
mysql教程栏目介绍执行计划explain与索引数据结构

准备工作
先建好数据库表,演示用的MySQL表,建表语句:
CREATE TABLE `emp` ( `id` int(11) NOT NULL AUTO_INCREMENT COMMENT '主键', `empno` int(11) DEFAULT NULL COMMENT '雇员工号', `ename` varchar(255) DEFAULT NULL COMMENT '雇员姓名', `job` varchar(255) DEFAULT NULL COMMENT '工作', `mgr` varchar(255) DEFAULT NULL COMMENT '经理的工号', `hiredate` date DEFAULT NULL COMMENT '雇用日期', `sal` double DEFAULT NULL COMMENT '工资', `comm` double DEFAULT NULL COMMENT '津贴', `deptno` int(11) DEFAULT NULL COMMENT '所属部门号', PRIMARY KEY (`id`) USING BTREE) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='雇员表';CREATE TABLE `dept` ( `id` int(11) NOT NULL AUTO_INCREMENT COMMENT '主键', `deptno` int(11) DEFAULT NULL COMMENT '部门号', `dname` varchar(255) DEFAULT NULL COMMENT '部门名称', `loc` varchar(255) DEFAULT NULL COMMENT '地址', PRIMARY KEY (`id`) USING BTREE) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='部门表';CREATE TABLE `salgrade` ( `id` int(11) NOT NULL COMMENT '主键', `grade` varchar(255) DEFAULT NULL COMMENT '等级', `lowsal` varchar(255) DEFAULT NULL COMMENT '最低工资', `hisal` varchar(255) DEFAULT NULL COMMENT '最高工资', PRIMARY KEY (`id`)) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='工资等级表';CREATE TABLE `bonus` ( `id` int(11) NOT NULL COMMENT '主键', `ename` varchar(255) DEFAULT NULL COMMENT '雇员姓名', `job` varchar(255) DEFAULT NULL COMMENT '工作', `sal` double DEFAULT NULL COMMENT '工资', `comm` double DEFAULT NULL COMMENT '津贴', PRIMARY KEY (`id`)) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='奖金表';复制代码
后续执行计划,查询优化,索引优化等等知识的演练,基于以上几个表来操作。
MySQL执行计划
要进行SQL调优,你得知道要调优的SQL语句是怎么执行的,查看SQL语句的具体执行过程,以加快SQL语句的执行效率。
可以使用explain + SQL语句来模拟优化器执行SQL查询语句,从而知道MySQL是如何处理SQL语句的。
关于explain可以看看官网介绍。
explain的输出格式
mysql> explain select * from emp;+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+-------+| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+-------+| 1 | SIMPLE | emp | NULL | ALL | NULL | NULL | NULL | NULL | 1 | 100.00 | NULL |+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+-------+复制代码
字段id,select_type等字段的解释:
idThe SELECT identifier(该SELECT标识符)select_typeThe SELECT type(该SELECT类型)tableThe table for the output row(输出该行的表名)partitionsThe matching partitions(匹配的分区)typeThe join type(连接类型)possible_keysThe possible indexes to choose(可能的索引选择)keyThe index actually chosen(实际选择的索引)key_lenThe length of the chosen key(所选键的长度)refThe columns compared to the index(与索引比较的列)rowsEstimate of rows to be examined(检查的预估行数)filteredPercentage of rows filtered by table condition(按表条件过滤的行百分比)extraAdditional information(附加信息)
id
select查询的序列号,包含一组数字,表示查询中执行select子句或者操作表的顺序。
id号分为三类:
如果id相同,那么执行顺序从上到下
mysql> explain select * from emp e join dept d on e.deptno = d.deptno join salgrade sg on e.sal between sg.lowsal and sg.hisal;+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+----------------------------------------------------+| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+----------------------------------------------------+| 1 | SIMPLE | e | NULL | ALL | NULL | NULL | NULL | NULL | 1 | 100.00 | NULL || 1 | SIMPLE | d | NULL | ALL | NULL | NULL | NULL | NULL | 1 | 100.00 | Using where; Using join buffer (Block Nested Loop) || 1 | SIMPLE | sg | NULL | ALL | NULL | NULL | NULL | NULL | 1 | 100.00 | Using where; Using join buffer (Block Nested Loop) |+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+----------------------------------------------------+复制代码
这个查询,用explain执行一下,
id序号都是1,那么MySQL的执行顺序就是从上到下执行的。
如果id不同,如果是子查询,id的序号会递增,id值越大优先级越高,越先被执行
mysql> explain select * from emp e where e.deptno in (select d.deptno from dept d where d.dname = 'SALEDept');+----+--------------+-------------+------------+------+---------------+------+---------+------+------+----------+----------------------------------------------------+| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |+----+--------------+-------------+------------+------+---------------+------+---------+------+------+----------+----------------------------------------------------+| 1 | SIMPLE | | NULL | ALL | NULL | NULL | NULL | NULL | NULL | 100.00 | NULL || 1 | SIMPLE | e | NULL | ALL | NULL | NULL | NULL | NULL | 2 | 50.00 | Using where; Using join buffer (Block Nested Loop) || 2 | MATERIALIZED | d | NULL | ALL | NULL | NULL | NULL | NULL | 1 | 100.00 | Using where |+----+--------------+-------------+------------+------+---------------+------+---------+------+------+----------+----------------------------------------------------+复制代码
这个例子的执行顺序是先执行
id为2的,然后执行id为1的。
id相同和不同的,同时存在:相同的可以认为是一组,从上往下顺序执行,在所有组中,id值越大,优先级越高,越先执行
还是上面那个例子,先执行
id为2的,然后按顺序从上往下执行id为1的。
select_type
主要用来分辨查询的类型,是普通查询还是联合查询还是子查询。
select_type ValueSIMPLENoneSimple SELECT (not using UNION or subqueries)PRIMARYNoneOutermost SELECTUNIONNoneSecond or later SELECT statement in a UNIONDEPENDENT UNIONdependent (true)Second or later SELECT statement in a UNION, dependent on outer queryUNION RESULTunion_resultResult of a UNION.SUBQUERYNoneFirst SELECT in subqueryDEPENDENT SUBQUERYdependent (true)First SELECT in subquery, dependent on outer queryDERIVEDNoneDerived tableMATERIALIZEDmaterialized_from_subqueryMaterialized subqueryUNCACHEABLE SUBQUERYcacheable (false)A subquery for which the result cannot be cached and must be re-evaluated for each row of the outer queryUNCACHEABLE UNIONcacheable (false)The second or later select in a UNION that belongs to an uncacheable subquery (see UNCACHEABLE SUBQUERY)SIMPLE 简单的查询,不包含子查询和union
mysql> explain select * from emp;+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+-------+| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+-------+| 1 | SIMPLE | emp | NULL | ALL | NULL | NULL | NULL | NULL | 3 | 100.00 | NULL |+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+-------+复制代码
primary 查询中若包含任何复杂的子查询,最外层查询则被标记为Primaryunion 若第二个select出现在union之后,则被标记为union
mysql> explain select * from emp where deptno = 1001 union select * from emp where sal < 5000;+----+--------------+------------+------------+------+---------------+------+---------+------+------+----------+-----------------+| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |+----+--------------+------------+------------+------+---------------+------+---------+------+------+----------+-----------------+| 1 | PRIMARY | emp | NULL | ALL | NULL | NULL | NULL | NULL | 4 | 25.00 | Using where || 2 | UNION | emp | NULL | ALL | NULL | NULL | NULL | NULL | 4 | 33.33 | Using where || NULL | UNION RESULT | | NULL | ALL | NULL | NULL | NULL | NULL | NULL | NULL | Using temporary |+----+--------------+------------+------------+------+---------------+------+---------+------+------+----------+-----------------+复制代码
这条语句的select_type包含了primary和union
dependent union 跟union类似,此处的depentent表示union或union all联合而成的结果会受外部表影响union result 从union表获取结果的selectdependent subquery subquery的子查询要受到外部表查询的影响
mysql> explain select * from emp e where e.empno in ( select empno from emp where deptno = 1001 union select empno from emp where sal < 5000);+----+--------------------+------------+------------+------+---------------+------+---------+------+------+----------+-----------------+| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |+----+--------------------+------------+------------+------+---------------+------+---------+------+------+----------+-----------------+| 1 | PRIMARY | e | NULL | ALL | NULL | NULL | NULL | NULL | 4 | 100.00 | Using where || 2 | DEPENDENT SUBQUERY | emp | NULL | ALL | NULL | NULL | NULL | NULL | 4 | 25.00 | Using where || 3 | DEPENDENT UNION | emp | NULL | ALL | NULL | NULL | NULL | NULL | 4 | 25.00 | Using where || NULL | UNION RESULT | | NULL | ALL | NULL | NULL | NULL | NULL | NULL | NULL | Using temporary |+----+--------------------+------------+------------+------+---------------+------+---------+------+------+----------+-----------------+复制代码
这条SQL执行包含了PRIMARY、DEPENDENT SUBQUERY、DEPENDENT UNION和UNION RESULT
subquery 在select或者where列表中包含子查询
举例:
mysql> explain select * from emp where sal > (select avg(sal) from emp) ;+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+-------------+| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+-------------+| 1 | PRIMARY | emp | NULL | ALL | NULL | NULL | NULL | NULL | 4 | 33.33 | Using where || 2 | SUBQUERY | emp | NULL | ALL | NULL | NULL | NULL | NULL | 4 | 100.00 | NULL |+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+-------------+复制代码
DERIVED from子句中出现的子查询,也叫做派生表MATERIALIZED Materialized subquery?UNCACHEABLE SUBQUERY 表示使用子查询的结果不能被缓存
例如:
mysql> explain select * from emp where empno = (select empno from emp where deptno=@@sort_buffer_size);+----+----------------------+-------+------------+------+---------------+------+---------+------+------+----------+-------------+| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |+----+----------------------+-------+------------+------+---------------+------+---------+------+------+----------+-------------+| 1 | PRIMARY | emp | NULL | ALL | NULL | NULL | NULL | NULL | 4 | 100.00 | Using where || 2 | UNCACHEABLE SUBQUERY | emp | NULL | ALL | NULL | NULL | NULL | NULL | 4 | 25.00 | Using where |+----+----------------------+-------+------------+------+---------------+------+---------+------+------+----------+-------------+复制代码
uncacheable union 表示union的查询结果不能被缓存
table
对应行正在访问哪一个表,表名或者别名,可能是临时表或者union合并结果集。
如果是具体的表名,则表明从实际的物理表中获取数据,当然也可以是表的别名表名是derivedN的形式,表示使用了id为N的查询产生的衍生表当有union result的时候,表名是union n1,n2等的形式,n1,n2表示参与union的id
type
type显示的是访问类型,访问类型表示我是以何种方式去访问我们的数据,最容易想到的是全表扫描,直接暴力的遍历一张表去寻找需要的数据,效率非常低下。
访问的类型有很多,效率从最好到最坏依次是:
system > const > eq_ref > ref > fulltext > ref_or_null > index_merge > unique_subquery > index_subquery > range > index > ALL
一般情况下,得保证查询至少达到range级别,最好能达到ref
all 全表扫描,一般情况下出现这样的sql语句而且数据量比较大的话那么就需要进行优化
通常,可以通过添加索引来避免ALL
index 全索引扫描这个比all的效率要好,主要有两种情况:一种是当前的查询时覆盖索引,即我们需要的数据在索引中就可以索取一是使用了索引进行排序,这样就避免数据的重排序range 表示利用索引查询的时候限制了范围,在指定范围内进行查询,这样避免了index的全索引扫描,适用的操作符: =, , >, >=, <, <=, IS NULL, BETWEEN, LIKE, or IN()
官网上举例如下:
SELECT * FROM tbl_nameWHERE key_column = 10;
SELECT * FROM tbl_nameWHERE key_column BETWEEN 10 and 20;
SELECT * FROM tbl_nameWHERE key_column IN (10,20,30);
SELECT * FROM tbl_nameWHERE key_part1 = 10 AND key_part2 IN (10,20,30);
index_subquery 利用索引来关联子查询,不再扫描全表
value IN (SELECT key_column FROM single_table WHERE some_expr)
unique_subquery 该连接类型类似与index_subquery,使用的是唯一索引
value IN (SELECT primary_key FROM single_table WHERE some_expr)
index_merge 在查询过程中需要多个索引组合使用ref_or_null 对于某个字段既需要关联条件,也需要null值的情况下,查询优化器会选择这种访问方式
SELECT * FROM ref_table
WHERE key_column=expr OR key_column IS NULL;
fulltext 使用FULLTEXT索引执行joinref 使用了非唯一性索引进行数据的查找
SELECT * FROM ref_table WHERE key_column=expr;
SELECT * FROM ref_table,other_tableWHERE ref_table.key_column=other_table.column;
SELECT * FROM ref_table,other_tableWHERE ref_table.key_column_part1=other_table.columnAND ref_table.key_column_part2=1;
eq_ref 使用唯一性索引进行数据查找
SELECT * FROM ref_table,other_tableWHERE ref_table.key_column=other_table.column;
SELECT * FROM ref_table,other_tableWHERE ref_table.key_column_part1=other_table.columnAND ref_table.key_column_part2=1;
const 这个表至多有一个匹配行
SELECT * FROM tbl_name WHERE primary_key=1;
SELECT * FROM tbl_nameWHERE primary_key_part1=1 AND primary_key_part2=2;
例如:
mysql> explain select * from emp where id = 1;+----+-------------+-------+------------+-------+---------------+---------+---------+-------+------+----------+-------+| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |+----+-------------+-------+------------+-------+---------------+---------+---------+-------+------+----------+-------+| 1 | SIMPLE | emp | NULL | const | PRIMARY | PRIMARY | 4 | const | 1 | 100.00 | NULL |+----+-------------+-------+------------+-------+---------------+---------+---------+-------+------+----------+-------+复制代码
system 表只有一行记录(等于系统表),这是const类型的特例,平时不会出现
possible_keys
显示可能应用在这张表中的索引,一个或多个,查询涉及到的字段上若存在索引,则该索引将被列出,但不一定被查询实际使用

key
实际使用的索引,如果为null,则没有使用索引,查询中若使用了覆盖索引,则该索引和查询的select字段重叠

key_len
表示索引中使用的字节数,可以通过key_len计算查询中使用的索引长度,在不损失精度的情况下长度越短越好
ref
显示索引的哪一列被使用了,如果可能的话,是一个常数
rows
根据表的统计信息及索引使用情况,大致估算出找出所需记录需要读取的行数,此参数很重要,直接反应的sql找了多少数据,在完成目的的情况下越少越好

extra
包含额外的信息
using filesort 说明mysql无法利用索引进行排序,只能利用排序算法进行排序,会消耗额外的位置using temporary 建立临时表来保存中间结果,查询完成之后把临时表删除using index 这个表示当前的查询是覆盖索引的,直接从索引中读取数据,而不用访问数据表。如果同时出现using where 表明索引被用来执行索引键值的查找,如果没有,表示索引被用来读取数据,而不是真的查找using where 使用where进行条件过滤using join buffer 使用连接缓存impossible where where语句的结果总是false
MySQL索引基本知识
想要了解索引的优化方式,必须要对索引的底层原理有所了解。
索引的优点
大大减少了服务器需要扫描的数据量帮助服务器避免排序和临时表将随机io变成顺序io(提升效率)
索引的用处
快速查找匹配WHERE子句的行从consideration中消除行,如果可以在多个索引之间进行选择,mysql通常会使用找到最少行的索引如果表具有多列索引,则优化器可以使用索引的任何最左前缀来查找行当有表连接的时候,从其他表检索行数据查找特定索引列的min或max值如果排序或分组时在可用索引的最左前缀上完成的,则对表进行排序和分组在某些情况下,可以优化查询以检索值而无需查询数据行
索引的分类
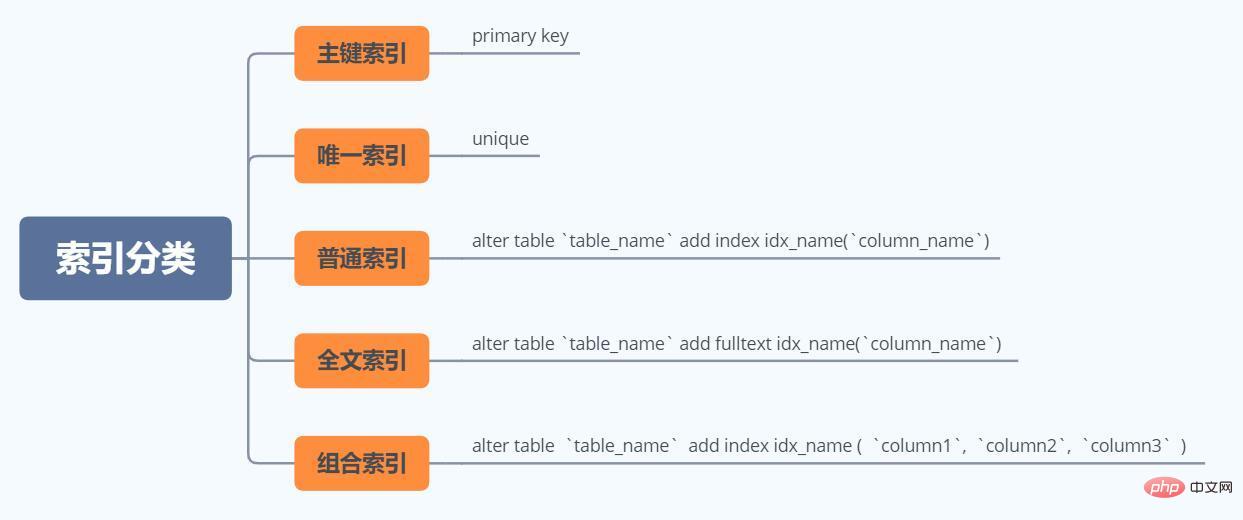
MySQL索引数据结构推演
索引用于快速查找具有特定列值的行。
如果没有索引,MySQL必须从第一行开始,然后通读整个表以找到相关的行。
表越大花费的时间越多,如果表中有相关列的索引,MySQL可以快速确定要在数据文件中间查找的位置,而不必查看所有数据。这比顺序读取每一行要快得多。
既然MySQL索引能帮助我们快速查询到数据,那么它的底层是怎么存储数据的呢?
几种可能的存储结构
hash
hash表的索引格式

hash表存储数据的缺点:
利用hash存储的话需要将所有的数据文件添加到内存,比较耗费内存空间如果所有的查询都是等值查询,那么hash确实很快,但是在实际工作环境中范围查找的数据更多一些,而不是等值查询,这种情况下hash就不太适合了
事实上,MySQL存储引擎是memory时,索引数据结构采用的就是hash表。
二叉树
二叉树的结构是这样的:
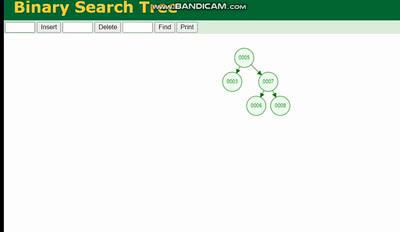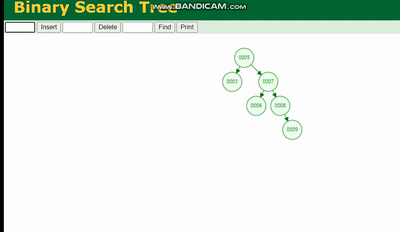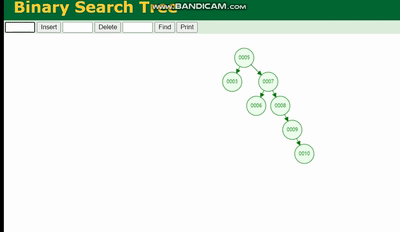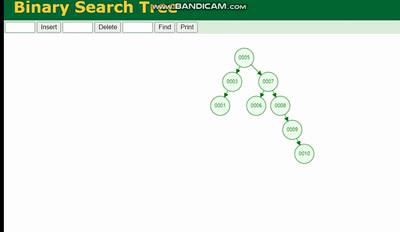
二叉树会因为树的深度而造成数据倾斜,如果树的深度过深,会造成io次数变多,影响数据读取的效率。
AVL树 需要旋转,看图例:
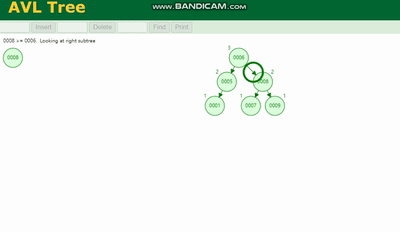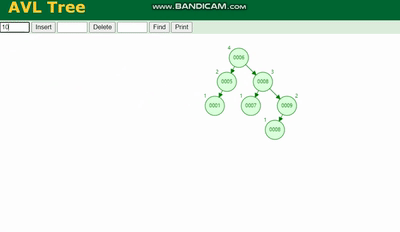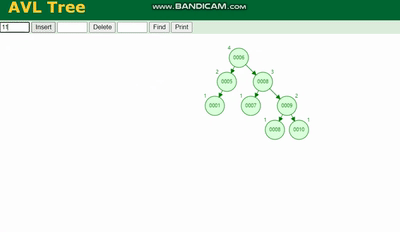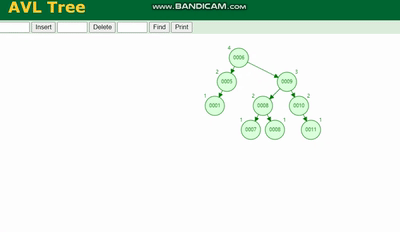
红黑树 除了旋转操作还多了一个变色的功能(为了减少旋转),这样虽然插入的速度快,但是损失了查询的效率。
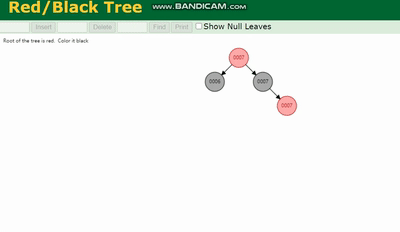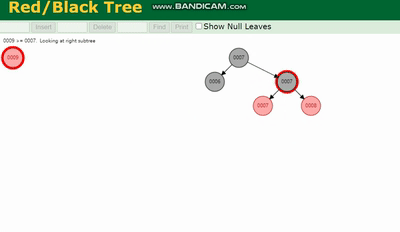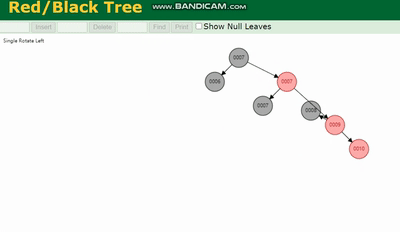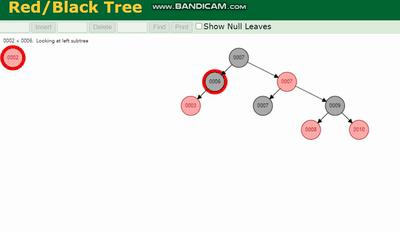
二叉树、AVL树、红黑树 都会因为树的深度过深而造成io次数变多,影响数据读取的效率。
再来看一下 B树
B树特点:
所有键值分布在整颗树中搜索有可能在非叶子结点结束,在关键字全集内做一次查找,性能逼近二分查找每个节点最多拥有m个子树根节点至少有2个子树分支节点至少拥有m/2颗子树(除根节点和叶子节点外都是分支节点)所有叶子节点都在同一层、每个节点最多可以有m-1个key,并且以升序排列
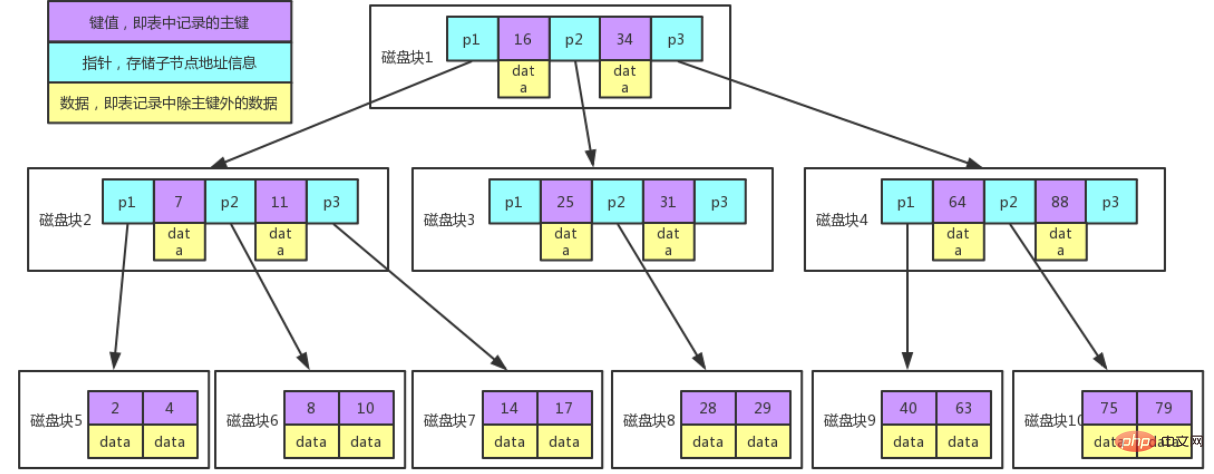
图例说明:
每个节点占用一个磁盘块,一个节点上有两个升序排序的关键字和三个指向子树根节点的指针,指针存储的是子节点所在磁盘块的地址。
两个关键词划分成的三个范围域对应三个指针指向的子树的数据的范围域。
以根节点为例,关键字为 16 和 34,P1 指针指向的子树的数据范围为小于 16,P2 指针指向的子树的数据范围为 16~34,P3 指针指向的子树的数据范围为大于 34。
查找关键字过程:
1、根据根节点找到磁盘块 1,读入内存。【磁盘 I/O 操作第 1 次】
2、比较关键字 28 在区间(16,34),找到磁盘块 1 的指针 P2。
3、根据 P2 指针找到磁盘块 3,读入内存。【磁盘 I/O 操作第 2 次】
4、比较关键字 28 在区间(25,31),找到磁盘块 3 的指针 P2。
5、根据 P2 指针找到磁盘块 8,读入内存。【磁盘 I/O 操作第 3 次】
6、在磁盘块 8 中的关键字列表中找到关键字 28。
由此,我们可以得知B树存储的缺点:
每个节点都有key,同时也包含data,而每个页存储空间是有限的,如果data比较大的话会导致每个节点存储的key数量变小当存储的数据量很大的时候会导致深度较大,增大查询时磁盘io次数,进而影响查询性能
那么MySQL索引数据结构是什么呢
官网:Most MySQL indexes (PRIMARY KEY, UNIQUE, INDEX, and FULLTEXT) are stored in B-trees
不要误会,其实MySQL索引的存储结构是B+树,上面我们一顿分析,知道B树是不合适的。
mysql索引数据结构—B+Tree
B+Tree是在BTree的基础之上做的一种优化,变化如下:
1、B+Tree每个节点可以包含更多的节点,这个做的原因有两个,第一个原因是为了降低树的高度,第二个原因是将数据范围变为多个区间,区间越多,数据检索越快。
2、非叶子节点存储key,叶子节点存储key和数据。
3、叶子节点两两指针相互连接(符合磁盘的预读特性),顺序查询性能更高。
B+树存储查找示意图:
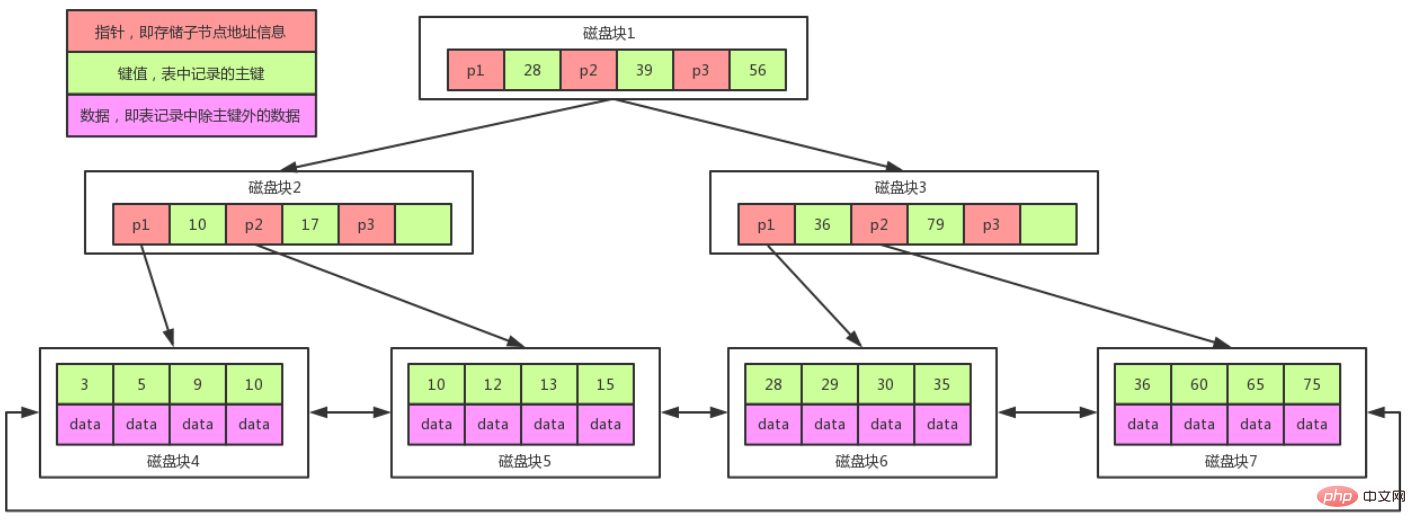
注意:
在B+Tree上有两个头指针,一个指向根节点,另一个指向关键字最小的叶子节点,而且所有叶子节点(即数据节点)之间是一种链式环结构。
因此可以对 B+Tree 进行两种查找运算:一种是对于主键的范围查找和分页查找,另一种是从根节点开始,进行随机查找。
由于B+树叶子结点只存放data,根节点只存放key,那么我们计算一下,即使只有3层B+树,也能制成千万级别的数据。
你得知道的技(zhuang)术(b)名词
假设有这样一个表如下,其中id是主键:
mysql> select * from stu;+------+---------+------+| id | name | age |+------+---------+------+| 1 | Jack Ma | 18 || 2 | Pony | 19 |+------+---------+------+复制代码
回表
我们对普通列建普通索引,这时候我们来查:
select * from stu where name='Pony';复制代码
由于name建了索引,查询时先找name的B+树,找到主键id后,再找主键id的B+树,从而找到整行记录。
这个最终会回到主键上来查找B+树,这个就是回表。
覆盖索引
如果是这个查询:
mysql> select id from stu where name='Pony';复制代码
就没有回表了,因为直接找到主键id,返回就完了,不需要再找其他的了。
没有回表就叫覆盖索引。
最左匹配
再来以name和age两个字段建组合索引(name, age),然后有这样一个查询:
select * from stu where name=? and age=?复制代码
这时按照组合索引(name, age)查询,先匹配name,再匹配age,如果查询变成这样:
select * from stu where age=?复制代码
直接不按name查了,此时索引不会生效,也就是不会按照索引查询—这就是最左匹配原则。
加入我就要按age查,还要有索引来优化呢?可以这样做:
(推荐)把组合索引(name, age)换个顺序,建(age, name)索引或者直接把age字段单独建个索引
索引下推
可能也叫
谓词下推。。。
select t1.name,t2.name from t1 join t2 on t1.id=t2.id复制代码
t1有10条记录,t2有20条记录。
我们猜想一下,这个要么按这个方式执行:
先t1,t2按id合并(合并后20条),然后再查t1.name,t2.name
或者:
先把t1.name,t2.name找出来,再按照id关联
如果不使用索引条件下推优化的话,MySQL只能根据索引查询出t1,t2合并后的所有行,然后再依次比较是否符合全部条件。
当使用了索引条件下推优化技术后,可以通过索引中存储的数据判断当前索引对应的数据是否符合条件,只有符合条件的数据才将整行数据查询出来。
小结
Explain 为了知道优化SQL语句的执行,需要查看SQL语句的具体执行过程,以加快SQL语句的执行效率。索引优点及用处。索引采用的数据结构是B+树。回表,覆盖索引,最左匹配和索引下推。
更多相关免费学习推荐:mysql教程(视频)
以上就是MySQL 执行计划explain与索引数据结构推演的详细内容,更多请关注创想鸟其它相关文章!
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 chuangxiangniao@163.com 举报,一经查实,本站将立刻删除。
发布者:程序猿,转转请注明出处:https://www.chuangxiangniao.com/p/191365.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 



















