聚类热图的分支结构会因不同的聚类算法和距离计算方式而有所不同。在保持分支结构不变的前提下,我们有时需要调整热图分支的顺序,以满足特定的需求。这就是文章聚类热图如何按自己的意愿调整分支顺序的出发点。
现在,这种功能已经移植到BIC平台,具体操作如下:
使用之前的绘图数据:
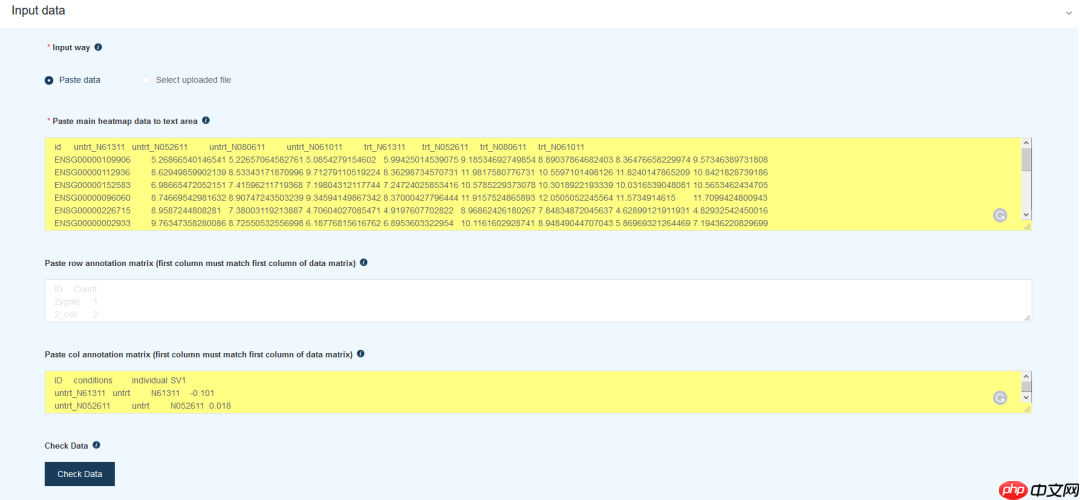
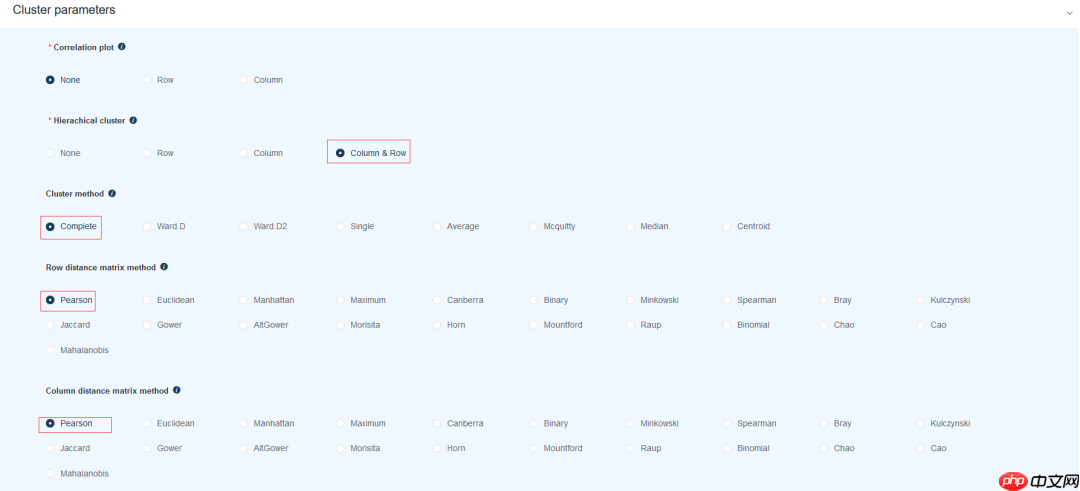
采用默认的绘图参数:
生成的热图效果不错:
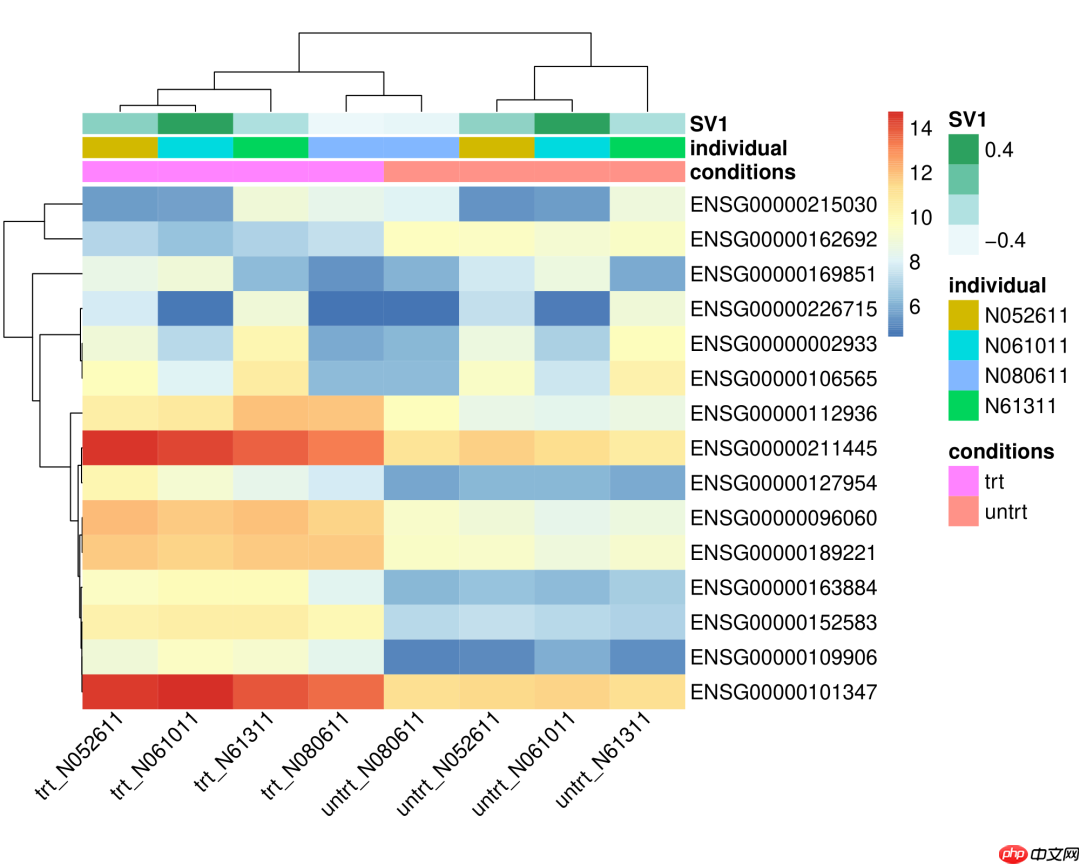
现在我们希望调整列的顺序,通常习惯将对照组放在前面,处理组放在后面。我们在colWright列下添加了权重信息,在不影响层级聚类结构的基础上(层级聚类中,哪两个/两组样品在同一分支下是不可改变的,但同一分支下的两个/两组样品谁在左、谁在右是无关紧要的),权重大的列排在左侧,权重小的列排在右侧。
在colWright列下,我们添加了权重信息:
ID conditions individual SV1 ColWeightuntrt_N61311 untrt N61311 -0.101 80untrt_N052611 untrt N052611 0.018 100untrt_N080611 untrt N080611 -0.429 70untrt_N061011 untrt N061011 0.535 90trt_N61311 trt N61311 -0.125 40trt_N052611 trt N052611 0.036 60trt_N080611 trt N080611 -0.467 70trt_N061011 trt N061011 0.533 50
我们希望的排序顺序为:
untrt_N052611untrt_N061011untrt_N61311untrt_N080611trt_N080611trt_N052611trt_N061011trt_N61311
拷贝数据并设置参数,主要包括:
Column used for reorder row cluster branches:选择哪一列作为行聚类排序的权重列Column used for reorder column cluster branches:选择哪一列作为列聚类排序的权重列Exclude order variable from row annotation:这一列有时是自己编的值,只是拿来美化图,而不希望展示,可以通过该参数隐去Exclude order variable from column annotation:这一列有时是自己编的值,只是拿来美化图,而不希望展示,可以通过该参数隐去

提交后获得结果,顺序如我们期望:
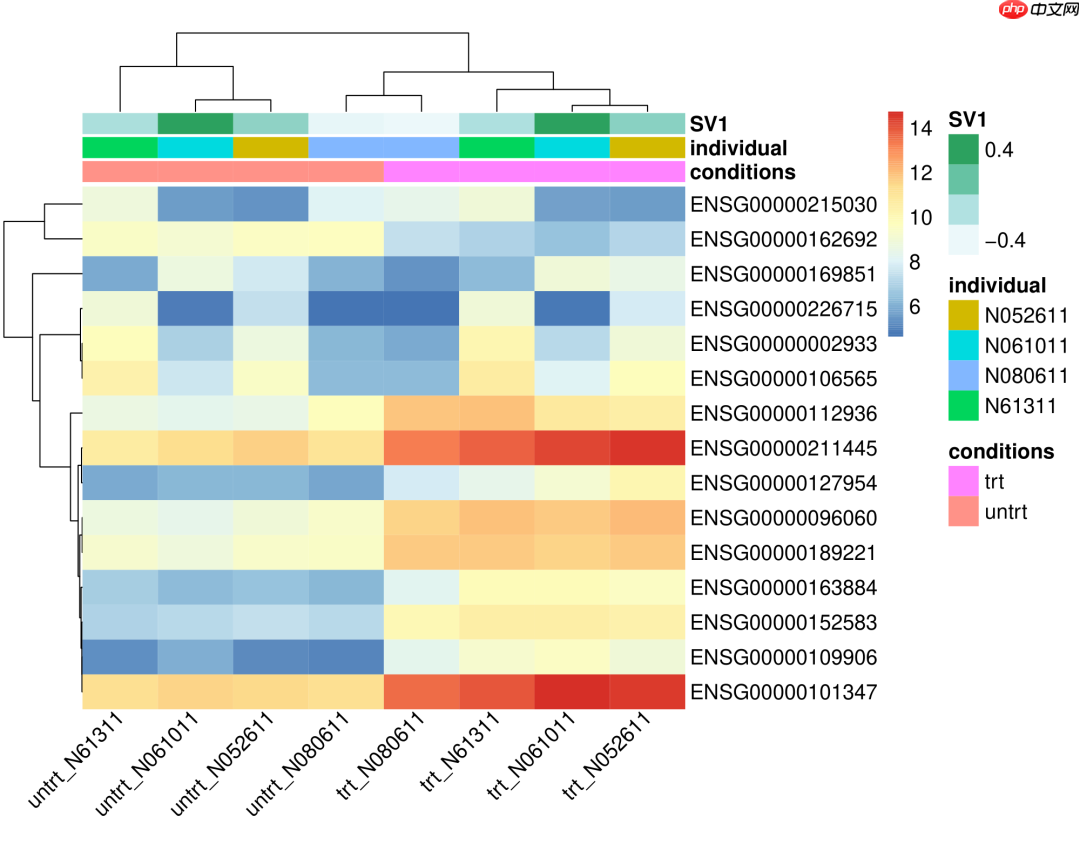
如果调整时未达到预期效果,首先检查是否改变了分支结构;如果没有改变结构但依然无效果,则可以尝试加大不同样品权重的差距,以获得预期的排序效果。
这是调整分支顺序的一种方式,文章聚类热图如何按自己的意愿调整分支的顺序还提供了许多其他排序方式可供参考和使用。
以上就是无代码调整聚类热图分支顺序的详细内容,更多请关注创想鸟其它相关文章!
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 chuangxiangniao@163.com 举报,一经查实,本站将立刻删除。
发布者:程序猿,转转请注明出处:https://www.chuangxiangniao.com/p/26527.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫