
qwen2.5-omni-3b 是由阿里巴巴 qwen 团队推出的一款轻量级多模态 ai 模型。它是 qwen2.5-omni-7b 的精简版本,专门为消费级硬件设计,支持文本、音频、图像和视频等多种输入功能。参数量从 7b 减少到 3b,但仍能保持 7b 模型 90% 以上的多模态性能,尤其在实时文本生成和自然语音输出方面表现突出。处理 25,000 token 的长上下文输入时,显存占用减少了 53%,从 7b 模型的 60.2gb 降至 28.2gb,可以在 24gb gpu 的设备上运行。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜
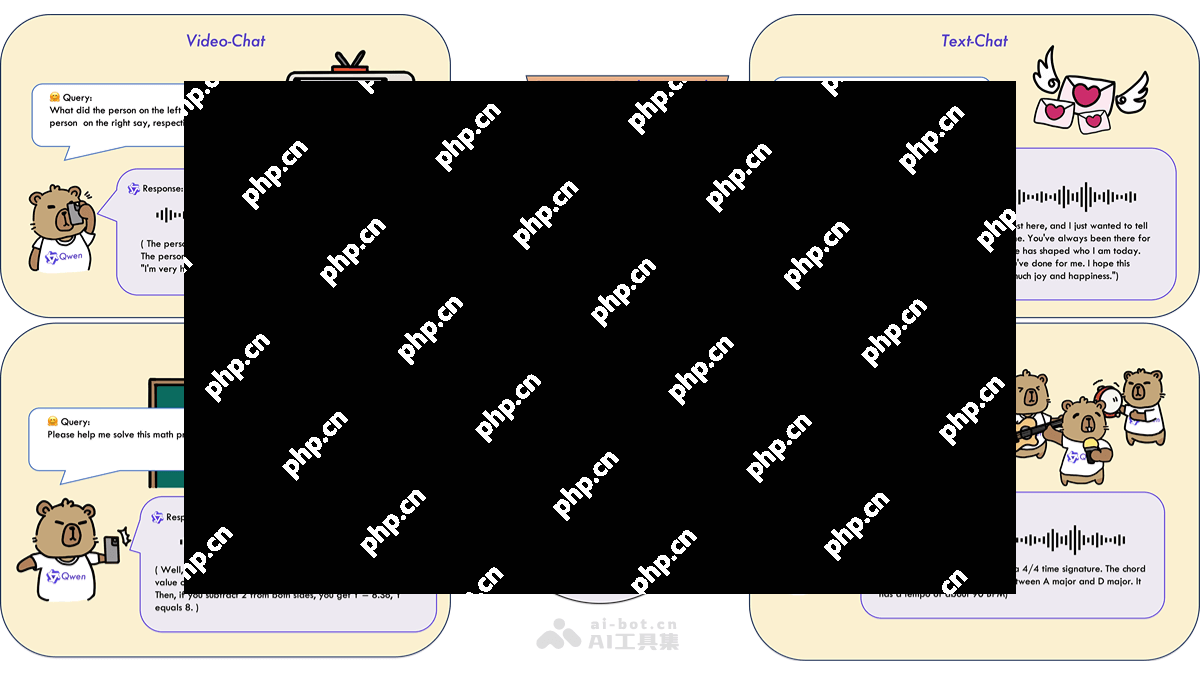
Qwen2.5-Omni-3B的主要功能包括:
多模态输入与实时响应:支持文本、音频、图像和视频等多种输入功能,并能实时生成文本和自然语音响应。语音定制:用户可以在两个内置声音(Chelsie 女性和 Ethan 男性)之间选择,以适应不同的应用或受众。显存优化:处理 25,000 token 的长上下文输入时,显存占用从 7B 模型的 60.2GB 降至 28.2GB,减少了 53%,可在 24GB GPU 的设备上运行。架构创新:采用 Thinker-Talker 设计和定制位置嵌入方法 TMRoPE,确保视频与音频输入的同步理解。优化支持:支持 FlashAttention 2 和 BF16 精度优化,进一步提升速度并降低内存消耗。性能表现:在多模态基准测试中,性能接近 7B 模型,例如在 VideoBench 视频理解测试中得分为 68.8,在 Seed-tts-eval 语音生成测试中得分为 92.1。
Qwen2.5-Omni-3B的技术原理包括:
 Qwen
Qwen
阿里巴巴推出的一系列AI大语言模型和多模态模型
 118 查看详情
118 查看详情  Thinker-Talker 架构:模型分为“思考者”(Thinker)和“说话者”(Talker)两个部分。Thinker 负责处理和理解多模态输入,生成高级语义表示和文本输出;Talker 基于 Thinker 的输出生成自然语音,确保文本生成和语音输出的同步进行。时间对齐多模态位置嵌入(TMRoPE):通过交错排列音频和视频帧的时间 ID,将多模态输入的三维位置信息编码到模型中,实现视频与音频输入的同步理解。流式处理与实时响应:采用分块处理方法和滑动窗口机制,优化流式生成的效率,使模型能实时生成文本和语音响应。精度优化:支持 FlashAttention 2 和 BF16 精度优化,提升处理速度并降低内存消耗。
Thinker-Talker 架构:模型分为“思考者”(Thinker)和“说话者”(Talker)两个部分。Thinker 负责处理和理解多模态输入,生成高级语义表示和文本输出;Talker 基于 Thinker 的输出生成自然语音,确保文本生成和语音输出的同步进行。时间对齐多模态位置嵌入(TMRoPE):通过交错排列音频和视频帧的时间 ID,将多模态输入的三维位置信息编码到模型中,实现视频与音频输入的同步理解。流式处理与实时响应:采用分块处理方法和滑动窗口机制,优化流式生成的效率,使模型能实时生成文本和语音响应。精度优化:支持 FlashAttention 2 和 BF16 精度优化,提升处理速度并降低内存消耗。
Qwen2.5-Omni-3B的项目地址为:
HuggingFace模型库:https://www.php.cn/link/a4cfff2f82da85e81bb59f671dc8bb1d
Qwen2.5-Omni-3B的应用场景包括:
视频理解与分析:可用于视频内容分析、监控视频解读、智能视频编辑等领域,帮助用户快速提取视频中的关键信息。语音生成与交互:适用于智能语音助手、语音播报系统、有声读物生成等场景,提供自然流畅的语音交互体验。智能客服与自动化报告生成:适用于智能客服系统,能快速解答用户问题并提供解决方案。教育与学习工具:在教育领域,可以辅助教学,通过语音和文本交互帮助学生解答问题、提供学习指导。创意内容生成:能分析图像内容并生成图文结合的创意内容。
以上就是Qwen2.5-Omni-3B— 阿里 Qwen 团队推出的轻量级多模态 AI 模型的详细内容,更多请关注创想鸟其它相关文章!
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 chuangxiangniao@163.com 举报,一经查实,本站将立刻删除。
发布者:程序猿,转转请注明出处:https://www.chuangxiangniao.com/p/256880.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 






















