
kafka 的高性能设计可以说是无微不至,从生产者(producer)、到代理(broker)、再到消费者(consumer),kafka 在每一个细节上都精心优化,最终实现了极致的性能。
本文将首先带领大家建立高性能设计的思维模式,然后深入探讨 Kafka 的高性能设计方案,最终帮助大家系统地掌握所有知识点,并理解其设计哲学。
如何理解高性能设计?
让我们暂时搁置 Kafka,先尝试理解高性能设计的本质。
对于有高并发开发经验的同学来说,线程池、多级缓存、IO 多路复用、零拷贝等技术概念已经非常熟悉,但回归本质,这些技术手段的核心是什么?
这是一个系统性的问题,至少需要深入到操作系统层面,从 CPU 和存储入手,了解底层的实现机制,然后自底向上,一层一层地解密和贯穿。
但从更高的视角来看,我认为高性能设计的本质始终不变,一定是从“计算和 IO”这两个维度出发,去考虑可能的优化点。
那么,“计算”维度的性能优化手段有哪些呢?主要有两种方式:
再来看“IO”维度的性能优化手段,可以通过 Linux 系统的 IO 栈图来辅助思考。
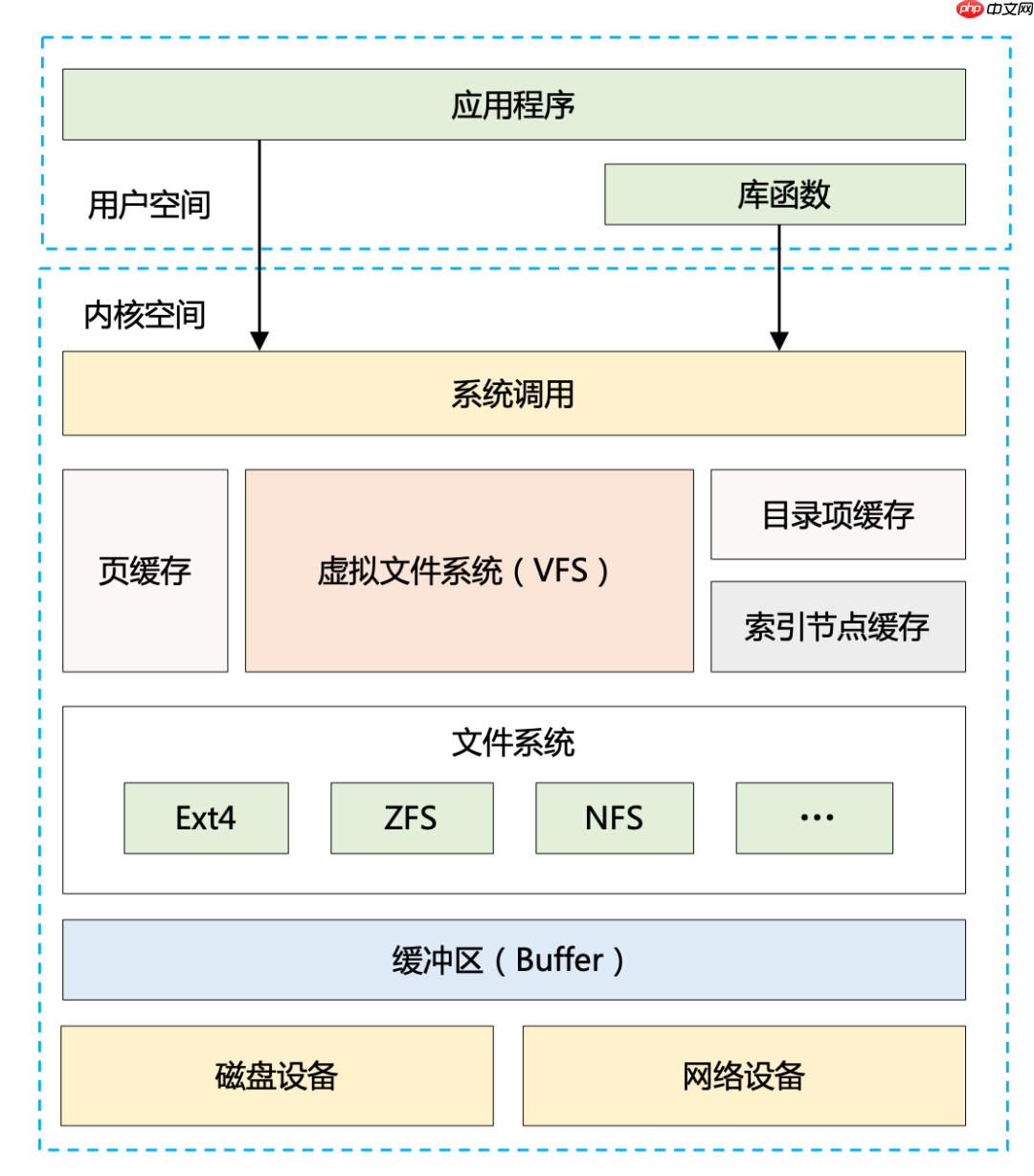 图 1:Linux 系统的 IO 栈图
图 1:Linux 系统的 IO 栈图


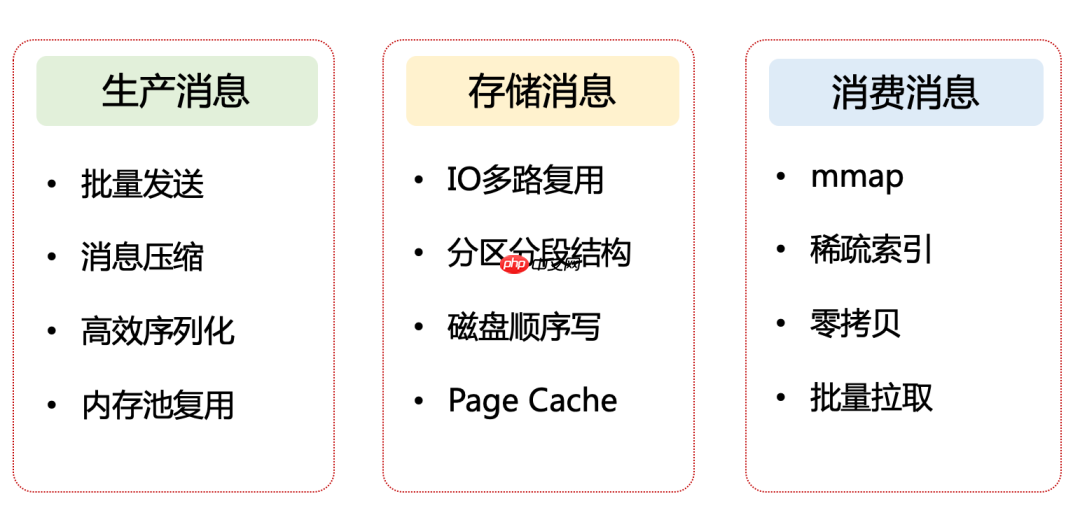


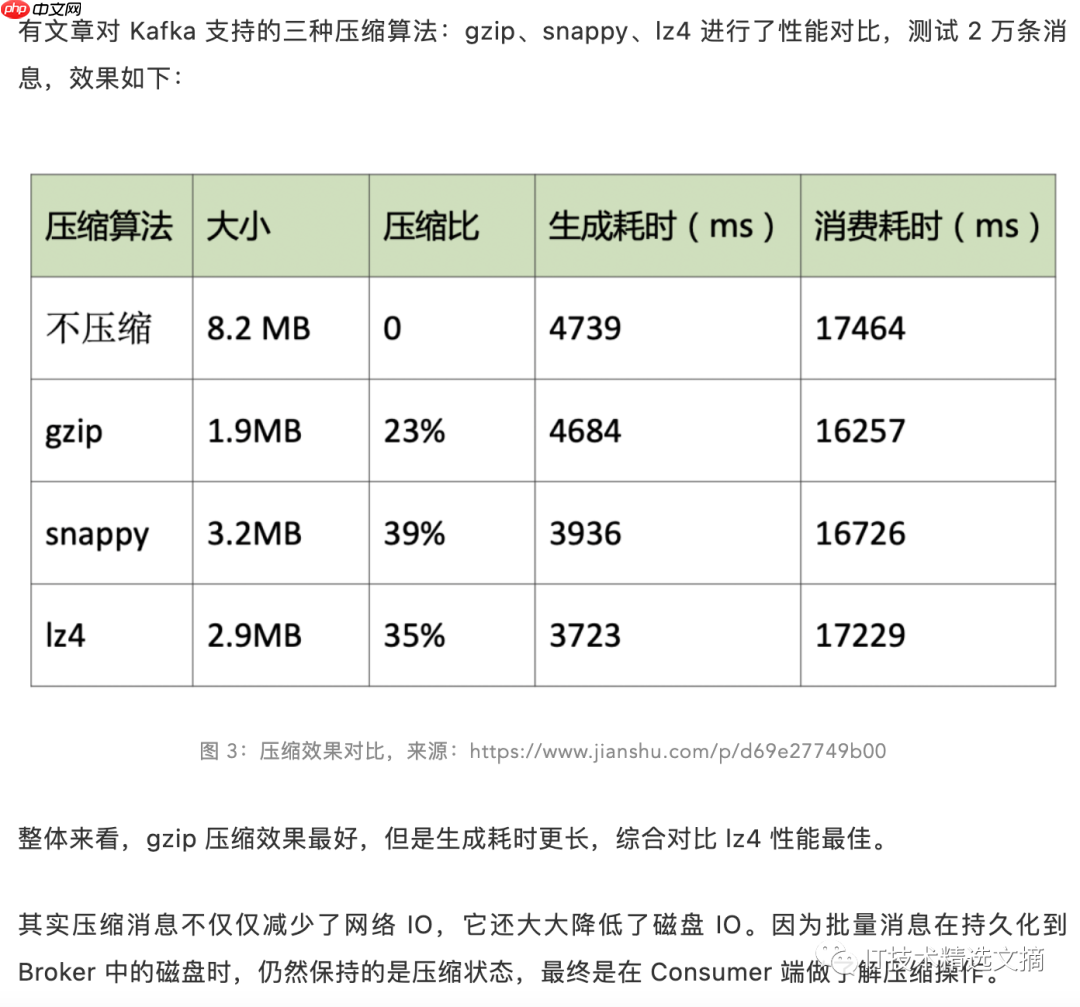

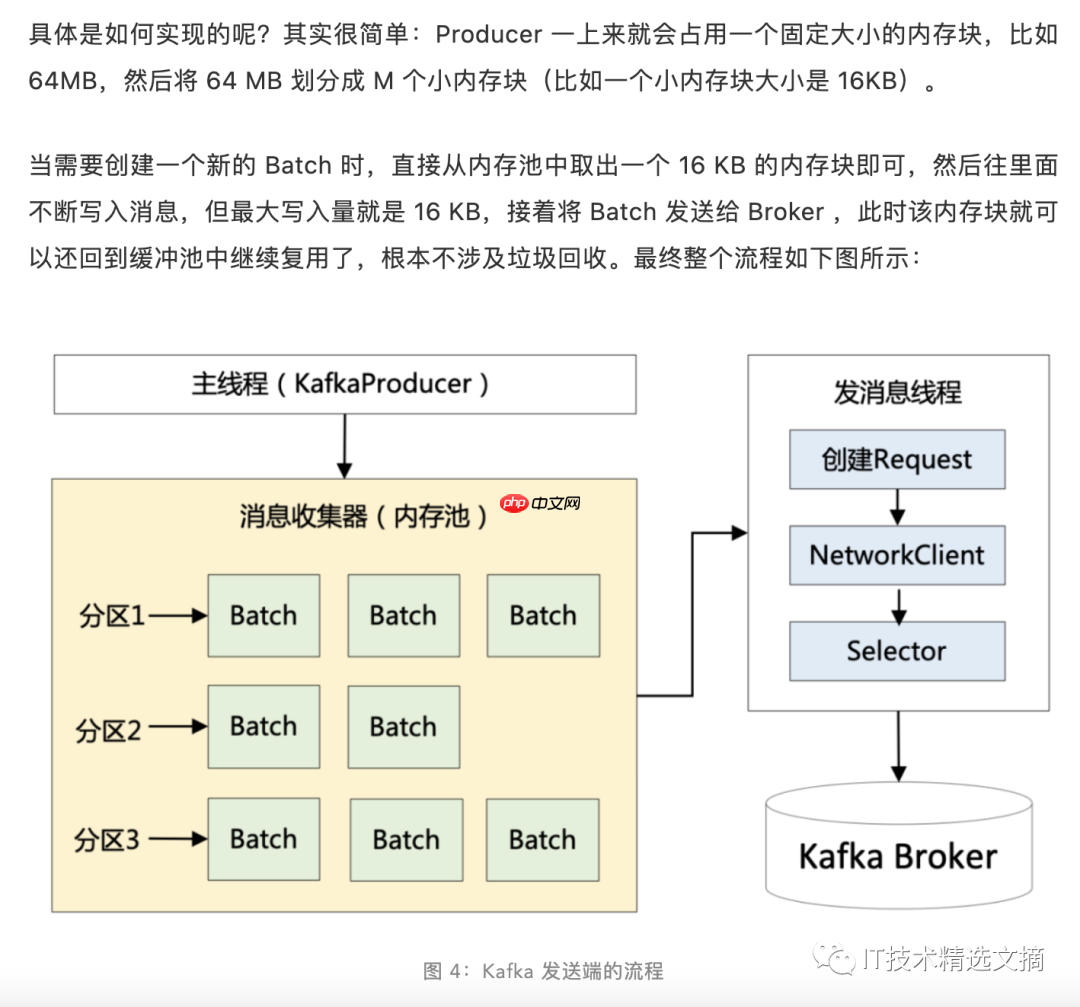

以上就是Kafka 精妙的高性能设计(上篇)的详细内容,更多请关注创想鸟其它相关文章!
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 chuangxiangniao@163.com 举报,一经查实,本站将立刻删除。
发布者:程序猿,转转请注明出处:https://www.chuangxiangniao.com/p/27117.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 





















