
4月29日,阿里云正式推出了qwen3系列的8款开源混合推理模型。摩尔线程团队在发布当天便率先完成了对qwen3全系列模型在全功能gpu上的高效支持。这一成就充分展示了musa架构以及全功能gpu在生态兼容性和快速支持能力上的卓越表现。musa架构因其出色的易用性,不仅大大减少了开发者在适配和迁移过程中的工作量,还显著提升了开发效率,为创新成果的快速落地提供了坚实的支持。
Qwen3作为国内首个“混合推理模型”,创新性地将“快思考”和“慢思考”整合进了同一模型,在推理、指令遵循、智能体功能和多语言支持方面取得了突破性的进展。此次开源的两款MoE模型分别是Qwen3-235B-A22B和Qwen3-30B-A3B;同时还包括六个Dense模型:Qwen3-32B、Qwen3-14B、Qwen3-8B、Qwen3-4B、Qwen3-1.7B和Qwen3-0.6B。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜
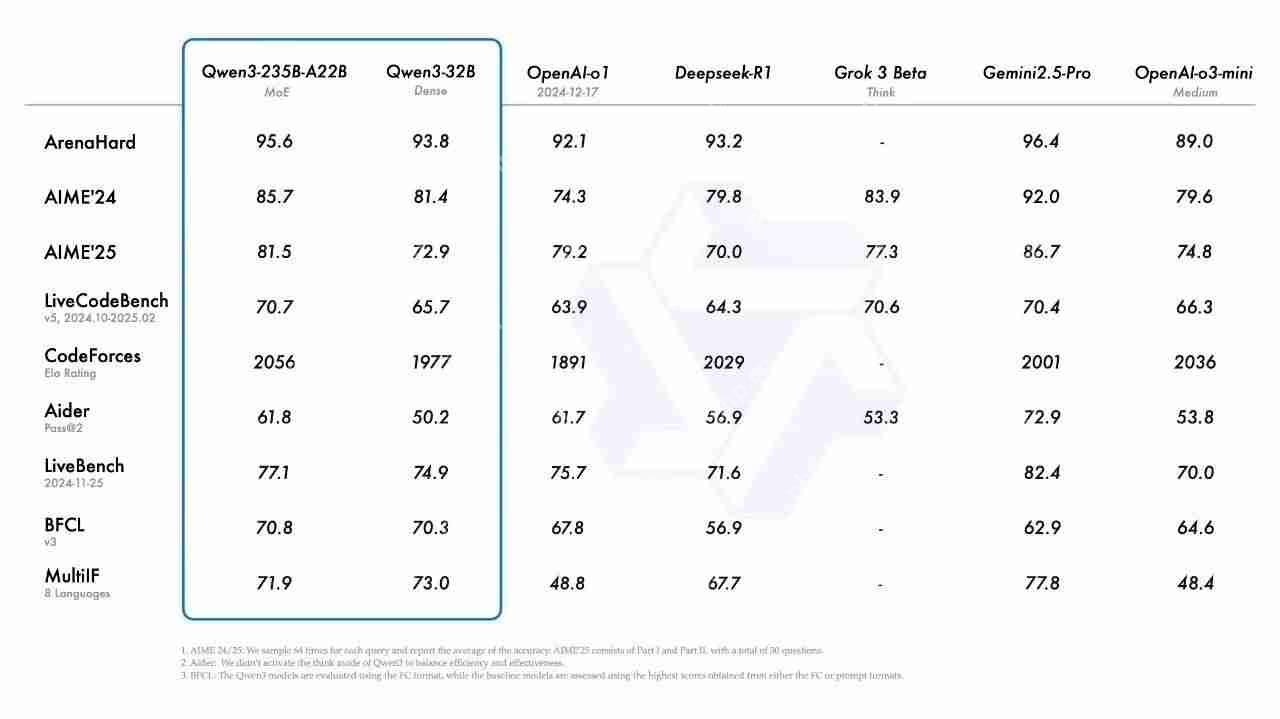
根据官方发布的benchmark测试结果,Qwen3-235B-A22B在代码、数学、通用能力等基准测试中的表现显著优于OpenAI-o1和Deepseek-R1版本。Qwen3-32B在各项测试中的成绩同样优于OpenAI-o3-mini。
快速支持 开放体验Qwen3创新成果
摩尔线程现已在“夸娥工场”开放上线了对Qwen3系列模型的支持成果。“夸娥工场”是摩尔线程精心打造的模型展示与体验中心,旨在为用户提供基于夸娥(KUAE)智算集群支持的模型能力体验。用户可以通过访问夸娥工场,亲自体验Qwen3强大的推理模型性能和创新技术。
▼ 夸娥工场”体验地址:
https://www.php.cn/link/e9cde247132ad24f2a476a6d7a9dbd16
▼ Qwen3体验地址:
https://www.php.cn/link/e9cde247132ad24f2a476a6d7a9dbd16:12074/
目前,主流推理引擎均可基于摩尔线程MUSA平台运行Qwen3系列模型。MUSA平台凭借其卓越性能,能够作为vLLM、Ollama、GPU Stack等各类主流开源推理引擎的后端,为Qwen3系列模型的高效运行提供强大动力。
例如,QWen3-235B-A22B(Qwen3系列最大参数量模型),基于vLLM-MUSA引擎在摩尔线程全功能GPU上稳定运行。

图示:QWen3-235B-A22B模型在vLLM-MUSA引擎适配
同时,GPU Stack引擎与llama.cpp/ollama引擎也在摩尔线程图形显卡MTT S80上高效运行,充分展示了MUSA平台的广泛兼容性与卓越性能。
 百灵大模型
百灵大模型
蚂蚁集团自研的多模态AI大模型系列
 177 查看详情
177 查看详情 

图示:GPU Stack引擎在MTT S80上运行
图示:llama.cpp/ollama引擎在MTT S80上运行
共建开源生态 持续推动国产GPU发展
摩尔线程积极响应开源社区的号召,旨在赋能更多开发者基于国产全功能GPU进行AI应用创新。在通义千问QwQ-32B发布当天,摩尔线程就成功实现了Day-0支持,这一成果充分验证了先进MUSA架构和全功能GPU的技术成熟度与可靠性。
我们诚挚欢迎广大开发者与用户前往“夸娥工场”进行体验,与此同时,开发者也可访问摩尔线程GitHub社区与开发者社区了解更多:
▼ 摩尔线程GitHub开源社区:
https://www.php.cn/link/ff5f900bac84c058978c6b16f895131f
▼ 摩尔线程开发者社区:
https://www.php.cn/link/3aa207e43a501b7a8e06242eb1dfc72d
摩尔线程始终致力于推动开源生态的发展,通过技术开放与生态共建,加速国产全功能GPU在AI计算领域的规模化应用,为更多用户提供更智能、高效的解决方案。
以上就是摩尔线程GPU率先支持Qwen3全系列模型的详细内容,更多请关注创想鸟其它相关文章!
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 chuangxiangniao@163.com 举报,一经查实,本站将立刻删除。
发布者:程序猿,转转请注明出处:https://www.chuangxiangniao.com/p/257571.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 






















