
4月16日,北京理工大学陈鹏万教授团队在small期刊上发表了一篇关于超快合成单原子催化剂的综述文章,题为“ultrafast synthesis of single-atom catalysts for electrocatalytic applications”。文章详细总结了超快合成单原子催化剂(sacs)的技术及其在电催化领域的应用,并介绍了团队近期在脉冲放电法上的创新成果。论文的共同通讯作者包括北京理工大学的陈鹏万教授、陈文星副教授、高鑫副教授,首都师范大学的陈郑博副教授以及蚌埠学院的高燕老师,硕士生周博然和博士生刘开源为共同第一作者。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

单原子催化剂因其极高的原子利用率和均一的活性位点,成为能源催化领域的热点研究方向之一。然而,金属原子在制备过程中易因高表面能而迁移聚集,传统方法依赖复杂步骤和长时间的热解,难以实现单原子催化剂的高效、低成本制备。
针对这些挑战,团队总结了近年来超快合成单原子催化剂的策略,利用瞬时高能量冲击(如焦耳加热、微波辐射、脉冲放电等)在短时间内实现金属原子的精准锚定,同时避免基底材料的热损伤,为SACs的高效合成开辟了新途径。此外,还总结了超快合成单原子催化剂方法的优势及其在电催化应用中的表现(图1)。
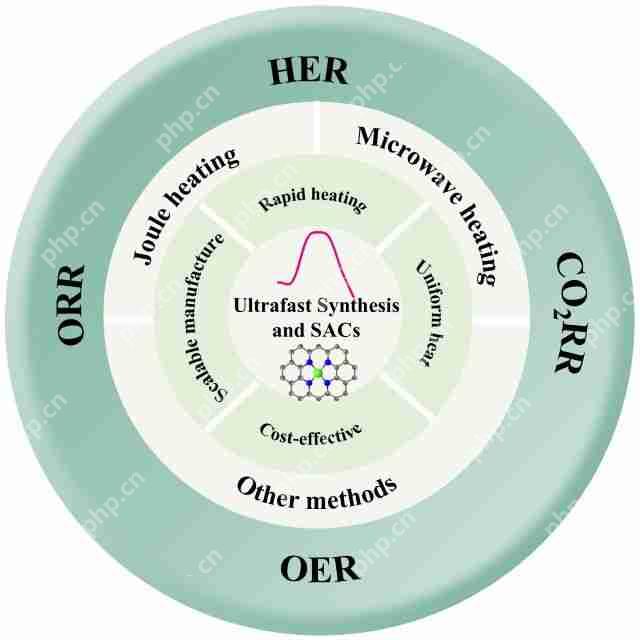
图1 超快合成单原子催化剂策略饼状图
 酷表ChatExcel
酷表ChatExcel
北大团队开发的通过聊天来操作Excel表格的AI工具
 48 查看详情
48 查看详情 
团队详细回顾了超快合成单原子催化剂的发展历程(图2),从微波法、焦耳热法快速合成单原子催化剂,到最近陈鹏万教授团队开发的脉冲放电法,该方法可以在百微秒内合成高分散、高稳定性的非对称配位结构单原子催化剂。脉冲放电法还可以轻松扩展到双原子催化剂和负载型纳米团簇催化剂的高效、低成本合成。
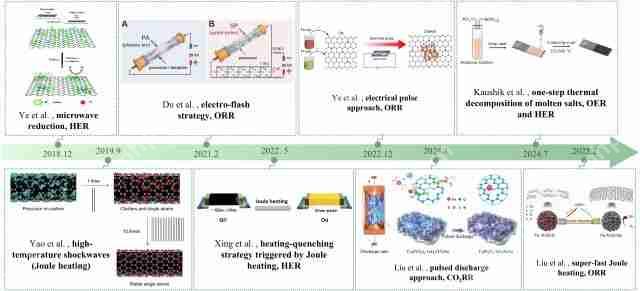
图2 超快合成单原子催化剂发展历程
近年来,超快合成单原子催化剂方法发展迅速,为高效、大规模制备单原子催化剂提供了新的解决方案。本综述不仅系统分析了焦耳热法、微波法、脉冲放电法等超快合成单原子催化剂策略的机制和特点,还探讨了其在规模化生产中的潜力。未来,超快合成单原子催化剂技术有望应用于绿氢制备、燃料电池和碳资源转化等领域,并与可再生能源电力资源相结合,助力实现“双碳”战略目标。
以上就是北理工团队在Small期刊发表超快合成单原子催化剂的综述文章的详细内容,更多请关注创想鸟其它相关文章!
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 chuangxiangniao@163.com 举报,一经查实,本站将立刻删除。
发布者:程序猿,转转请注明出处:https://www.chuangxiangniao.com/p/263860.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 


























