
 一、前言 在最近学习elastic-job和xxl-job(一个分布式作业调用中间件)时,我接触到一个有趣的数据结构:
一、前言 在最近学习elastic-job和xxl-job(一个分布式作业调用中间件)时,我接触到一个有趣的数据结构:时间轮。不仅是xxl-job,在许多任务调度中间件或涉及延迟/定时任务的场景中,都能看到时间轮的应用。那么,为什么时间轮在这些时间调度相关的场景中如此受欢迎呢?让我们一起来探究其中的原因。
二、什么是时间轮1. 基本概念 如果用形象化的方式来描述,时间轮就像日常生活中的时钟,不断以恒定速度转动着秒针、分针和时针。在IBM DEVELOPER的文章《Linux下定时器的实现方式分析》[1]中,时间轮被描述为:
从具体实现来看,时间轮是一个基于「数组」实现的「循环队列」,数组的每个元素被称为「槽(slot)」,每个槽中存储着一个「任务列表」。这个任务列表的实现方式多样,可以是「双向链表」实现,也可以是「数组」实现。除了基本的存储结构,时间轮还有一根用于指示当前时间的指针,这根指针同时也用于触发所指向的时间槽内的任务。该指针以恒定的速度旋转,每经过一个槽即走过一个单位时间(因此也可以将槽称为时间槽,因为它既表示时间刻度,也表示存储空间),旋转一圈则走过时间轮的一个生命周期。以下是一张简单的时间轮数据结构图:
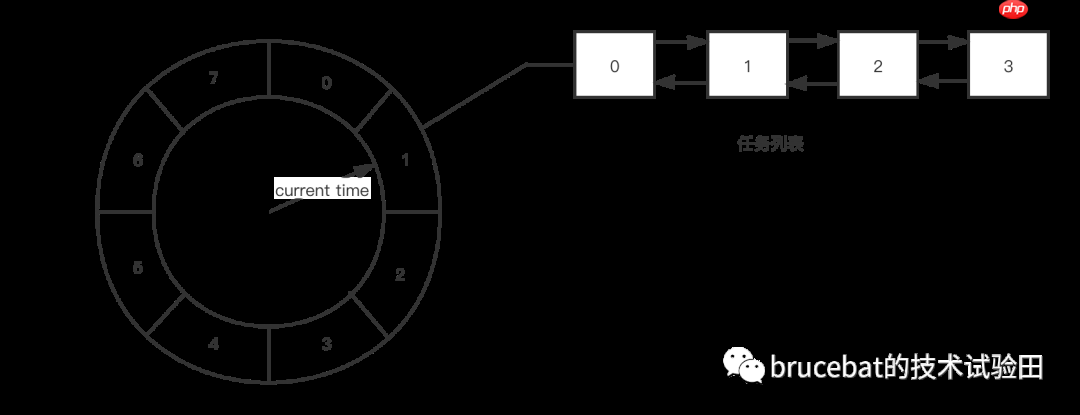 对于时间轮所采用的数据结构(底层使用数组实现),在时间槽数量较大的情况下,插入任务和删除任务的时间复杂度接近O(1)。这里通过下面的例子来了解一下插入任务的具体逻辑:如上图,时间轮中的时间槽数量为8(单位时间为秒,即时间轮的周期为8秒),当前时间为1秒,现在要插入一个延迟5秒的任务,则任务插入的位置为
对于时间轮所采用的数据结构(底层使用数组实现),在时间槽数量较大的情况下,插入任务和删除任务的时间复杂度接近O(1)。这里通过下面的例子来了解一下插入任务的具体逻辑:如上图,时间轮中的时间槽数量为8(单位时间为秒,即时间轮的周期为8秒),当前时间为1秒,现在要插入一个延迟5秒的任务,则任务插入的位置为 Index = (Tc + Td) % N = (1 + 5) % 8 = 6(其中Tc为当前时间,Td为延迟时间,N为时间轮的时间周期)。
聪明的同学一定发现了,如果此时插入一个延迟10秒执行的任务,那么最终得到的Index就为3。但是按照当前的任务触发逻辑,指针只需要走两个时间槽就会触发这个延迟任务,这与预期的延迟10秒再触发不符。那么应该如何解决这样一个问题呢?
立即学习“Java免费学习笔记(深入)”;
遇到这样一个问题,最直接的解决方案就是增加时间轮中时间槽的数量,这样上述的延迟任务就依然能放置在同一个轮次中。但是在日常开发工作中,延迟数小时甚至数日的任务都有可能存在,无限制地扩大时间槽的数量只会导致内存消耗的急剧增大,这并不是一个十分优雅的解决方案。下面就让我们一起来看两种更为优雅的解决方案。
基于轮次的时间轮 上面的问题可以理解为是一种「时间溢出」,基础的时间轮模型对于这种时间溢出问题是无法解决的,所以需要在基础的时间轮模型上进行升级。从上面的计算中可以得到,延迟10秒执行的任务实际上是在第二轮中的Index为3的位置进行触发。为了和第一轮中的任务进行区分,这里引进了「轮次」的概念。
通过轮次的概念,可以准确区分每个任务所处的时间轮周期。还是上面的例子,延迟10秒的任务所处的轮次为 Round = (Tc + Td) / N = (1 + 10) / 8 = 1,任务插入的位置为3,那么当时间指针循环1圈后扫到下标为3的时间槽时就会触发这个延迟任务。
多层级时间轮 除了上面使用基于轮次的时间轮,优秀的大佬们(是前辈大佬,不是女装大佬)想出了另外一种形式的时间轮——「多层级的时间轮」。下面是一个简单的数据结构图(单位换算请忽略,这里只是借用了秒分时的概念):
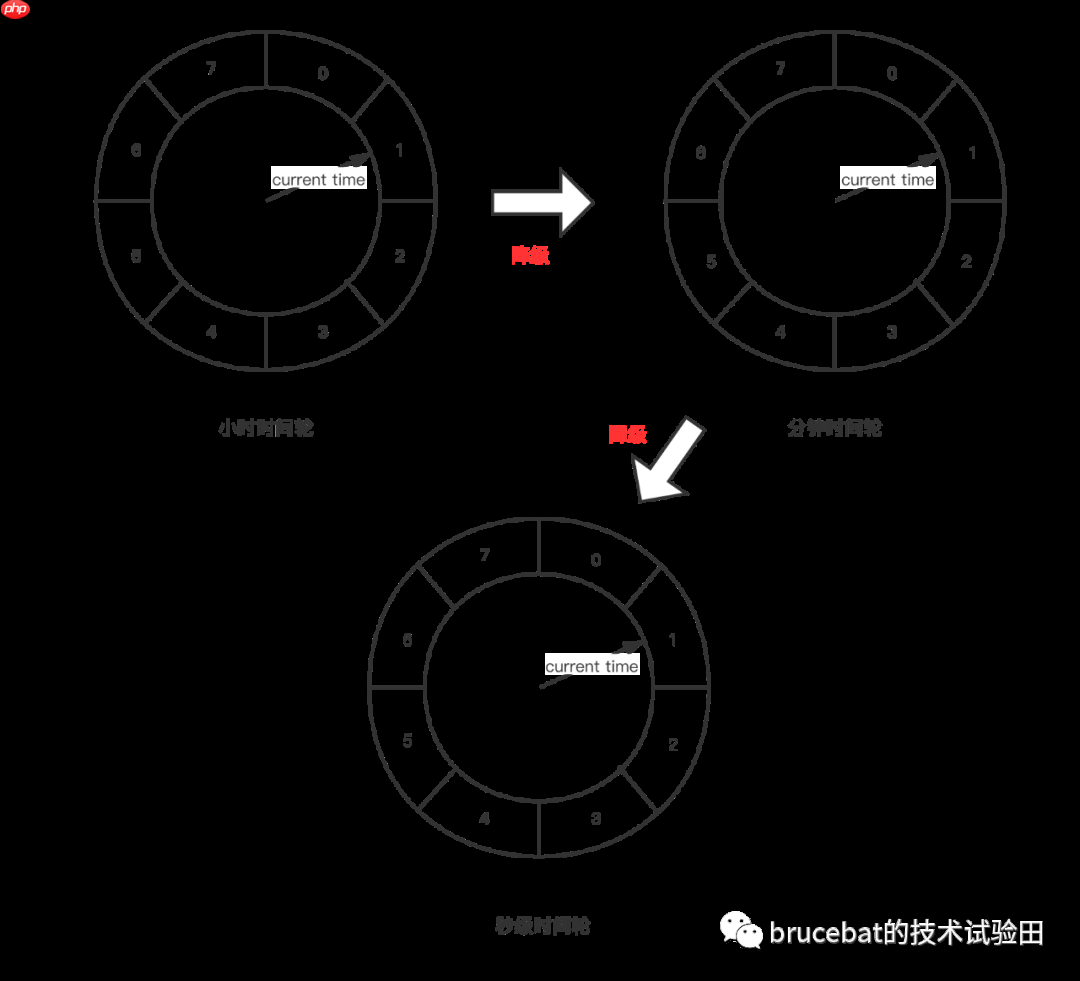 多层级时间轮从逻辑上和我们日常使用的时钟颇为相似,上一层级的时间轮中的一个时间槽(单位时间)等于下一层级的时间轮的一个时间周期。
多层级时间轮从逻辑上和我们日常使用的时钟颇为相似,上一层级的时间轮中的一个时间槽(单位时间)等于下一层级的时间轮的一个时间周期。
对于层次的算法其实和轮次相同,还是用上面的例子,类似的可以算出当前需要插入的延迟任务应该放在第二层时间轮中Index等于1的时间槽中,当最下层的时间轮走完一轮后,第二层时间轮中的指针就会指向Index为1的时间槽,此时会触发一次时间轮的「降级」。
通过「多层级」和「降级」的方式就可以解决延迟任务时间溢出的问题。
三、为什么要使用时间轮 对于日常见到的任务调度场景所要调度的定时任务可以划分为以下三种:
一定时间后执行的「延迟任务」指定时间进行执行的「定时任务」有固定执行周期的「周期性定时任务」 对于前两种任务可以相互转换,这里归结为同一种类型的任务,即「延迟任务」。举个例子,当前时间为上午十点,新增一个下午一点半的定时任务,这个任务也可以看做是从当前时间开始延迟三个半小时执行的延迟任务。
同样,对于周期性执行的定时任务,其实也可以看做是一个「循环执行的延迟任务」,但是和只执行一次的定时任务相比,周期性执行的定时任务多了一个属性——「下次执行时间」。根据当前时间和下次执行时间可以算出延迟时间。
所以,综上,时间的调度实际上是针对「延迟时间」进行调度的。这就意味着我们设计的时间调度存储任务的集合需要是「时间线性的」。
除了存储任务的集合,在绝大多数的定时任务调度场景中,定时任务都是依赖「一个外部的时间调度器(Scheduler)」来进行任务的触发。如果每个定时任务都使用一个单独的时间调度器来进行调度触发,无论从设计上或者使用上来讲都是很不优雅。
结合上面两个方面,从设计方面来看,定时任务的调度可以抽象为具有以下三个要素的事件:
具体执行的任务任务执行时间触发任务执行的调度器 前两个要素可以进行数据结构上的抽象,对于所有的任务都「任务详情」和「执行时间」可以抽象为相同的数据结构。而对于调度器而言,其职责是单一的,就是根据任务执行的时间进行任务的触发,所以调度器是可以「复用的」,也就是说所有的任务触发都是可以使用同一个调度器,而不是每个任务自己配置一个。
为了实现只使用一个调度器,那么就需要将任务放置在同一个集合中,让调度器针对这个集合中的任务按照任务执行时间进行任务的触发。对于存放任务的集合要满足以下三点:
能够按照「执行时间」进行排序/触发按照执行时间「进行任务的插入和删除」要快「容量」适中 首先来看第一个条件,满足第一个条件的数据结构必须是线性数据结构,比如链表、栈和队列,但是由于需要线性触发,栈作为一个FILO的数据结构自然就被排除了。但是加上第二个条件之后就需要将链表去除,因为在线性检索方面链表的时间复杂度为O(n)。最后再加上第三个条件,最终选择基于简单循环数组实现固定长度的循环队列。这里为什么不使用动态循环数组的原因上面也说过,如果集合的容量非常大,则会造成内存的大量消耗,基于这一原因需要使用固定长度的循环数组(当然这里的长度也需要谨慎选择)。
基于上面的原因,最终选择了时间轮这样一个在时间和空间复杂度上较优的数据结构。
四、时间轮的应用1. Kafaka中的时间轮 Kafaka作为一个高吞吐量的事件流平台,其中存在的无数的延迟任务,对于这些任务的调度,Kafaka选择了多层级的时间轮进行任务的调度,其中每个时间槽中存储的任务列表Kafaka使用了循环双向链表进行实现。为了区分边界,在循环双向链表中设置了一个「哨兵节点(也即哑元节点)」,该节点不存放任何任务且作为任务列表中的第一个节点。
Quartz中的时间轮 Quartz作为一款经典的任务调度框架,对于调度器的设计影响了后续无数的任务调度框架(比如Elastic-Job、xxl-job)。在Quartz中,在进行任务调度的过程中只是借用了最基本的时间轮数据结构,并没有使用轮次或者层级。这是由于Quartz中的任务是通过单独的任务调度线程扫描数据库添加到时间轮中,也就是进行任务的「预添加」。在这一过程中,任务预添加所使用的延迟时间是固定的(区别于Kafaka中,不同的延迟任务延迟时间是不固定的),所以这里可以直接使用基础版时间轮而不同担心时间溢出的问题。
五、总结 时间轮的提出最早可以追溯到1997年G. Varghese和A. Lauck的论文《Hashed and hierarchical timing wheels: efficient data structures for implementing a timer facility》[2]。基于此后续对于任务调度大多都采用时间轮这一设计思路,比如Quartz中的单层时间轮、Netty中的基于轮次的时间轮和Kafaka中的多层级时间轮。其本质都是为了减少调度器的使用,同时更好使用多线程实现任务的批量调用。
在本文中,我更多的是关注时间轮数据结构上的设计,对于时钟驱动方面没有做更深入的探讨,有兴趣的同学可以看一看Kafaka或者Linux中相应的设计方案。
最后祝各位国庆中秋双节快乐!
Reference[1]Linux下定时器的实现方式分析: https://www.php.cn/link/ed34d801ecf10f1a8178debdf0f365e0
[2]Hashed and hierarchical timing wheels: efficient data structures for implementing a timer facility: https://www.php.cn/link/7e7e8e15d8dbc48087a8e372d9d4631a
以上就是Java中的数据结构(四):时间轮的详细内容,更多请关注创想鸟其它相关文章!
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 chuangxiangniao@163.com 举报,一经查实,本站将立刻删除。
发布者:程序猿,转转请注明出处:https://www.chuangxiangniao.com/p/21418.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 



























