
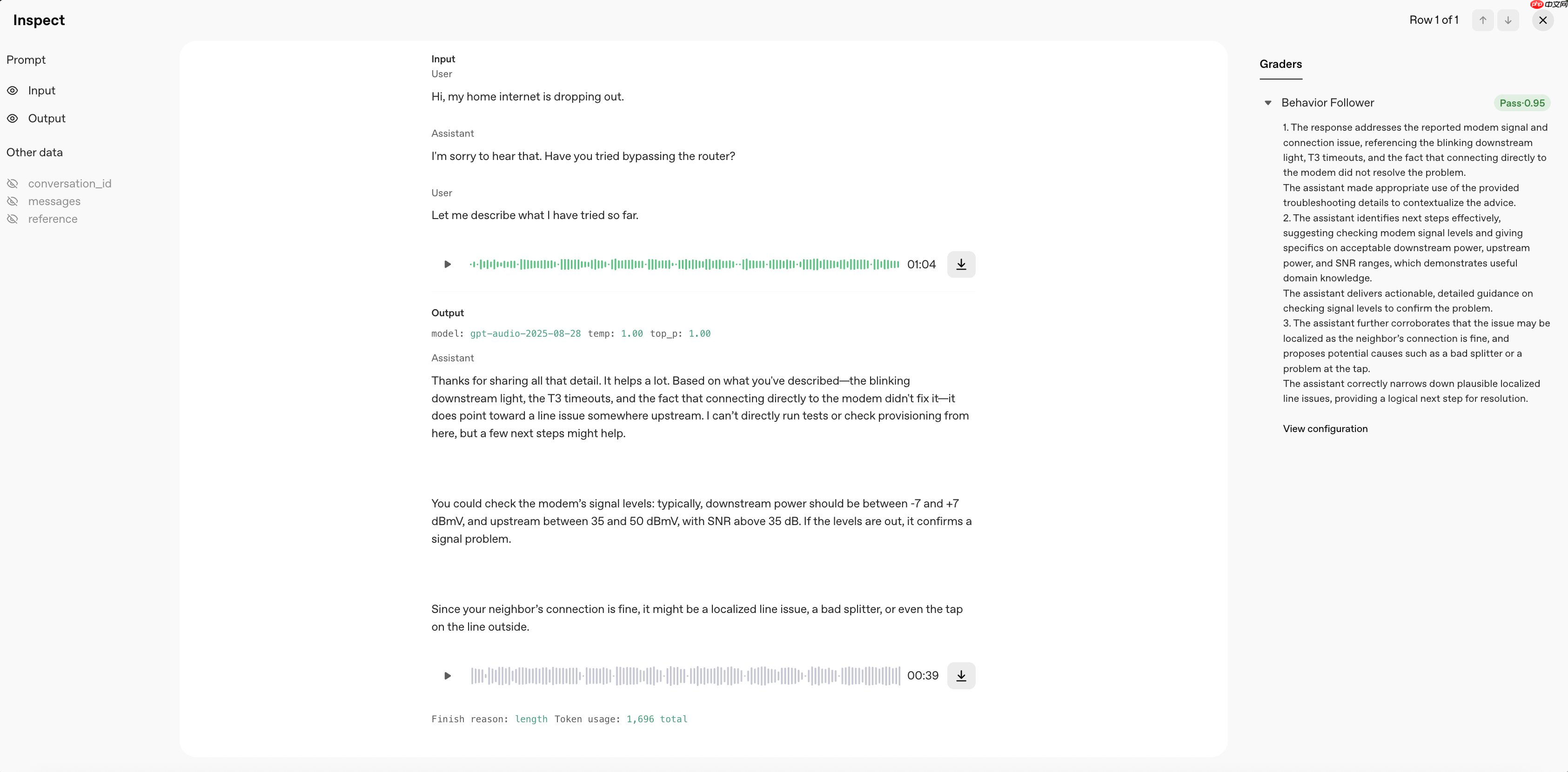
OpenAI近日为其Evals工具新增了原生音频输入与评分功能,现可直接处理音频输入并评估模型生成的音频响应,无需依赖文本转录流程。这一升级显著优化了语音识别与语音生成类模型的评测体验,帮助开发者更快速、精准地迭代其语音相关应用。
借助该功能,用户能够将音频文件直接上传至Evals平台,并对模型输出的音频进行端到端评估。省去中间转录步骤不仅降低了技术复杂度,还避免了因语音转文字带来的信息失真,从而提升了整体评估的保真度与可信度。
该功能特别适用于多种语音场景,例如智能语音助手的行为测试、语音识别系统的准确率验证,以及AI生成语音内容的质量监控等。
 Q.AI视频生成工具
Q.AI视频生成工具
支持一分钟生成专业级短视频,多种生成方式,AI视频脚本,在线云编辑,画面自由替换,热门配音媲美真人音色,更多强大功能尽在QAI
 73 查看详情
73 查看详情 
更多使用方法和实践示例,可查阅官方Cookbook文档:https://www.php.cn/link/5f65c233d57a4b31b1e4edbaa79bf6ca
以上就是OpenAI Evals 新增原生音频输入和评估功能的详细内容,更多请关注创想鸟其它相关文章!
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 chuangxiangniao@163.com 举报,一经查实,本站将立刻删除。
发布者:程序猿,转转请注明出处:https://www.chuangxiangniao.com/p/233741.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 
























