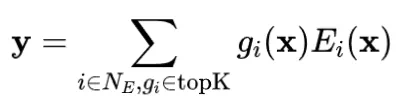
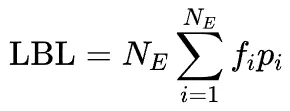
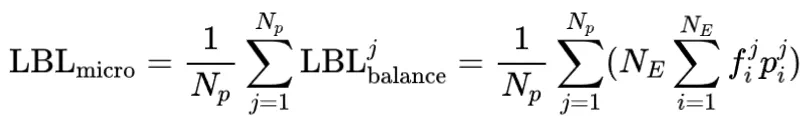
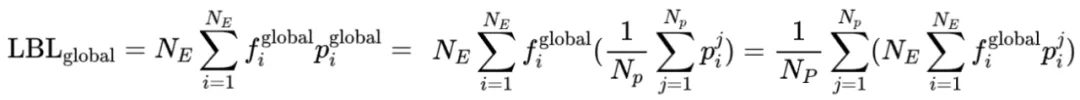
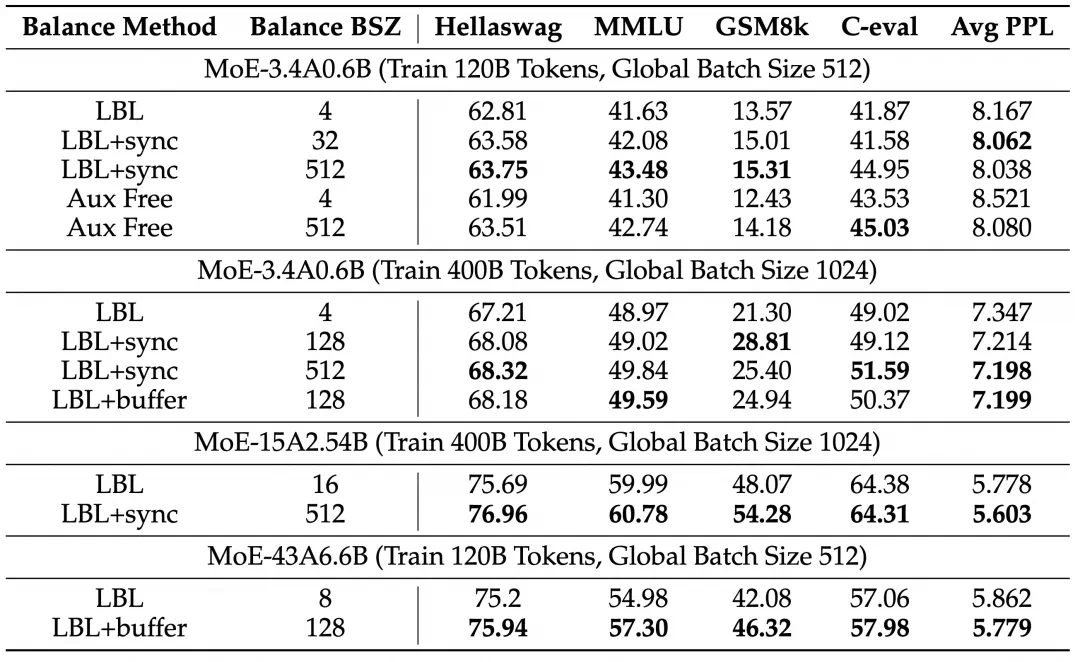
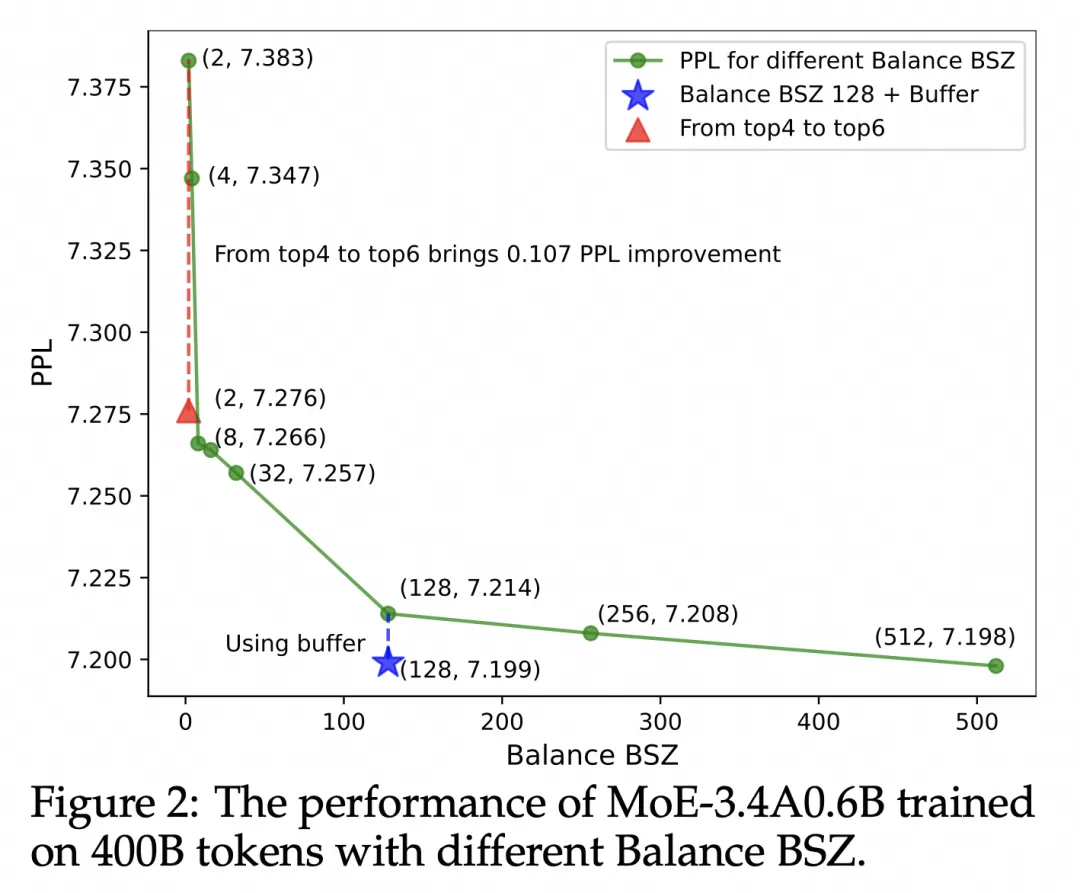
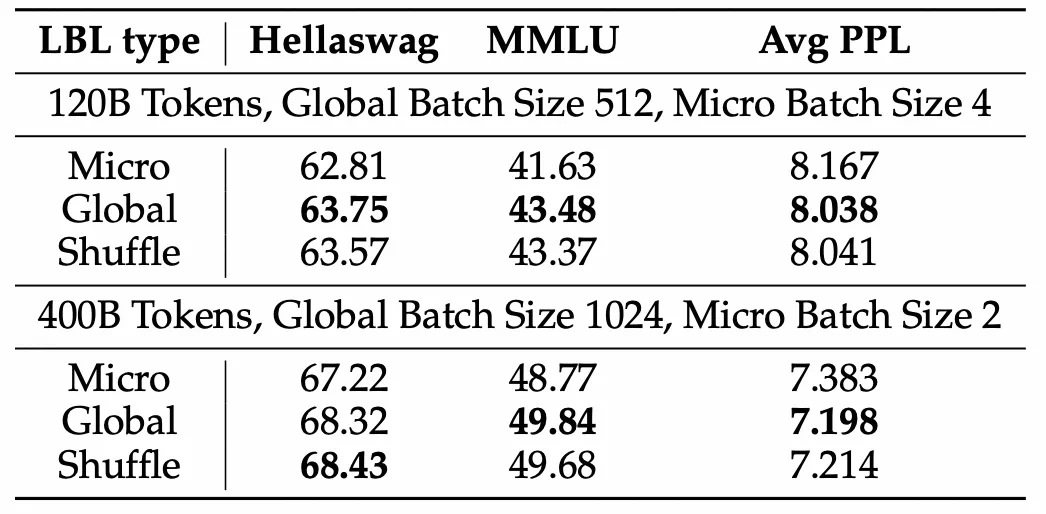
实验结果表明,该方法显著提升了模型性能和专家特异性,尤其是在大规模模型训练中效果明显。 此外,研究还发现,添加少量局部LBL可以进一步提高训练效率,而不会显著影响模型性能。
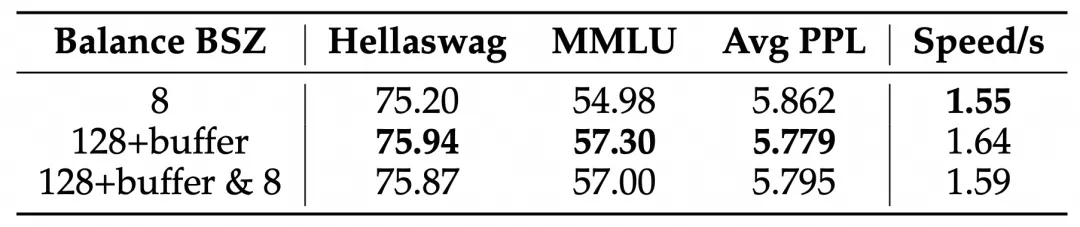
这项研究为MoE模型的训练提供了新的思路,有助于构建更高效、更可解释的大规模模型。 虽然实验主要集中在语言模型领域,但其方法具有广泛的应用前景。
以上就是阿里云通义大模型新技术:MoE模型训练专家平衡的关键细节的详细内容,更多请关注创想鸟其它相关文章!
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 chuangxiangniao@163.com 举报,一经查实,本站将立刻删除。
发布者:程序猿,转转请注明出处:https://www.chuangxiangniao.com/p/191111.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 
























