
在当前人工智能的前沿探索中,yann lecun 所倡导的 jepa(联合嵌入预测架构)正逐步重塑大语言模型(llm)的训练范式。这位图灵奖得主并非仅仅对现有 llm 架构提出批评,而是亲自投身于其革新之中。传统 llm 的训练机制主要依赖输入空间中的序列生成任务,例如预测下一个词元,这种基于局部重构的方法虽广泛应用,但在建模全局语义结构方面暴露出明显瓶颈,类似问题早已在视觉领域被深入揭示。
LeCun 及其研究团队指出,计算机视觉(CV)领域近年来在自监督学习方面的突破可为语言模型提供宝贵借鉴。JEPA 的核心理念在于:不直接在原始输入层面进行重建,而是在高维抽象表征空间中完成跨模态或跨区域的信息预测,从而更高效地捕捉数据背后的因果结构与世界知识。Meta AI 已在图像和视频理解任务中验证了 JEPA 的有效性,如今,他们正致力于将这一框架迁移至自然语言处理领域。
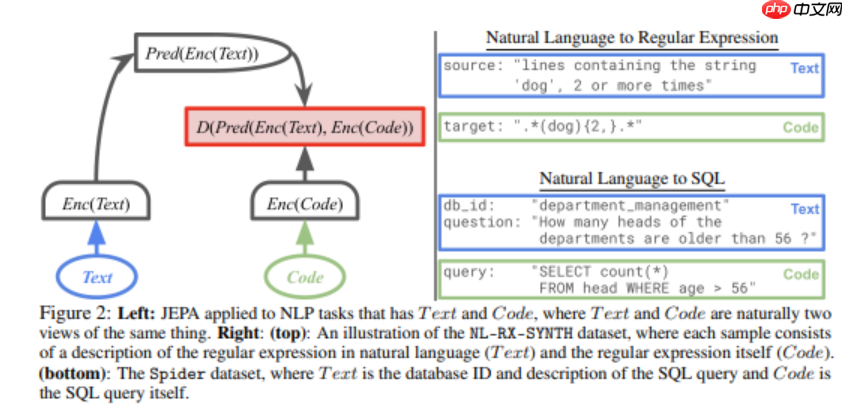
为实现这一跨越,研究人员 Hai Huang、Yann LeCun 与 Randall Balestriero 联手推出了 LLM-JEPA——首个成功将 JEPA 自监督架构引入大语言模型的系统。该模型创新性地将文本与代码视为同一语义概念的不同表达形式,利用双视角一致性约束,在嵌入空间内实施特征补全式预测。借助 JEPA 在表征学习上的优势,LLM-JEPA 不仅保持了原有语言模型的强大生成能力,还在推理准确性与抗干扰能力方面实现了显著提升。
 云雀语言模型
云雀语言模型
云雀是一款由字节跳动研发的语言模型,通过便捷的自然语言交互,能够高效的完成互动对话
 54 查看详情
54 查看详情 
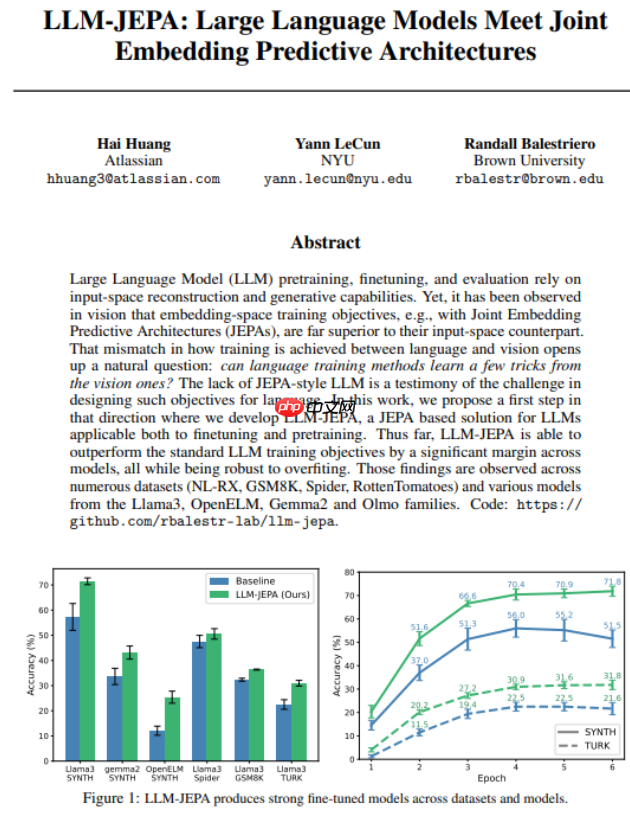
实证研究表明,LLM-JEPA 在包括 Llama3、OpenELM 和 Gemma2 等多种主流架构上均展现出优越性能,在 GSM8K 数学推理、Spider 复杂 SQL 生成等多个基准测试中大幅超越传统训练目标下的模型表现。尤为值得注意的是,该方法在减少过拟合、增强泛化能力方面表现出优异的鲁棒性,为构建更智能、更稳定的大语言模型开辟了新路径。
尽管现阶段的研究重点集中于微调阶段的应用,但初步的预训练实验已显现出令人鼓舞的潜力。研究团队表示,未来工作将深入探索 LLM-JEPA 在完整预训练流程中的适配与优化,有望为下一代语言模型的发展注入全新动能。
以上就是LeCun 新提案:用 CV 思路重塑语言模型的详细内容,更多请关注创想鸟其它相关文章!
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 chuangxiangniao@163.com 举报,一经查实,本站将立刻删除。
发布者:程序猿,转转请注明出处:https://www.chuangxiangniao.com/p/225134.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 






















