
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜
 百川大模型
百川大模型
百川智能公司推出的一系列大型语言模型产品
 62 查看详情
62 查看详情 
Claude Haiku 4.5 是什么
claude haiku 4.5 是由 anthropic 推出的最新小型 ai 模型,兼具高性能与低成本优势。该模型在编码能力方面媲美其前代旗舰 claude sonnet 4,部分任务中甚至表现更佳,而运行成本仅为后者的三分之一,响应速度提升超过两倍。模型具备高度对齐性和安全性,被评定为 ai 安全等级 2(asl-2)。用户可通过 claude api、amazon bedrock 和 google cloud vertex ai 等平台部署该模型,适用于需要低延迟和实时响应的应用场景,如智能客服、编程辅助及对话式助手等。
 Claude Haiku 4.5 的主要功能
Claude Haiku 4.5 的主要功能
强大的编码支持:擅长处理各类编程任务,兼容多种编程语言,可生成高质量代码,适用于快速开发原型和多智能体协同项目。高效实时交互:响应迅速,适合用于聊天机器人、客户支持系统和结对编程等对延迟敏感的场景,确保流畅用户体验。灵活的任务协同:能与更强大的 Claude Sonnet 4.5 模型协同工作,将复杂问题拆解为多个子任务并行执行,显著提高处理效率。卓越的安全性:经过严格的安全评估与对齐训练,有害行为发生率极低,是目前 Anthropic 最安全的小型模型之一。超高性价比:定价仅为 Claude Sonnet 4 的三分之一,输入每百万 token 收费 1 美元,输出每百万 token 5 美元,极具成本优势。
Claude Haiku 4.5 的性能表现
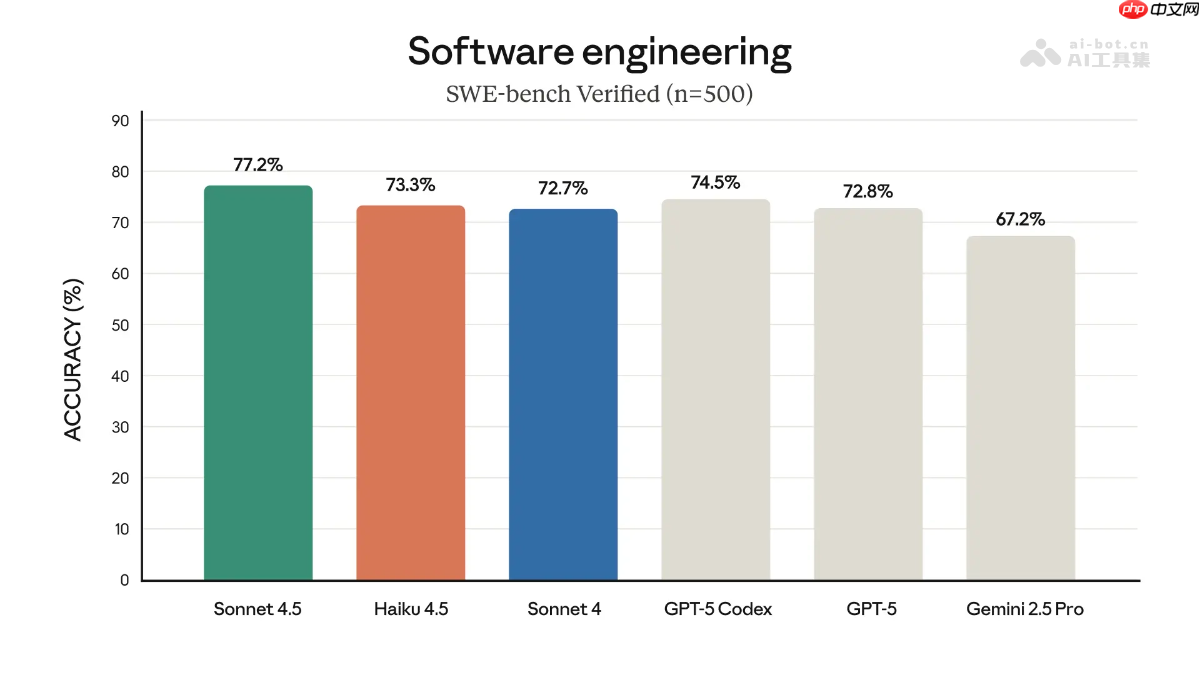
编程能力:SWE-bench Verified:准确率达到 73.3%,略高于 Claude Sonnet 4 的 72.7%,接近行业领先水平。Terminal-Bench:得分 41.0%,优于 Claude Sonnet 4 的 36.4%。OSWorld:获得 50.7% 的分数,明显领先于 Claude Sonnet 4 的 42.2%,在操作系统操作类任务中表现突出。数学推理能力:启用 Python 工具时:准确率达 96.3%,展现出强大的计算与逻辑处理能力。不使用工具时:准确率为 80.7%,虽低于启用工具的情况,但仍优于多数大型模型的表现。多语言理解能力:MMMLU 多语言测试:在涵盖 14 种非英语语言的评测中,平均准确率达到 73.3%,体现其出色的跨语言理解能力。
 Claude Haiku 4.5 的项目地址
Claude Haiku 4.5 的项目地址
官方网站:https://www.php.cn/link/9d4e43921a44fdfe09818f19f75bc4e8
Claude Haiku 4.5 的应用场景
编程辅助工具:帮助开发者自动生成代码、排查错误、优化结构,并支持敏捷开发和多智能体协作流程。智能对话助手:构建高响应性的聊天机器人,实现毫秒级回复,满足用户即时交互需求。客户服务代理:集成至客服系统中,自动解答常见问题,提供精准信息,减轻人工负担,提升服务效率。结对编程伙伴:作为虚拟程序员参与编码过程,实时提供建议与反馈,协助完成代码重构与逻辑完善。教育学习辅导:面向学生提供个性化的编程教学支持,解析难点知识,生成练习题并给出详细解答,助力自主学习。
以上就是Claude Haiku 4.5— Anthropic最新推出的小型AI模型的详细内容,更多请关注创想鸟其它相关文章!
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 chuangxiangniao@163.com 举报,一经查实,本站将立刻删除。
发布者:程序猿,转转请注明出处:https://www.chuangxiangniao.com/p/203155.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 
























