

论文地址: https://www.php.cn/link/5810733635b8629df4a4badaaef78f6c
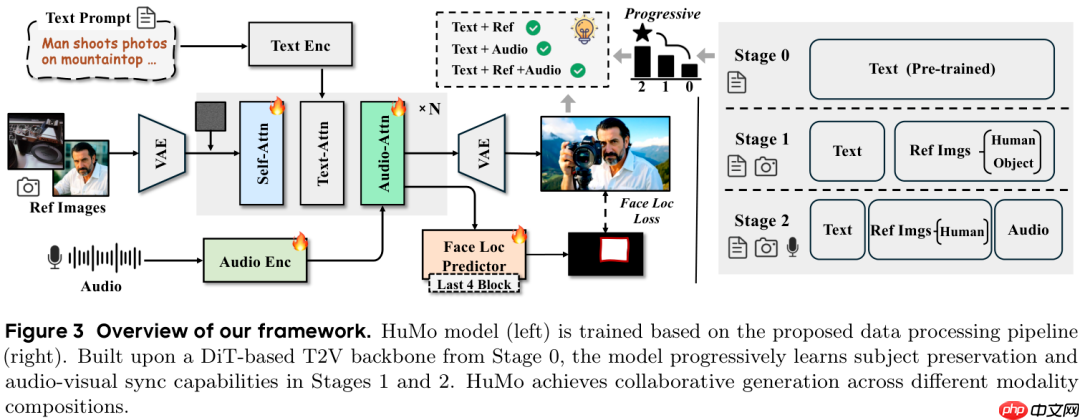
由字节跳动智能创作团队与清华大学联合推出的 HuMo,是一个统一的 HCVG(Human-Centric Video Generation)框架,致力于推动以人为中心的视频生成技术发展。该框架支持文本、图像和音频三种模态的协同驱动,实现高度可控的人物视频生成。

HuMo(全称 Human-Modal)通过构建高质量多模态数据集,并引入创新的渐进式训练机制,首次在统一模型中实现了对多种输入信号的有效融合与精细控制。其生成视频最高可达 720P 分辨率,最长支持 97 帧、25FPS 的输出,在多个子任务上的表现均超越当前专用模型。
 豆包大模型
豆包大模型
字节跳动自主研发的一系列大型语言模型
 834 查看详情
834 查看详情 
该框架的关键技术包括全新的数据处理流程、逐步增强的多模态训练策略,以及可根据输入灵活调整的推理机制。
项目地址:
https://www.php.cn/link/09604c68bfa72e9930b00c967e64747e
https://www.php.cn/link/b2a242690f117309099b7a561b605e9e
以上就是字节跳动联合清华大学开源统一多模态框架:HuMo的详细内容,更多请关注创想鸟其它相关文章!
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 chuangxiangniao@163.com 举报,一经查实,本站将立刻删除。
发布者:程序猿,转转请注明出处:https://www.chuangxiangniao.com/p/236832.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 



























