
1索引的概念
1.1定义
索引在关系型数据库中,是一种单独的、物理的对数据库表中的一列或者多列值进行排序的一种存储结构,它是某个表中一列或者若干列值的集合,还有指向表中物理标识这些值的数据页的逻辑指针清单。
索引的作用相当于图书的目录,可以根据目录重点页码快速找到所需要的内容,数据库使用索引以找到特定值,然后顺着指针找到包含该值的行,这样可以是对应于表的sql语句执行得更快,可快速访问数据库表中的特定信息。
1.2类型
InnoDB包含三种索引类型,分别为普通索引、唯一索引(主键索引为一种特殊的非空唯一索引)、全文索引。
重写为:普通索引又称非唯一索引,没有任何限制。唯一(Unique):唯一索引要求键值不能重复(可以为空),主键索引其实是一种特殊的唯一索引,不过他还多了一个限制条件,要求键值不能为空。主键索引用 primary key 创建。全文(Fulltext):针对比较大的数据,比如我们存放是文章,课文,邮件,等等,有可能一个字段就需要几kb,如果要解决like查询在全文匹配的时候效率低下的问题,可以创建全文索引。仅限于char、varchar、text类型的字段可创建全文索引。MyISAM和InnoDB都支持全文索引。
1.3作用
一句话总结:
索引能够提高数据检索的效率,降低数据库的IO成本。
提出问题:我们用空间换时间,但是他的数据结构、查询的IO成本、以及是如何存储数据的呢?
2索引的数据结构B+树的演进过程
我们以一个 Page 的视角去看我们的B+树演进过程。
页是InnoDB管理存储空间的基本单位,InnoDB将数据库中的数据都是存储在页这个基本存储单位⾥的;页也是内存和磁盘交互的基本单位,数据库从磁盘中读取若⼲个页⼤⼩的数据到内存,也将内存中若⼲个页⼤⼩的数据刷新到磁盘中。⼀个页的内存⼤⼩为16KB。
假设我们要执行这个SQL,得到了10条记录:
SELECT * FROM INNODB_USER LIMIT 0 , 10;
假如一条记录的数据大小是4K,那么我们一个Page页能存多少条数据呢?
16K 除以 4K 得到 4条记录,对吧。
Page里面的每一条数据都有一个关键的属性叫做record_type
0 普通用户记录 1 目录的索引记录 2 最小 3 最大
画个图示例一下页里面数据是怎么放的:
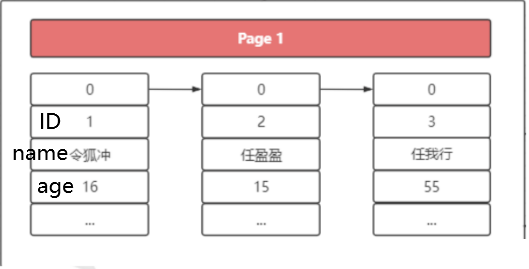
这个是我们的Page页,每个Page页都会存放数据,按照主键有序存放数据
我们知道数据的存储是顺序IO的,方便存放,可是存放方便那查询是不是就不方便了,如果查的是最后一个是不是要遍历整个页的数据?
2.1问题
假如我们要查一条数据要怎么查?怎么才能快速查到数据?
如果我们Page页中的数据是有连接方式的,想想我们学过的数据结构,哪种结构查询快?
如果我们Page页中的数据是有连接方式的,就能够解决啊!没错,就是链表
Page页中的数据是怎么连接的(数据在同一个页中):
MySQL把页中的数据通过单向链表连接起来,如果是根据主键去查询,使用二分法定位会非常快,如果是根据非主键索引去查,只能从最小的一个个开始遍历单向链表。
多个Page页是怎么建立连接(数据在不同的页中):
MySQL把不同的页通过双向向链表建立链接,这样我们就可以通过上一页找到下一页,通过下一页找到一页,由于我们现在不能快速定位到数据的所在页,我们只能从第一个页沿着双向链表一直往下找,在每个页中再按照在同一页的方式去查找指定的记录,这个也是全表扫描嘛。

2.2问题
当Page页越来越多,查询会出现什么问题、怎么解决怎么优化?
当我们链表记录变多,由于不能直接定位,我们出现了查询缓慢问题,深入思考,所谓的查询缓慢,其实就是下面两个问题:
查询时间的复杂度0(N)
读写磁盘的IO次数过多
我们想一下,平时看书时,想找某一页的资料,怎么做的?
查目录对不对?目录是个啥?不就是索引嘛!
百度上随便找个目录,贴个图:

我们发现,这个目录里面有两个很重要的信息:
内容简介(章节标题)
所在的页码
我们这个我们参考一个图书的目录的思想来达到我们快速查询数据的目的:
给数据加一个目录,查数据,我们先根据目录页找到数据在哪个页的哪个地方,提升查询性能。
可是,
2.3问题:怎么建目录呢?给每一个页都建一个目录吗?
建目录是不是要有规律?比如字典的目录就是根据字母顺序建立的,你想到了什么?没错就是主键,Mysql里自增的主键刚好符合我们的要求,有规律,内容还少,而且不可重复,真是完美的目录,我们将每一页的主键按规律存储一下,添加一个指针指向数据的位置,查询时直接根据主键大小,用二分法快速找到目录,然后找到数据。
但是我们要给每一个数据页都建目录吗?好像还必须如此,不给每一个页建数据,你怎么定位到页里的数据?难道全页扫描吗?
但是给每一个页都建目录,随着目录页也出现多个,我们一个个目录也去遍历查询性能也会下降。
我们可不可以给目录建一个目录?
于是,我们可以通过为目录页也建立一次目录,向上抽取一层根结点,这样就更加便于我们进行查询了。
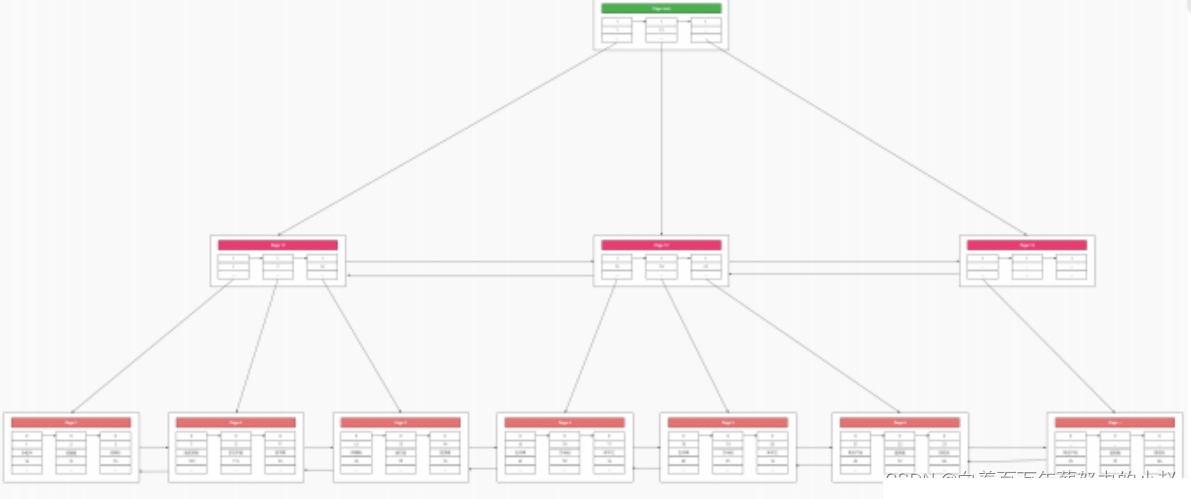
这棵树,因为是根据主键存储的,所以我们把它称之为主键索引树,因为主键索引树里存储了我们的表里的所有数据,那么在MySQL中 索引即数据,数据即索引也是这个原因了。
这就是MysqlB+树主键索引树的数据结构,怎么样,是不是比你直接死记硬背得到的知识印象更深刻
2.4索引树、页的分裂与合并
我们找到了提升查询性能的办法,那么,当Page页出现增加、修改、删除,都会遇到什么问题?
如果是有序增加,新增一条数据怎么办?
页写满了,那么是不是得开启一个新页!
并且页的数据必须满足一个条件:下一个数据页中用户记录的主键值必须大于上一个页中用户记录的主键值
因为是有序增加,我们直接在页的双向链表末端增加一个页即可。
那如果是无序增加,新增一条数据怎么办?
 飞书知识问答
飞书知识问答
飞书平台推出的AI知识库管理和智能搜索工具
 45 查看详情
45 查看详情 
开启一个新页,并且找到数据的位置。
把旧数据移动到新页,把新的数据放到有序的位置上。
叶子结点数据一直平移。
触发叶子结点数据Page页的分裂与合并触发上层叶结点和根结点的再次分裂与合并。
这叫什么,“牵一发而动全身”,也叫做页分裂!!
总结:Page页出现增加、修改、删除遇到的问题:
我们可以说,当无序增加、更新主键ID、删除索引页的更新操作时候,会有大量的树结点调整,触发子叶结点Page页和上层叶结点和根节点页的分页与合并,造成大量磁盘碎片,损耗数据库的性能,也就是解释了我们为什么不要在频繁更新修改的列上建索引,或者是不要去更新主键。
让我们总结一下:
聚集索引(聚簇索引):
主键索引树也叫聚集索引或者是聚簇索引,在InnoDB中一张表只有一个聚集索引树,如果一张表创建了主键索引,那么这个主键索引就是聚集索引,我们是根据聚集索引树的键值,决定数据行的物理存储顺序,我们的聚集索引会对表中的所有列进行排序存储,索引即数据,数据即索引,指的就是我们的主键索引树啦。
2.5根据我们刚才推演的,延申出几个面试题
为什么主键ID最好是趋势递增的?
你刚刚看完啊,不会没记住吧,有序递增,下一个数据页中用户记录的主键值必须大于上一个页中用户的主键值,假如我是趋势递增,存入的数据肯定是在最末尾链表或者新增一个链表,就不会触发页的分裂与合并,导致添加的速度变慢。
三层B+数能存多少数据?
考察点:Page页的大小,B+树的定义
1GB = 1024 M, 1mb = 1024k,1k= 1024 bytes
答:
已知:索引逻辑单元 16bytes 字节,16KB=16* 1024*1024,肯定比一千万多,在InnoDB中B+树的深度为3层就能满足千万级别的数据存储。
mysql 大字段为什么要拆分?
一个Page页可存放16K的数据,大字段占用大量的存储空间,意味着一个Page页可存储的数据条数变少,那么就需要更多的页来存储,需要更多的Page,意味着树的深度会变高。那么磁盘IO的次数会增加,性能下降,查询更慢。大字段不管是否被使用都会存放在索引上,占据大量内存空间压缩Page数据条数。
为什么用B+树?
B+树的底层是多路平衡查找树,对于每一次的查询的都是从根节点触发,到子叶结点才存放数据,根节点和非叶子结点都是存放的索引指针,查找叶子结点互,可以根据键值数据查询。具备更强的扫库、扫表能力、排序能力以及查询效率和性能的稳定性,存储能力也更强,仅使用三层B+树就能存储千万级别的数据。
3什么是二级索引树
刚才看的是根据主键得来的索引,我们如果不查主键,或者说表里压根就没有主键,怎么办?我们还可以根据几个字段来创建联合索引(组合索引聚合索引。。哎呀名字而已怎么叫都行)。
根据主键得到的索引树叫主键索引树,根据别的字段得到的索引树叫二级索引树。
通过下面的SQL 可以建立一个组合索引
ALTER TABLE INNODB_USER ADD INDEXSECOND_INDEX_AGE_USERNAME_PHONE('age','user_name','phone');
其实,看似建立了1个索引,但是你使用 age 查询 age,user_name 查询 age,user_name,phone 都能生效
您也可以认为建立了三个这样的索引:
ALTER TABLE INNODB__USER ADD INDEXSECOND_INDEX_AGE__USERNAME_PHONE('age');ALTER TABLE INNODB_USER ADD INDEXSECOND_INDEX_AGE_USERNAME_PHONE('age','user_name');ALTER TABLE `INNODB_USER`ADD INDEXSECOND_INDEX_AGE_USERNAME_PHONE('age','user_name','phone');
3.1那么二级索引树怎么排序?
首先需要知道参与排序的字段类型是否有有序?
如果是有序字段,就按照有序字段排序比如(int) 1 2 3 4。
如果是无序字段,按照这个列的字符集的排序规则来排序,这点不去深入,知道就好。
我现在有一个组合索引(A-B-C)他会按照你建立字段的顺序来进行排序:
如果A相同按照B排序,如果B相同按照C排序,如果ABC全部相同,会按照聚集索引进行排序。
我们的Page会根据组合索引的字段建立顺序来存储数据,年龄 用户名 手机号。
它的数据结构其实是一样的
3.2索引桥的概念是什么呢(最左匹配原则)?
还是上面那个索引,年龄用户名手机号,age,username,phone
那么可以看到我们第一个字段是AGE,如果需要这个索引生效,是不是在查询的时候需要先使用Age查询,然后如果还需要user_name,就使用user_name。
只使用了user_name 能使用到索引吗?
其实是不行的,因为我是先使用age进行排序的,你必须先命中age,再命中user_name,再命中phone,这个其实
就是我们所说的最左匹配原则。
最左其实就是因为我们是按照组合索引的顺序来存储的。大家常说的”索引桥”也是这个原因。在命中组合索引中,必须像过桥一样,先跨过第一块木板,再到第二块木板,最后到第三块木板。
3.3回表、覆盖索引、索引下推
二级索引树有三个重要的概念,分别是回表、覆盖索引、索引下推。.
回表就是:我们查询的数据不在二级索引树中需要拿到ID去主键索引树找的过程。
覆盖索引就是:我们需要查询的数据都在二级索引树中,直接返回这种情况就叫做覆盖索引。
索引下推(index condition pushdown )简称ICP:在Mysql5.6以后的版本上推出,用于优化回表查询;
3.4延申几个面试题:
为什么离散度低的列不走索引?
离散度是什么概念?相同的数据越多离散度越低,相同的数据越少离散度就越高。
请问都是相同的数据,怎么排序?没办法排序啊?
在B+Tree 里面重复值太多,MySQL的优化器发现走索引跟使用全表扫描差不了多少的时候,就算建立了索引也不会走。走不走索引,是MySQL的优化器去决定的。
索引是不是越多越好?
空间上:用空间换时间,索引是需要占用磁盘空间的。
时间上:命中索引,加快我们的查询效率,如果是更新删除,会导致页的分裂与合并,影响插入和更新语句的响应时间,反而延缓性能。
如果是频繁需要更新的列,不建议建立索引,因为频繁触发页的分裂与合并。
3.5二级索引树的总结
也叫作组合索引(复合索引),二级索引树存储的是我们创建索引时候的保存了列名顺序来存储的,它只保存了创建二级索引列名的部分数据,二级索引树是为了辅助我们查询,提高查询效率诞生的,二级索引树里有三个动作:回表、覆盖索引、索引下推。其中,性能最高的是覆盖索引。
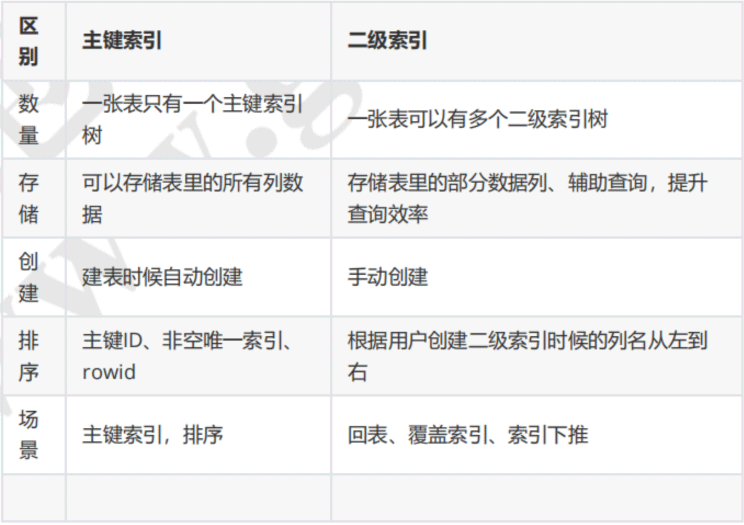
4主键索引与二级索引的区别
网上找了一张区别图
以上就是MySQL索引知识点分析的详细内容,更多请关注创想鸟其它相关文章!
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 chuangxiangniao@163.com 举报,一经查实,本站将立刻删除。
发布者:程序猿,转转请注明出处:https://www.chuangxiangniao.com/p/269893.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 



















