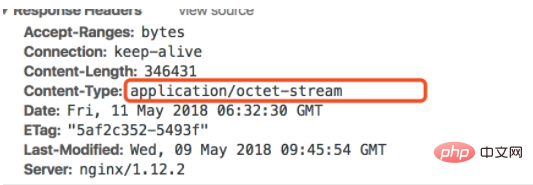
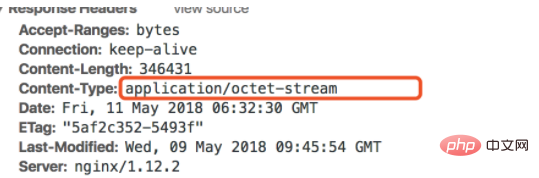
Swoole通过sendfile方法实现高效文件下载,自动处理断点续传所需的Range解析、206状态码及Content-Range头设置,利用底层sendfile系统调用避免内存拷贝,提升性能。相比传统PHP的readfile或fread循环,Swoole减少数据在用户态与内核态间的多次拷贝,支持异步非阻塞I/O,显著降低CPU与内存开销,尤其适合大文件和高并发场景。开发者需确保文件路径安全、校验权限、设置Content-Disposition触发下载,并结合限流、日志、监控等措施保障服务安全可靠。对于动态或加密文件,可采用协程分块write发送,但需自行管理I/O控制。

Swoole实现文件下载,核心在于利用其
SwooleHttpResponse
对象提供的
sendfile
方法。这个方法非常强大,它不仅能高效地发送整个文件,还能通过参数直接支持断点续传。处理断点续传的关键,则在于客户端发送的
Range
HTTP头,以及服务器端根据这个头返回
206 Partial Content
状态码、
Content-Range
和
Accept-Ranges
头。Swoole的
sendfile
方法在大多数情况下能自动帮你处理这些细节,省去了手动解析和文件指针操作的麻烦。
要用Swoole搞定文件下载,特别是带断点续传的那种,其实比你想象的要简单不少。Swoole的
sendfile
方法简直是为这事儿量身定制的。
首先,你需要一个HTTP服务器:
on("Request", function (Request $request, Response $response) { // 假设我们要下载的文件在这里 $filePath = '/path/to/your/download/file.zip'; // 替换成你实际的文件路径,务必确保路径安全! // 检查文件是否存在 if (!file_exists($filePath)) { $response->status(404); $response->end("File not found."); return; } // 设置文件名,让浏览器知道下载的文件名 $filename = basename($filePath); $response->header('Content-Disposition', 'attachment; filename="' . $filename . '"'); $response->header('Content-Type', 'application/octet-stream'); // 或者更具体的文件类型,比如 'application/zip' // 最关键的一步:使用sendfile方法 // Swoole的sendfile方法会自动解析客户端的Range头,并进行断点续传处理。 // 你不需要手动去解析Range头、设置Content-Range、Content-Length或206状态码, // Swoole内部都帮你搞定了。 $response->sendfile($filePath); // 如果你确实需要更精细的控制,比如只发送文件的一部分, // 可以在sendfile中指定offset和length。 // 比如:$response->sendfile($filePath, 1024, 2048); // 从1KB处开始,发送2KB数据 // 但对于断点续传,通常直接用$response->sendfile($filePath)让Swoole自动处理即可。});$http->start();
是不是觉得有点太简单了?这正是Swoole的魅力所在。当你调用
$response->sendfile($filePath)
时,Swoole在底层会智能地完成以下工作:
解析
Range
头: 如果客户端发送了
Range: bytes=start-end
这样的请求头,Swoole会捕获并解析它。设置响应头:如果客户端请求了部分内容(有
Range
头),Swoole会自动设置
HTTP/1.1 206 Partial Content
状态码。设置
Accept-Ranges: bytes
,告诉客户端服务器支持断点续传。根据请求的范围,计算并设置
Content-Length
为本次发送的数据长度。设置
Content-Range: bytes start-end/totalLength
,明确告知客户端当前发送的数据范围和文件总大小。底层文件传输: Swoole会利用操作系统底层的
sendfile(2)
系统调用(如果可用且支持),将文件数据直接从磁盘内核缓冲区传输到网络套接字缓冲区,避免了用户态内存拷贝,效率极高。如果
sendfile(2)
不可用,它也会使用异步I/O的方式高效读取和发送。
所以,作为开发者,你只需要确保文件路径正确,并且文件可读,剩下的Swoole都给你打理好了。当然,别忘了设置
Content-Disposition
头,这样浏览器才会弹出下载框而不是直接在浏览器里打开文件。
Swoole sendfile与传统PHP文件下载有何不同?效率优势在哪里?
说实话,当我第一次接触Swoole的
sendfile
时,最大的感受就是“这玩意儿也太省心了!”。它和传统PHP文件下载方式,比如用
readfile()
或者手动
fread()
循环输出,在底层机制和效率上简直是天壤之别。
传统PHP方式,无论是
readfile()
还是你自己
fopen
然后
while (!feof($fp)) { echo fread($fp, 8192); }
,都绕不开一个事实:文件内容是先从磁盘读到PHP的内存里(用户态),然后再从PHP内存写入到网络缓冲区。这个过程中,数据要经过多次拷贝,而且PHP在读取和写入时,会阻塞当前的进程或线程,直到数据传输完成。对于小文件可能感知不明显,但一旦涉及到大文件,或者高并发场景,这种模式的性能瓶颈就暴露无遗了:内存占用高、CPU消耗大、并发能力差。
而Swoole的
sendfile
,它最核心的优势在于利用了操作系统提供的
sendfile(2)
系统调用。这个系统调用非常聪明,它允许内核直接将文件数据从文件描述符(磁盘)传输到套接字描述符(网络),整个过程数据都不需要经过用户态的内存缓冲区。这意味着什么?意味着数据少了一次甚至多次的内存拷贝,CPU可以腾出来干别的,内存占用也大大降低。我个人觉得,这就像是文件数据坐上了直达电梯,直接从硬盘送到网线里,中间省去了无数的转运环节。
即便在某些不支持
sendfile(2)
系统调用的环境(比如某些虚拟化环境或特定文件系统),Swoole也会退化到使用异步非阻塞I/O来读取和发送文件。虽然没有
sendfile(2)
那么极致,但依然比传统PHP的阻塞I/O模型高效得多,因为它不会阻塞Swoole的事件循环,可以同时处理其他请求,保持高并发能力。这种设计哲学,让Swoole在文件下载这种I/O密集型任务上,表现出压倒性的效率优势。
处理大文件下载时,Swoole有哪些最佳实践和潜在挑战?
处理大文件下载,Swoole确实提供了非常好的基础,但要真正做到健壮和高效,还是有一些最佳实践和潜在挑战需要我们去思考的。
最佳实践方面:
 造点AI
造点AI
夸克 · 造点AI
 325 查看详情
325 查看详情  充分利用
充分利用
sendfile
: 这是毋庸置疑的。对于静态大文件,直接用
$response->sendfile($filePath)
,让Swoole自动处理断点续传和底层优化。这能最大限度地发挥性能。文件路径安全: 这是老生常谈但极其重要的一点。永远不要直接使用用户传入的路径作为文件路径,必须进行严格的校验和净化。比如,将所有可下载文件放在一个固定的安全目录,然后只允许用户提供文件名,再通过
realpath()
或
basename()
结合预设目录来构建最终路径。我曾见过因为路径不当导致服务器文件被非法访问的案例,教训深刻。资源限制考量: 尽管Swoole高效,但服务器的带宽、文件描述符(
ulimit -n
)、以及硬盘I/O能力都是有限的。如果并发下载量过大,可能会打满带宽或耗尽文件描述符。适当的限流策略(比如限制单个IP的下载速度或并发连接数)在大文件下载场景下显得尤为重要,可以防止恶意下载或某个用户占用过多资源。错误处理与日志: 文件不存在、权限不足、磁盘空间不足等情况都可能导致下载失败。完善的错误处理(如
file_exists
检查、
is_readable
检查)和详细的日志记录,能帮助你快速定位问题,提升系统可靠性。
潜在挑战方面:
带宽瓶颈: 这不是Swoole的问题,而是网络基础设施的限制。再高效的服务器,如果出口带宽不够,大文件下载速度也上不去。这时可能需要考虑CDN或分布式存储。客户端兼容性: 虽然
sendfile
会自动处理HTTP头,但某些老旧或非标准的下载工具可能对
Range
头支持不佳。不过,这通常是小概率事件,主流浏览器和下载工具都没问题。动态内容或加密文件: 如果你的“大文件”不是一个简单的静态文件,而是需要动态生成、加密、解密或进行其他处理后才能发送的,那么
sendfile
就无能为力了。这时,你需要手动分块读取文件,然后通过
$response->write()
逐块发送。这种情况下,内存占用和CPU消耗会增加,需要更精细的异步I/O控制,比如使用协程来分批读取和写入。但这已经超出了纯粹
sendfile
的范畴了。文件一致性: 在高并发下,如果文件在下载过程中被修改或删除,可能会导致客户端下载到不完整或错误的文件。对于这种情况,可以考虑在下载前对文件加锁,或者使用版本控制,确保下载的文件是某个稳定版本。
如何确保Swoole文件下载的安全性与可靠性?
确保文件下载的安全性与可靠性,在我看来,是任何一个线上服务都必须认真对待的基石。尤其是在Swoole这种高性能框架下,一旦出现安全漏洞,影响面可能被放大。
安全性方面:
严格的文件路径验证: 这是重中之重!我之前提到过,用户传来的任何路径参数都不能直接用。正确的做法是,设定一个或几个安全的下载根目录,然后根据用户请求的文件名,在这个根目录下去查找。例如:
$baseDir = '/data/downloads/';$filename = basename($request->get['file'] ?? ''); // 仅获取文件名部分,去除路径$filePath = $baseDir . $filename;if (!file_exists($filePath) || !is_readable($filePath)) { // 文件不存在或不可读,直接拒绝 $response->status(404); $response->end("File not found or access denied."); return;}// ... 然后再 sendfile
basename()
函数在这里非常关键,它能有效防止路径穿越(
../
)攻击。
权限控制与认证: 不是所有文件都应该对所有人开放。对于需要登录才能下载的文件,务必在
Request
回调中进行用户身份验证和权限检查。如果用户未登录或无权访问,直接返回403 Forbidden。
限流与防DDoS: 大文件下载服务很容易被滥用,例如被用于DDoS攻击的跳板,或者被某个用户恶意下载耗尽带宽。可以结合Swoole的连接管理或者外部的Nginx层,对下载请求的IP、频率、并发连接数进行限制。
内容类型(Content-Type)校验: 虽然是下载,但设置正确的
Content-Type
有助于客户端正确处理文件。更重要的是,如果你允许用户上传文件,并在之后提供下载,那么在上传时就必须严格校验文件类型,防止上传恶意脚本文件。
可靠性方面:
完善的错误处理机制: 除了文件不存在,还可能遇到磁盘满、文件被占用、网络中断等问题。在
sendfile
调用前后,以及Swoole的
onClose
事件中,都应该考虑这些异常情况。例如,如果文件在传输过程中连接断开,Swoole会自动停止传输,但你可能需要记录这个中断。
Accept-Ranges
和
Content-Range
的正确设置: Swoole的
sendfile
已经帮你处理了,但如果你需要手动实现(例如,动态生成文件内容),务必确保这些HTTP头正确无误,否则客户端的断点续传功能会失效,导致下载失败或重复下载。监控与告警: 部署专业的监控系统,实时关注服务器的CPU、内存、磁盘I/O、网络带宽使用情况,以及Swoole进程的状态。一旦资源使用异常或服务出现故障,能够及时收到告警并介入处理。我个人觉得,没有监控的线上服务,就像在黑夜里开车,你不知道什么时候会撞墙。文件完整性校验: 对于重要的下载文件,可以额外提供MD5、SHA256等校验和。用户下载完成后,可以自行校验文件是否完整、未被篡改。这虽然是客户端行为,但服务器提供这个信息,能极大提升可靠性感知。
总之,Swoole在文件下载方面提供了强大的底层能力,但上层的安全与可靠性,依然需要我们开发者精心设计和实现。
以上就是Swoole如何实现文件下载?断点续传怎么处理?的详细内容,更多请关注创想鸟其它相关文章!
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 chuangxiangniao@163.com 举报,一经查实,本站将立刻删除。
发布者:程序猿,转转请注明出处:https://www.chuangxiangniao.com/p/273325.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫