
阿里巴巴推出的omnitalker,是一款基于实时文本驱动的说话头像生成技术。它能够流畅处理文本、图像、音频和视频等多种模态信息,并以流式方式生成自然逼真的语音回应。其核心架构为thinker-talker架构,thinker模块负责多模态输入的处理和语义理解,生成文本内容和高维语义表达;talker模块则将这些信息转化为流畅的语音输出。 omnitalker采用tmrope技术,确保音视频输入的精准同步。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜
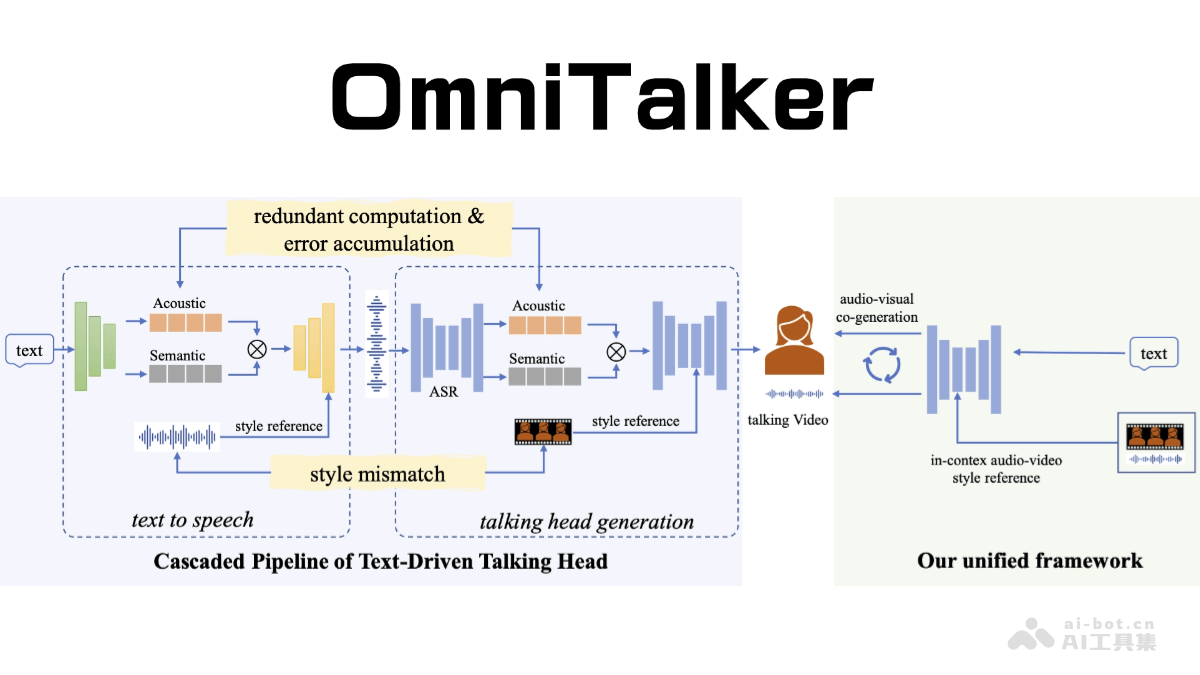
OmniTalker核心功能:
多模态信息融合: 无缝整合文本、图像、音频和视频信息。流式语音生成: 实时生成自然流畅的语音和文本,采用分块处理方法,高效处理长序列数据。精准音视频同步: TMRoPE技术确保音频和视频的完美同步。实时交互能力: 支持分块输入和即时输出,实现真正意义上的实时交互。高品质语音输出: 语音生成质量优异,超越众多同类技术。卓越性能: 在多模态基准测试中表现突出,音频能力优于同等规模的Qwen2-Audio,与Qwen2.5-VL-7B性能相当。
技术原理详解:
OmniTalker基于创新的Thinker-Talker架构,Thinker模块利用Transformer解码器架构,并配备音频和图像编码器,负责多模态信息的提取和理解;Talker模块则采用双轨自回归Transformer解码器,直接利用Thinker模块生成的语义表征和文本,以流式方式生成语音token,从而保证语音输出的自然流畅。
为了解决音视频同步问题,OmniTalker引入了TMRoPE(时间对齐多模态旋转位置嵌入)技术,通过时间顺序交错排列音频和视频帧,并进行位置编码,实现不同模态信息在时间轴上的无缝衔接。
 阿里翻译
阿里翻译
阿里巴巴提供的多语种在线实时翻译网站,支持文档、图片、视频、语音等多模态翻译
 170 查看详情
170 查看详情 
此外,OmniTalker采用流式处理方式,包括分块预填充(音频编码器采用2秒块式注意力机制,视觉编码器采用flash attention并增加MLP层)和滑动窗口DiT模型(用于流式生成mel频谱图),从而提高效率并降低延迟。Thinker和Talker模块采用端到端联合训练,共享历史上下文信息,确保模型整体性能和一致性。高效的语音编解码器(qwen-tts-tokenizer)进一步提升了语音生成的自然度和鲁棒性。
项目信息:
项目官网: https://www.php.cn/link/a5e9eeab9a92ab47c09a40ee4e5b299earXiv论文: https://www.php.cn/link/9a60f48f5298395dc0d6e0cf062d8cd7
应用前景:
OmniTalker的应用场景广泛,包括:智能语音助手、多模态内容创作、教育培训、智能客服以及工业质检等领域。其强大的多模态处理能力和高质量语音生成能力,将为各行各业带来全新的交互体验和效率提升。
以上就是OmniTalker— 阿里推出的实时文本驱动说话头像生成框架的详细内容,更多请关注创想鸟其它相关文章!
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 chuangxiangniao@163.com 举报,一经查实,本站将立刻删除。
发布者:程序猿,转转请注明出处:https://www.chuangxiangniao.com/p/272537.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 

























