研究团队 投稿
量子位 | 公众号 QbitAI
首个开源多模态 Deep Research Agent 来了。
整合了网页浏览、图像搜索、代码解释器、内部 OCR 等多种工具,通过全自动流程生成高质量推理轨迹,并用冷启动微调和强化学习优化决策,使模型在任务中能自主选择合适的工具组合和推理路径。
假设你让一个 AI 回答这样一个问题:
” 在这张图所示动物的 Wikipedia 页面上,2020 年之前带有 ‘ visual edit ’ 标签的修订次数是多少?”

听起来不复杂,但要得到正确答案,需要经过多个环节:
1 从图像中识别出动物(它是一只海鹦 Atlantic puffin,而不是外形相似的鹈鹕、企鹅或海鸥)。
2 找到对应的 Wikipedia 页面并进入历史版本记录。
3 筛选出 2020 年之前带有 “visual edit” 标签的版本,并进行精确计数。
从上面案例可以看出,要解决这类问题,光有感知和理解还不够,Agent 还需要能够制定计划、灵活调用不同工具、在推理过程中不断验证和修正方向。
这类跨模态、跨工具、多步骤的任务,需要具备深度研究(Deep Research)能力的 Agent 才能有效应对。
WebWatcher 的核心方法
WebWatcher 的技术方案覆盖了从数据构建到训练优化的完整链路,核心目标是让多模态 Agent 在高难度多模态深度研究任务中具备灵活推理和多工具协作能力。整个方法包含三大环节:
1 多模态高难度数据生成:构建具备复杂推理链和信息模糊化的训练数据;
2 高质量推理轨迹构建与后训练:生成贴近真实多工具交互的推理轨迹,并通过监督微调(SFT)完成初步能力对齐。然后利用 GRPO 在复杂任务环境中进一步提升模型的决策能力与泛化性;
3 高难度基准评测:构建并使用 BrowseComp-VL 对模型的多模态深度推理能力进行验证。
1. 多模态高难度数据生成
现有大多数 VQA 数据集集中于单步感知任务,缺乏规划性与深度推理需求,难以支撑多模态深度研究代理的训练。为此,研究团队设计了一个全自动多模态数据生成流程,目标是在真实互联网知识分布下生成复杂、跨模态、链路不确定的任务样本。
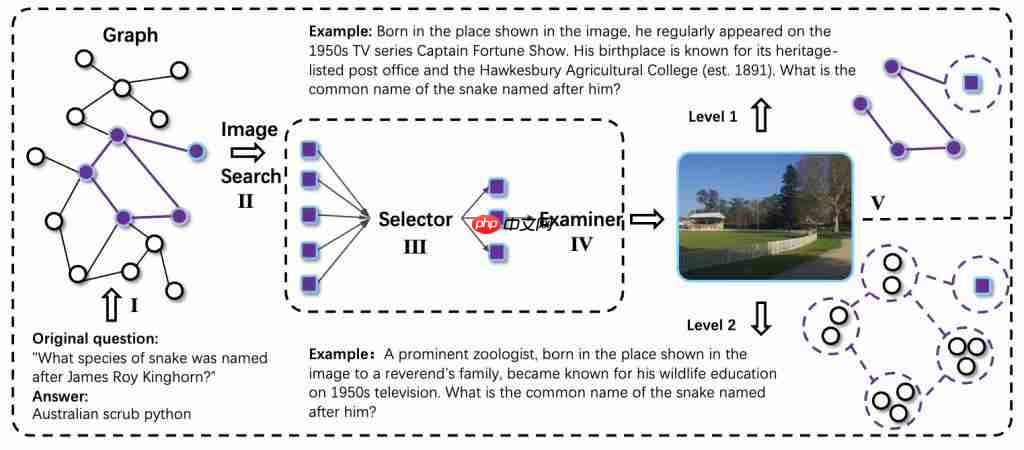
随机游走收集跨模态知识链
研究团队在多源网页(文本、图片、混合页面)中进行随机游走采样,构建多领域实体图谱。不同于传统的线性多跳问答链,这种图谱连接稠密、路径不固定,问题的解决路线难以预设,逼迫模型探索性地组合视觉信息。
信息模糊化提升不确定性
在生成问题时,研究团队刻意隐藏关键信息(如将 “2019 年 ” 替换为 “21 世纪初 “、将实体名改为描述性短语),并在视觉部分引入模糊指代词描述,使得模型无法依赖简单模式匹配,必须进行跨模态推理。
文本 – 视觉联合转换
所有复杂问题(QA) 样本通过 QA-to-VQA 转换模块扩展为多模态版本,将图谱中的部分实体或关系替换为图片、图表或网页截图,使问题天然依赖跨模态理解能力。
经过多阶段过滤,包括语义合理性检查、视觉相关性验证、推理链长度控制,研究团队得到了一个大规模、高质量的多模态推理数据集,能够覆盖多种复杂推理模式。
2. 高质量推理轨迹构建与后训练
在高难度训练数据的基础上,模型还需要学习如何调用工具和如何在推理中动态切换策略。然而,现有推理模型在长链多工具任务中存在两个问题:
1 思维链条冗长、模板化,缺乏跨任务的适应性;
2 工具调用格式和角色差异大,直接采集到的轨迹难以直接用于训练。
为此,研究团队提出了Action-Observation 驱动的轨迹生成方法:
收集真实的多工具交互轨迹;
 多墨智能
多墨智能
多墨智能 – AI 驱动的创意工作流写作工具
 108 查看详情
108 查看详情 
保留其 Action-Observation 结构,但控制 Thought 部分,确保每一步推理都简洁、行动导向,而非冗长的模板化解释;
使用规则过滤与 LLM 辅助审查,剔除低质量轨迹。
随后,研究团队基于这些高质量轨迹进行监督微调(SFT),让 WebWatcher 在训练初期快速掌握多模态 ReAct 式推理和工具调用的基本模式,为后续的强化学习阶段打下基础。
在完成冷启动后,WebWatcher 进入强化学习阶段,用GRPO进一步提升多模态 Agent 在复杂环境下的决策能力。模型严格结合格式正确性与答案准确性双重标准设计奖励,对多步工具调用的连贯性和最终答案的准确性均予以关注,从而提升多模态决策链的可靠性。
3. BrowseComp-VL:多模态深度研究基准
为了全面验证 WebWatcher 的能力,研究团队提出了BrowseComp-VL,它是 BrowseComp 在视觉 – 语言任务上的扩展版本,设计目标是逼近人类专家的跨模态研究任务难度。
该基准具有以下特点:
– 任务长且信息模糊化:问题往往包含多个模糊实体描述,需要跨网页、跨模态搜索与整合;
– 多工具协作必要性:任务无法仅靠感知或文本检索完成,必须结合网页浏览、图像检索、OCR、代码执行等多种工具;
– 真实网络环境:测试样本来自真实网页与图像资源,保持复杂性与不可预测性。
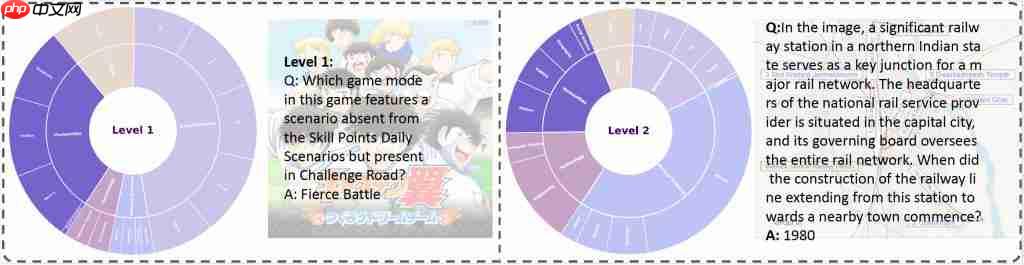
实验结果:刷新多模态推理与信息检索新纪录
在多轮严格评测中,WebWatcher 在四大核心领域全面领先于当前主流的开源与闭源多模态大模型,显示出其在复杂推理、信息检索、知识整合以及聚合类信息寻优等任务上的强劲实力。
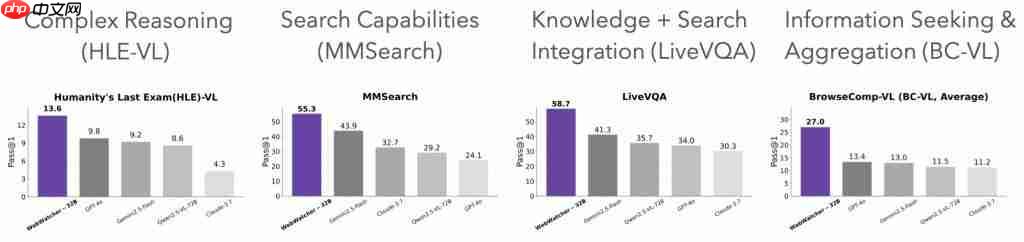
复杂推理(HLE-VL)
在人类终极考试(Humanity ’ s Last Exam,HLE-VL)这一多步复杂推理基准上,WebWatcher 以 13.6% 的 Pass@1 分数一举夺魁,大幅领先于 GPT-4o(9.8%)、Gemini2.5-flash(9.2%)、Qwen2.5-VL-72B(8.6%)等代表性模型。充分证明了其在高难度知识融合与链式决策中的推理能力。
信息检索能力(MMSearch)
在更贴近真实多模态搜索的 MMSearch 评测中,WebWatcher 同样表现卓越,Pass@1 得分高达 55.3%,相比 Gemini2.5-flash(43.9%)和 GPT-4o(24.1%)等大幅领先,展现了极高的检索精准性和复杂场景下的信息聚合能力。
知识 + 检索整合(LiveVQA)
LiveVQA 是知识推理与外部信息获取深度协同的典型场景。WebWatcher 的 Pass@1 成绩达到 58.7%,领先 Gemini2.5-flash(41.3%)、Qwen2.5-VL-72B(35.7%)和 GPT-4o(34.0%),充分体现了其在知识调用、事实核查与实时信息融合等多维技能上的系统性优势。
信息寻优与聚合(BrowseComp-VL)
在最具综合挑战的 BrowseComp-VL 基准(信息聚合型任务)上,WebWatcher 以 27.0% 的平均得分(Pass@1)遥遥领先,于 GPT-4o(13.4%)、Gemini2.5-flash(13.0%)、Qwen2.5-VL-72B(11.5%)、Claude-3.7(11.2%)等国内外主流旗舰模型,成绩提升超过一倍。该基准涵盖了跨网页、多实体、模糊表达等严苛考验,彰显了 WebWatcher 在复杂信息寻优与聚合领域的绝对能力优势。
综合来看,WebWatcher 不仅在单一任务维度实现领先,更在复合型任务、跨模态复杂推理及真实信息检索等方面,奠定了新一代开源多模态 Agent 的领先地位。
arxiv:https://arxiv.org/abs/2508.05748
github 仓库:https://github.com/Alibaba-NLP/WebAgent
一键三连「点赞」「转发」「小心心」
欢迎在评论区留下你的想法!
— 完 —
点亮星标
科技前沿进展每日见
以上就是首个开源多模态 Deep Research 智能体,超越多个闭源方案的详细内容,更多请关注创想鸟其它相关文章!
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 chuangxiangniao@163.com 举报,一经查实,本站将立刻删除。
发布者:程序猿,转转请注明出处:https://www.chuangxiangniao.com/p/211770.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫