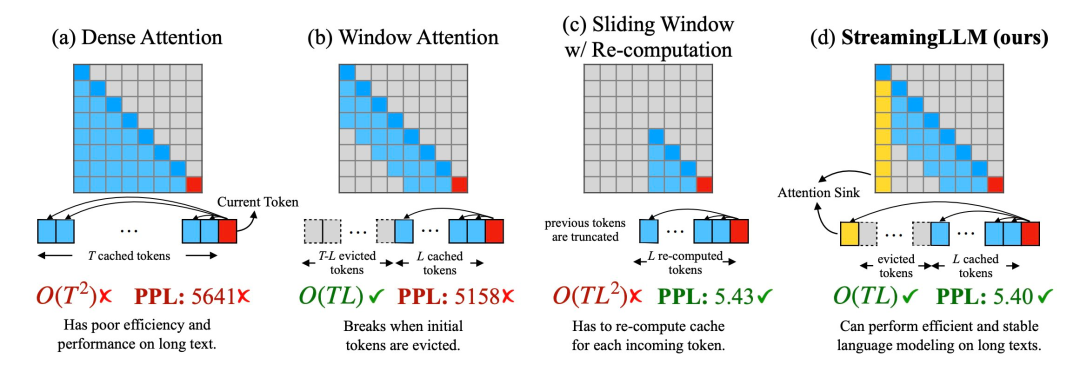
omnicam:革新多模态视频生成框架
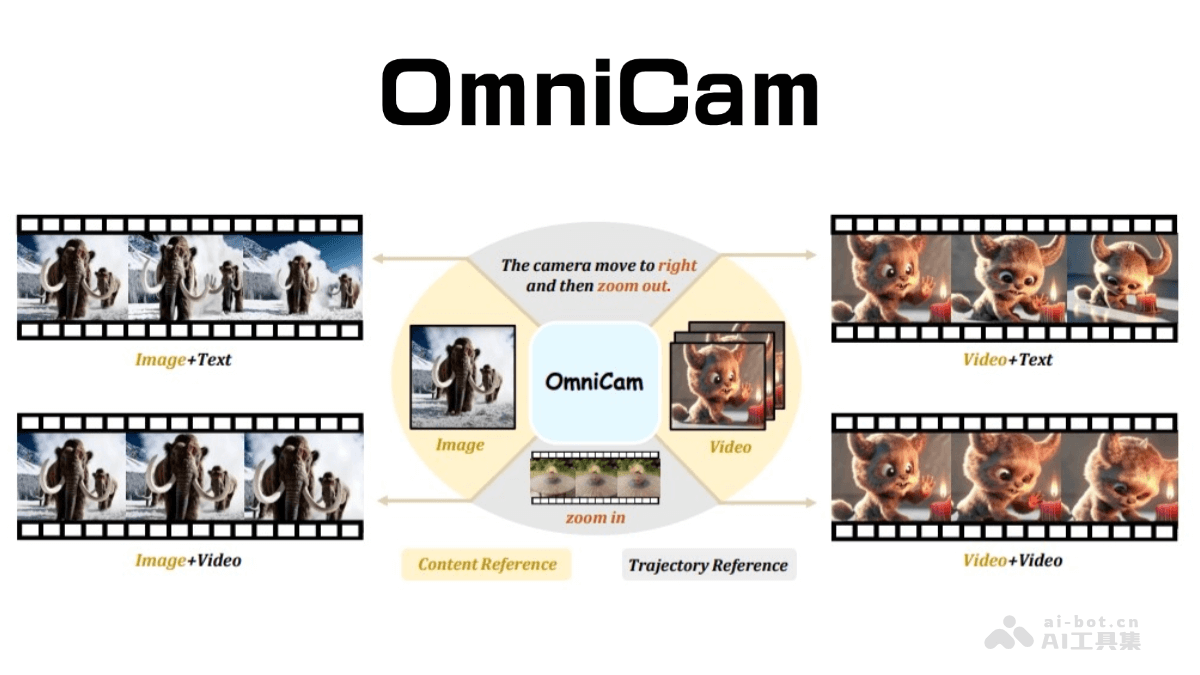
OmniCam是一款先进的多模态视频生成框架,通过智能摄像机控制,实现高质量视频的自动化生成。它支持多种输入模式组合,例如文本描述、视频轨迹或图像,从而实现对摄像机运动轨迹的精准控制。OmniCam巧妙地结合了大型语言模型(LLM)和视频扩散模型,确保生成的视频在时空上保持高度一致性。其独特的训练策略包含三个阶段:大规模模型训练、视频扩散模型训练以及强化学习微调,从而保证了生成视频的准确性和流畅性。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜
核心功能:
多模态输入: 支持文本、视频轨迹和图像等多种输入模式,实现灵活的摄像机控制。高质量视频输出: 基于LLM和视频扩散模型,生成时空一致的高质量视频内容。精细化摄像机控制: 提供帧级控制、任意方向复合运动、缩放、旋转、速度控制以及多种操作的无缝衔接,支持长序列操作和常见特效,例如相机旋转。强大数据集支持: 基于首个针对多模态相机控制的大型数据集OmniTr进行训练,确保模型的鲁棒性。
技术原理详解:
OmniCam 的视频生成过程包含四个关键步骤:
 海螺视频
海螺视频
海螺AI推出的AI视频生成工具,可以生成高质量的视频内容。
 99 查看详情
99 查看详情  轨迹规划: 系统将用户的文本或视频输入转化为离散的运动表示,并通过精准的算法规划每一帧相机的具体位置和姿态。该算法将相机运动建模为围绕物体中心的球面运动,计算轨迹上每一点的空间位置,最终转换为相机外参序列。内容渲染: 结合用户提供的内容参考(图像或视频)和规划好的相机轨迹,OmniCam 利用先进的3D重建技术渲染初始视角的视频帧。此过程利用点云、相机内参和外参信息,并通过特定算法优化相机内参,最终完成视频帧渲染。细节增强: OmniCam 的视频扩散模型会基于自身知识库,对渲染后的视频帧进行细节补充,填补空白区域,最终生成完整、精细的视频。多阶段模型训练: OmniCam 采用三阶段训练策略:基于Llama3.1微调的大规模模型训练、视频扩散模型训练以及利用PPO算法对轨迹大模型进行强化学习微调,从而优化模型性能。
轨迹规划: 系统将用户的文本或视频输入转化为离散的运动表示,并通过精准的算法规划每一帧相机的具体位置和姿态。该算法将相机运动建模为围绕物体中心的球面运动,计算轨迹上每一点的空间位置,最终转换为相机外参序列。内容渲染: 结合用户提供的内容参考(图像或视频)和规划好的相机轨迹,OmniCam 利用先进的3D重建技术渲染初始视角的视频帧。此过程利用点云、相机内参和外参信息,并通过特定算法优化相机内参,最终完成视频帧渲染。细节增强: OmniCam 的视频扩散模型会基于自身知识库,对渲染后的视频帧进行细节补充,填补空白区域,最终生成完整、精细的视频。多阶段模型训练: OmniCam 采用三阶段训练策略:基于Llama3.1微调的大规模模型训练、视频扩散模型训练以及利用PPO算法对轨迹大模型进行强化学习微调,从而优化模型性能。
项目信息:
arXiv 技术论文: https://www.php.cn/link/3f3689f1568b9f2a2fa8ed2e81f6b2fd
应用前景:
OmniCam在多个领域拥有广阔的应用前景:
影视制作: 显著提升影视制作效率,帮助导演和制片人快速生成复杂的镜头运动,实现更多创意想法。广告宣传: 帮助广告商快速制作更具吸引力的广告视频,提升广告效果。教育培训: 生成生动形象的教学视频,提高学习效率。智能安防: 实现多部门视频资源整合与联动,提升安防效率。
以上就是OmniCam— 浙大联合上海交大等高校推出的多模态视频生成框架的详细内容,更多请关注创想鸟其它相关文章!
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 chuangxiangniao@163.com 举报,一经查实,本站将立刻删除。
发布者:程序猿,转转请注明出处:https://www.chuangxiangniao.com/p/271835.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫