
阿里巴巴通义实验室推出了全新的端到端语音识别大模型 funaudio-asr。该模型引入创新的 context 模块,显著提升了在高噪声环境下的识别稳定性,将幻觉率从 78.5% 大幅下降至 10.7%,降幅接近 70%。
FunAudio-ASR 基于数千万小时的真实音频数据训练而成,并深度融合了大语言模型的语义理解能力,在远场、嘈杂背景及多说话人等复杂场景中表现出色,性能超越 Seed-ASR、KimiAudio-8B 等当前主流系统。
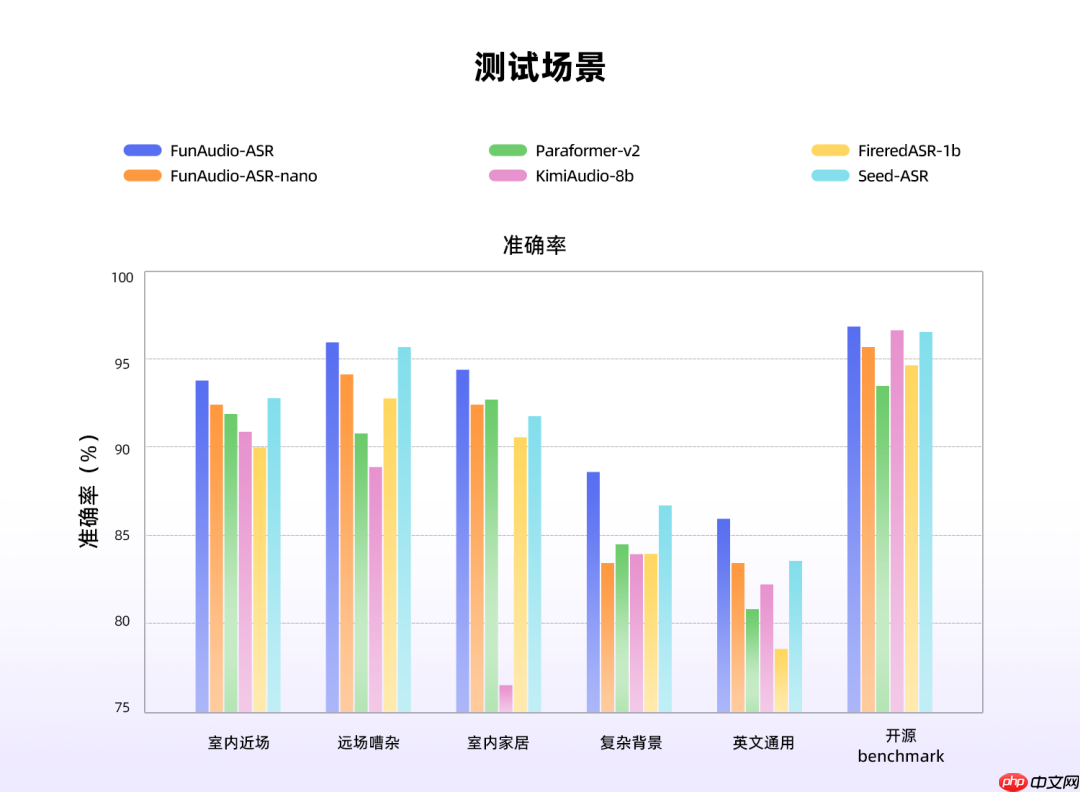
为满足不同应用场景需求,团队还推出了轻量版模型 FunAudio-ASR-nano。该版本在保证较高识别精度的同时,大幅降低计算资源消耗,适用于对算力和成本敏感的终端部署场景。
 通义听悟
通义听悟
阿里云通义听悟是聚焦音视频内容的工作学习AI助手,依托大模型,帮助用户记录、整理和分析音视频内容,体验用大模型做音视频笔记、整理会议记录。
 85 查看详情
85 查看详情 
两个版本均支持低延迟流式语音识别、中英文自动切换以及用户自定义热词功能,具备良好的实用性与灵活性。目前,该技术已成功应用于钉钉“AI 听记”、视频会议系统以及 DingTalk A1 硬件设备中。其开放 API 也已在阿里云百炼平台正式上线,供开发者调用。
体验地址:https://www.php.cn/link/1a79e60cce2641f20b34acb72cd287d7
技术报告:https://www.php.cn/link/e340862bc3c1549012646f7abdc2e155
以上就是阿里通义实验室发布端到端语音识别大模型 FunAudio-ASR的详细内容,更多请关注创想鸟其它相关文章!
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 chuangxiangniao@163.com 举报,一经查实,本站将立刻删除。
发布者:程序猿,转转请注明出处:https://www.chuangxiangniao.com/p/232261.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 

























