
建库建表插入数据
代码直接按顺序复制就可以
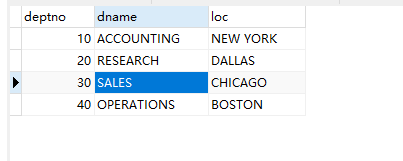
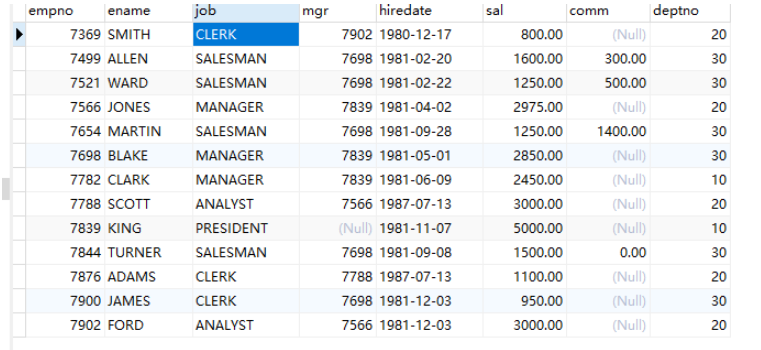
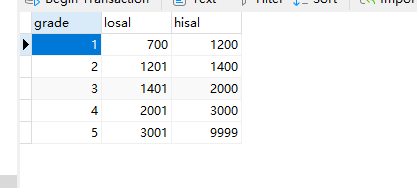
-- 建库CREATE DATABASE `emp`;-- 打开库USE emp;-- 建dept表CREATE TABLE `dept`( `deptno` INT(2) NOT NULL, `dname` VARCHAR(14), `loc` VARCHAR(13), CONSTRAINT pk_dept PRIMARY KEY(deptno) ) ENGINE=InnoDB DEFAULT CHARSET=utf8;-- 键emp表CREATE TABLE `emp` ( `empno` int(4) NOT NULL PRIMARY KEY, `ename` VARCHAR(10), `job` VARCHAR(9), `mgr` int(4), `hiredate` DATE, `sal` float(7,2), `comm` float(7,2), `deptno` int(2), CONSTRAINT fk_deptno FOREIGN KEY(deptno) REFERENCES dept(deptno) ) ENGINE=InnoDB DEFAULT CHARSET=utf8;-- 建salgrade表CREATE TABLE `salgrade` ( `grade` int, `losal` int, `hisal` int ) ENGINE=InnoDB DEFAULT CHARSET=utf8;-- 插入数据INSERT INTO dept VALUES (10,'ACCOUNTING','NEW YORK'); INSERT INTO dept VALUES (20,'RESEARCH','DALLAS');INSERT INTO dept VALUES (30,'SALES','CHICAGO'); INSERT INTO dept VALUES (40,'OPERATIONS','BOSTON');INSERT INTO EMP VALUES (7369,'SMITH','CLERK',7902,'1980-12-17',800,NULL,20); INSERT INTO EMP VALUES (7499,'ALLEN','SALESMAN',7698,'1981-02-20',1600,300,30); INSERT INTO EMP VALUES (7521,'WARD','SALESMAN',7698,'1981-02-22',1250,500,30); INSERT INTO EMP VALUES (7566,'JONES','MANAGER',7839,'1981-04-02',2975,NULL,20);INSERT INTO EMP VALUES (7654,'MARTIN','SALESMAN',7698,'1981-09-28',1250,1400,30); INSERT INTO EMP VALUES (7698,'BLAKE','MANAGER',7839,'1981-05-01',2850,NULL,30); INSERT INTO EMP VALUES (7782,'CLARK','MANAGER',7839,'1981-06-09',2450,NULL,10); INSERT INTO EMP VALUES (7788,'SCOTT','ANALYST',7566,'1987-07-13',3000,NULL,20); INSERT INTO EMP VALUES (7839,'KING','PRESIDENT',NULL,'1981-11-07',5000,NULL,10); INSERT INTO EMP VALUES(7844,'TURNER','SALESMAN',7698,'1981-09-08',1500,0,30); INSERT INTO EMP VALUES (7876,'ADAMS','CLERK',7788,'1987-07-13',1100,NULL,20); INSERT INTO EMP VALUES (7900,'JAMES','CLERK',7698,'1981-12-03',950,NULL,30); INSERT INTO EMP VALUES (7902,'FORD','ANALYST',7566,'1981-12-03',3000,NULL,20); INSERT INTO EMP VALUES (7934,'MILLER','CLERK',7782,'1982-01-23',1300,NULL,10);INSERT INTO SALGRADE VALUES (1,700,1200); INSERT INTO SALGRADE VALUES (2,1201,1400); INSERT INTO SALGRADE VALUES (3,1401,2000); INSERT INTO SALGRADE VALUES (4,2001,3000); INSERT INTO SALGRADE VALUES (5,3001,9999);
dept表:
emp表:
salgrade表:
测试题
1.列出与“SCOTT”从事相同工作的所有员工及部门名称,部门人数。
2. 列出公司各个工资等级雇员的数量、平均工资。
3. 列出薪金高于在部门30工作的所有员工的薪金的员工姓名和薪金、部门名称。
4. 列出在每个部门工作的员工数量、平均工资和平均服务期限。
5. 列出所有员工的姓名、部门名称和工资。
6. 列出所有部门的详细信息和部门人数。
7. 列出各种工作的最低工资及从事此工作的雇员姓名。
8. 列出各个部门的MANAGER(经理)的最低薪金、姓名、部门名称、部门人数。
9. 列出所有员工的年工资,所在部门名称,按年薪从低到高排序。
10. 查出某个员工的上级主管及所在部门名称,并要求出这些主管中的薪水超过3000
11. 求出部门名称中,带‘S’字符的部门员工的、工资合计、部门人数。
12. 给任职日期超过30年或者在87年雇佣的雇员加薪,加薪原则:10部门增长10%,20部门增长20%, 30部门增长30%,依次类推。
13. 列出至少有一个员工的所有部门的信息:
14. 列出薪金比SMITH对的所有员工:
15. 列出所有员工的姓名以及其直接上级的姓名:
16. 列出受雇日期早于其直接上级的所有员工的编号、姓名,部门名称
17. 列出部门名称和这些部门的员工信息,同时列出那些没有员工的部门
18. 列出所有”CLERK(职员)”的姓名以及部门名称,部门的人数
19. 列出最低薪金大于1500的各种工作以及从事此工作的全部雇员人数
20. 列出在部门”SALES”工作的员工的姓名,假定不知道销售部的部门编号
21. 列出薪金高于公司平均薪金的所有员工,所在部门,上级领导,公司的工资等级
22. 列出至少有一个员工的所有部门编号、名称,并统计出这些部门的平均工资、最低工资、最高工 资。
23. 列出薪金比“SMITH”或“ALLEN”多的所有员工的编号、姓名、部门名称、其领导姓名。
24. 列出所有员工的编号、姓名及其直接上级的编号、姓名,显示的结果按领导年工资的降序排列。
25. 列出受雇日期早于其直接上级的所有员工的编号、姓名、部门名称、部门位置、部门人数。
26. 列出部门名称和这些部门的员工信息(数量、平均工资),同时列出那些没有员工的部门。
27. 列出所有“CLERK”(办事员)的姓名及其部门名称,部门的人数,工资等级。
28. 列出最低薪金大于1500的各种工作及此从事此工作的全部雇员人数及所在部门名称、位置、平均工 资。
29. 列出在部门“SALES”(销售部)工作的员工的姓名、基本工资、雇佣日期、部门名称,假定不知道 销售部的部门编号。
30. 列出薪金高于公司平均薪金的所有员工,所在部门,上级领导,公司的工资等级。
31. 列出与“SCOTT”从事相同工作的所有员工及部门名称,部门人数。
 蓝心千询
蓝心千询
蓝心千询是vivo推出的一个多功能AI智能助手
 34 查看详情
34 查看详情 
32. 查询dept表的结构
33. 检索emp表,用is a 这个字符串来连接员工姓名和工种两个字段
34. 检索emp表中有提成的员工姓名、月收入及提成。
答案不唯一,仅供参考
有点乱,直接粘过来的格式不一样大家将就一下,勉强还是能看清的
– 2. 列出公司各个工资等级雇员的数量、平均工资。
show tables; select * from salgrade; select s.grade,count(),avg(e.sal) from emp e left join salgrade s on e.sal between s.losal and s.hisal group by s.grade ;
3. 列出所有薪金高于部门30员工的员工姓名、薪金和所在部门名称。
select ename,sal,d.dname,d.deptno from emp e left join dept d on e.deptno = d.deptno where e.sal > (select max(sal) from emp where deptno = 30);
– 4. 列出在每个部门工作的员工数量、平均工资和平均服务期限。
select count(),avg(sal),avg(year(now())-year(hiredate)) from emp group by deptno;
– 5. 列出所有员工的姓名、部门名称和工资。
SALES research accounting select e.ename,d.dname,e.sal from emp e left join dept d on d.deptno = e.deptno;
– 6. 列出所有部门的详细信息和部门人数。
OPERATIONS select d.,count(e.ename) from dept d left join emp e on e.deptno = d.deptno group by d.deptno;
– 7. 列出各种工作的最低工资及从事此工作的雇员姓名。
select a.ename,t. from emp a left join (select e.job,min(e.sal) from emp e group by e.job) t on a.job = t.job;
– 8. 列出各个部门的MANAGER(经理)的最低薪金、姓名、部门名称、部门人数。
– binary 实现区分大小写 – select ename from emp where job = binary ‘MANAGER'; – select binary ‘a' = ‘a'; – select binary ‘a'; – select binary ‘A'; select * from emp where job = binary ‘MANAGER'; select a.mm,c.ename,c.job,b.dname,b.cc from (select d.deptno,min(sal) mm from emp e left join dept d on e.deptno = d.deptno where job = ‘MANAGER' group by deptno) a left join (select d.deptno,d.dname,count() cc from emp e left join dept d on e.deptno = d.deptno group by d.deptno) b on a.deptno = b.deptno left join emp c on c.sal = a.mm and b.deptno = c.deptno ;
– 9. 列出所有员工的年工资,所在部门名称,按年薪从低到高排序。
select empno,ename,sal12,d.dname from emp left join dept d on d.deptno = emp.deptno order by sal12 asc;
– 10. 查出某个员工的上级主管及所在部门名称,并要求出这些主管中的薪水超过3000
select a.empno,a.ename,b.ename,b.sal from emp a left join emp b on a.mgr = b.empno where b.sal>3000 and a.empno = 7566; select a.empno,a.ename,b.ename,b.sal from emp a left join emp b on a.mgr = b.empno where b.sal>3000; select a.empno,a.ename,b.ename,b.sal from emp a left join emp b on a.mgr = b.empno;
– 11. 求出部门名称中,带‘S’字符的部门员工的、工资合计、部门人数。
select d.dname,count(),sum(e.sal) from emp e left join dept d on e.deptno = d.deptno where d.dname like ‘%s%' group by d.deptno; select * from emp;
– 12. 给任职日期超过30年或者在87年雇佣的雇员加薪,加薪原则:10部门增长10%,20部门增长 20%,30部门增长30%,依次类推。
select empno,ename,sal,sal+sal*(deptno/100) from emp where year(curdate()) - year(hiredate)>30 or year(hiredate)=2022; update emp set sal = sal+sal*(deptno/100) where year(curdate()) - year(hiredate)>30 or year(hiredate)=2022; select * from emp;
– 13. 列出至少有一个员工的所有部门的信息
select distinct d.* from dept d join emp e on d.deptno = e.deptno;
– 14. 列出薪金比SMITH低的所有员工
select * from emp where sal < (select sal from emp where ename = ‘SMITH')
– 15. 列出所有员工的姓名以及其直接上级的姓名:
select a.empno,a.ename,b.ename from emp a left join emp b on a.mgr = b.empno;
– 16. 列出受雇日期早于其直接上级的所有员工的编号、姓名,部门名称
select a.empno,a.ename,b.ename,d.dname from emp a left join emp b on a.mgr = b.empno and a.hiredate<b.hiredate left join dept d on d.deptno = a.deptno;
– 17. 列出部门名称和这些部门的员工信息,同时列出那些没有员工的部门
select * from dept d left join emp e on d.deptno = e.deptno;
– 18. 列出所有”CLERK(职员)”的姓名以及部门名称,部门的人数
select a.ename,a.job,b.dname,b.cc from emp a join (select d.deptno,d.dname,count() cc from dept d left join emp e on d.deptno = e.deptno group by d.deptno) b on b.deptno = a.deptno and a.job = ‘CLERK';
– 19. 列出最低薪金大于1500的各种工作以及从事此工作的全部雇员人数
select job,max(sal),min(sal),avg(sal),count() from emp where sal>1500 group by job;
– 20. 列出在部门”SALES”工作的员工的姓名,假定不知道销售部的部门编号
select ename from emp where deptno in (select deptno from dept where dname=‘sales'); select e.ename from emp e join dept d on e.deptno = d.deptno and d.dname=‘sales';
– 21. 列出薪金高于公司平均薪金的所有员工,所在部门,上级领导,公司的工资等级
select a.ename,a.en,d.dname,a.sal,s.grade from (select a.deptno,a.ename,b.ename en,a.sal from emp a join emp b on a.mgr = b.empno and a.sal>(select avg(sal) from emp)) a left join dept d on a.deptno=d.deptno left join salgrade s on a.sal between s.losal and s.hisal; select a.ename,b.ename from emp a join emp b on a.mgr = b.empno and a.sal> (select avg(sal) from emp);
– 22. 列出至少有一个员工的所有部门编号、名称,并统计出这些部门的平均工资、最低工资、最高 工资。
select e.deptno,d.dname,avg(e.sal),max(e.sal),min(sal),count() from dept d join emp e on e.deptno = d.deptno group by e.deptno;
– 23. 列出薪金比“SMITH”或“ALLEN”多的所有员工的编号、姓名、部门名称、其领导姓名。
select a.empno,a.ename,d.dname,b.ename from (select * from emp where sal >(select min(sal) from emp where ename in (‘smith',‘allen'))) a left join emp b on a.mgr = b.empno left join dept d on d.deptno = a.deptno;
– 24. 列出所有员工的编号、姓名及其直接上级的编号、姓名,显示的结果按领导年工资的降序排 列。
select a.empno,a.ename,a.sal12,b.empno,b.ename,b.sal12 from emp a left join emp b on a.mgr = b.empno order by b.sal12;
– 25. 列出受雇日期早于其直接上级的所有员工的编号、姓名、部门名称、部门位置、部门人数。
select a.empno,a.ename,b.ename,d.dname from emp a left join emp b on a.mgr = b.empno and a.hiredate<b.hiredate left join dept d on d.deptno = a.deptno;
– 26. 列出部门名称和这些部门的员工信息(数量、平均工资),同时列出那些没有员工的部门。
select d.deptno,d.dname,count(e.ename),avg(sal) from dept d left join emp e on d.deptno = e.deptno group by d.deptno;
– 27. 列出所有“CLERK”(办事员)的姓名及其部门名称,部门的人数,工资等级。
select a.ename,a.job,b.dname,b.cc from emp a join (select d.deptno,d.dname,count() cc from dept d left join emp e on d.deptno = e.deptno group by d.deptno) b on b.deptno = a.deptno and a.job = ‘CLERK'; select e.deptno,count(e.deptno) from (select a.deptno,a.ename,d.dname,s.grade from (select deptno,ename,sal from emp where job=‘CLERK') a left join dept d on a.deptno=d.deptno left join salgrade s on a.sal between s.losal and s.hisal) aa left join emp e on aa.deptno = e.deptno group by e.deptno; select t1.,t2.deptcount from (select d.deptno,e.ename,e.job,d.dname,s.grade from emp e join dept d on e.deptno = d.deptno join salgrade s on e.sal between s.losal and s.hisal where e.job = ‘CLERK') t1 join (select deptno, count() as deptcount from emp group by deptno) t2 on t1.deptno = t2.deptno;
– 28. 列出最低薪金大于1500的各种工作及此从事此工作的全部雇员人数及所在部门名称、位置、 平均工资。
select job,max(sal),min(sal),avg(sal),count() from emp where sal>1500 group by job;
– 29. 列出在部门“SALES”(销售部)工作的员工的姓名、基本工资、雇佣日期、部门名称,假定 不知道销售部的部门编号。
select e.ename,e.sal,e.hiredate,d.dname from emp e join dept d on d.deptno = e.deptno and d.dname=‘sales';
– 30. 列出薪金高于公司平均薪金的所有员工,所在部门,上级领导,公司的工资等级。
select a.ename,a.en,d.dname,a.sal,s.grade from (select a.deptno,a.ename,b.ename en,a.sal from emp a join emp b on a.mgr = b.empno and a.sal>(select avg(sal) from emp)) a left join dept d on a.deptno=d.deptno left join salgrade s on a.sal between s.losal and s.hisal;
– 31. 列出与“SCOTT”从事相同工作的所有员工及部门名称,部门人数。
create view v1 as select b.ename,d.dname,a.cc from (select deptno,count(*) cc from emp group by deptno) a join (select ename,deptno from emp where job = (select job from emp where ename = ‘scott')) b on b.deptno=a.deptnoleft join dept d on d.deptno = b.deptno; select * from v1;
– 32. 查询dept表的结构
desc emp; describe emp; show create table emp; show columns from emp;
– 33. 检索emp表,用is a 这个字符串来连接员工姓名和工种两个字段 is a 是oracle数据库
select concat(empno,ename,job) from emp; select concat_ws(‘-',empno,ename,job) from emp; select distinct job from emp; select group_concat(distinct job) from emp; select group_concat(distinct ename) from emp; select group_concat(distinct job order by job asc separator ‘=') from emp;
– 34. 检索emp表中有提成的员工姓名、月收入及提成。
select ename,sal,comm from emp where comm is not null; select ename,sal,comm from emp where comm is not null and comm>0;
以上就是MYSQL复杂查询方法实例分析的详细内容,更多请关注创想鸟其它相关文章!
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 chuangxiangniao@163.com 举报,一经查实,本站将立刻删除。
发布者:程序猿,转转请注明出处:https://www.chuangxiangniao.com/p/260969.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 



















