
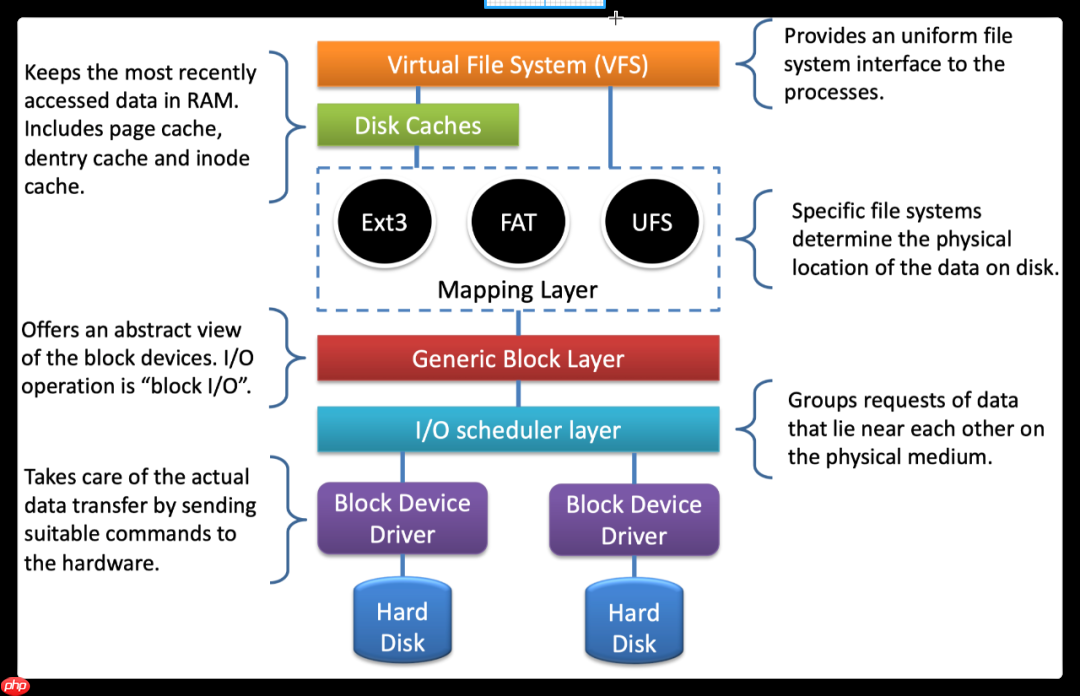
在宏观层面上,文件系统在内核中的运作流程可以概括为从虚拟文件系统(vfs)到实际磁盘文件系统的一系列步骤:vfs -> 磁盘缓存 -> 实际磁盘文件系统 -> 通用块设备层 -> io调度层 -> 块设备驱动层 -> 磁盘。具体的操作流程如图所示:
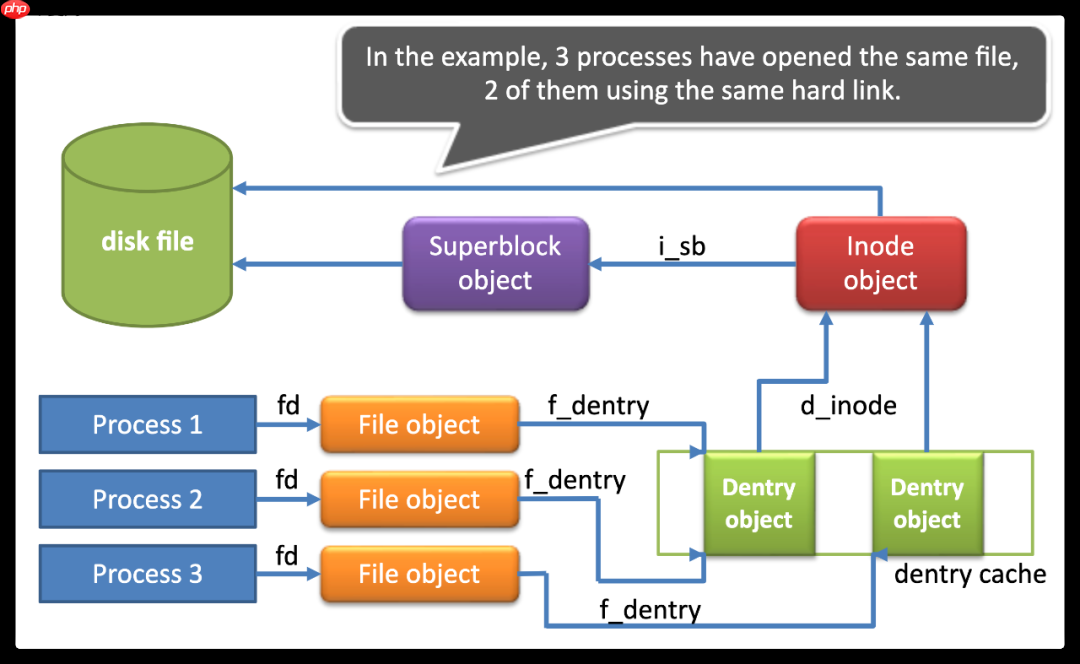
理解文件系统中的数据结构是理解Linux文件系统运作的关键。Linux中的文件系统包含几种核心数据结构:super_block、inode、dentry和file。
super_block:这是磁盘文件系统(如XFS、EXT4)的内存表示。它包含了文件系统的基本信息和操作函数表,确保不同文件系统能够通过通用接口与VFS交互。
inode:在Linux中,每个文件都有一个唯一的inode,它存储了文件的元数据,如文件大小、权限、时间戳等。inode还包含了指向文件内容的指针。
dentry:dentry代表文件系统中的目录项,存储了文件名和指向其inode的指针。dentry帮助构建文件系统的目录结构。
file:当文件被打开时,会为该文件创建一个file结构体实例,记录文件的当前状态,如打开标志和文件位置等。每个进程对文件的系统调用都会产生一个file实例。
这些数据结构通过函数表和私有数据实现了工厂设计模式,使得不同文件系统能够注册自己的实现方法,确保VFS能够与各种实际磁盘文件系统交互。
以下是各核心数据结构的简要代码描述:
// struct super_block 省略了一些字段,描述了核心字段struct super_block { // 将super_block链接到s_list链表 struct list_head s_list; // s_blocksize的位数 unsigned char s_blocksize_bits; // 文件系统中块大小 unsigned long s_blocksize; // 支持最大文件大小 loff_t s_maxbytes; // 文件系统类型 struct file_system_type *s_type; // super_block的操作函数 const struct super_operations *s_op; // dentry函数操作定义 const struct dentry_operations *s_d_op; // dentry的指针,指向根节点的root struct dentry *s_root; // 挂载该文件系统的挂载点组成的链表 struct list_head s_mounts; // 同一种文件系统组成的链表 struct hlist_node s_instances; // 实际文件系统的私有数据 void *s_fs_info;} __randomize_layout;
// 每个文件系统在初始化时都会先注册这个文件系统,file_system_type就是用来描述这个文件系统的struct file_system_type { // 文件系统名称,比如ext4、xfs const char *name; // 实际文件提供的mount函数用来初始化super_block struct dentry *(*mount) (struct file_system_type *, int, const char *, void *); // 释放文件系统的函数 void (*kill_sb) (struct super_block *); // 内核模块描述 struct module *owner; // file_system_type链表 struct file_system_type *next; // 同一种文件系统super_block组成的链表 struct hlist_head fs_supers;};// 比如ext4的file_system_type的类型static struct file_system_type ext4_fs_type = { .owner = THIS_MODULE, .name = "ext4", .mount = ext4_mount, .kill_sb = kill_block_super, .fs_flags = FS_REQUIRES_DEV,};
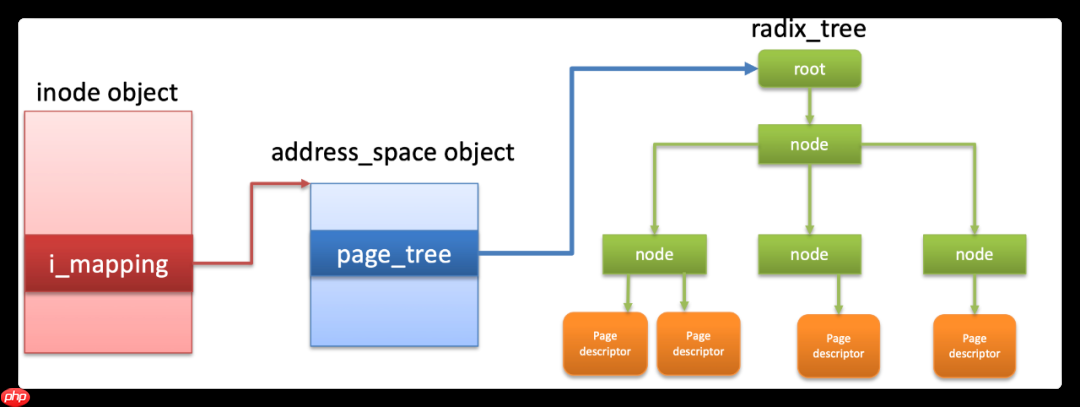
// 文件系统中inode描述,其中说明了核心字段的函数struct inode { // 文件类型 umode_t i_mode; // uid/gid是描述文件的属主 kuid_t i_uid; kgid_t i_gid; // inode的操作函数,这个是由具体文件系统决定 const struct inode_operations *i_op; // inode属于的超级块 struct super_block *i_sb; // page cache涉及到缓存管理 struct address_space *i_mapping; // inode的编号,单个文件系统内这个是唯一的 unsigned long i_ino; // inode所指向的文件大小 loff_t i_size; // 文件的acess/mofidy/change时间 struct timespec64 i_atime; struct timespec64 i_mtime; struct timespec64 i_ctime; // inode链接到哈希链表中 struct hlist_node i_hash; // inode链接到super_block上 struct list_head i_sb_list; union { // 进程打开文件时候的操作函数,这个是与文件类的系统调用对接 const struct file_operations *i_fop; void (*free_inode)(struct inode *); }; // inode的私有数据,一般存储实际文件系统的私有数据 void *i_private; /* fs or device private pointer */} __randomize_layout;
inode中的i_mapping用于缓存,其具体的关系如下:
// 文件系统的目录树是采用组织dentry来呈现struct dentry { // 指向父目录的dentry struct dentry *d_parent; // 保存了文件名字和哈希值 struct qstr d_name; // 该目录项指向的inode struct inode *d_inode; // 当目录项名称比较短的时候保存在这里 unsigned char d_iname[DNAME_INLINE_LEN]; /* small names */ // 定义dentry的操作函数,每个文件系统都针对d_op进行初始化 const struct dentry_operations *d_op; // dentry私有数据 void *d_fsdata; /* fs-specific data */ union { struct list_head d_lru; /* LRU list */ wait_queue_head_t *d_wait; /* in-lookup ones only */ }; // 当前dentry所有父目录项的链表 struct list_head d_child; /* child of parent list */ // 当前目录项下所有子目录项的链表 struct list_head d_subdirs; /* our children */} __randomize_layout;
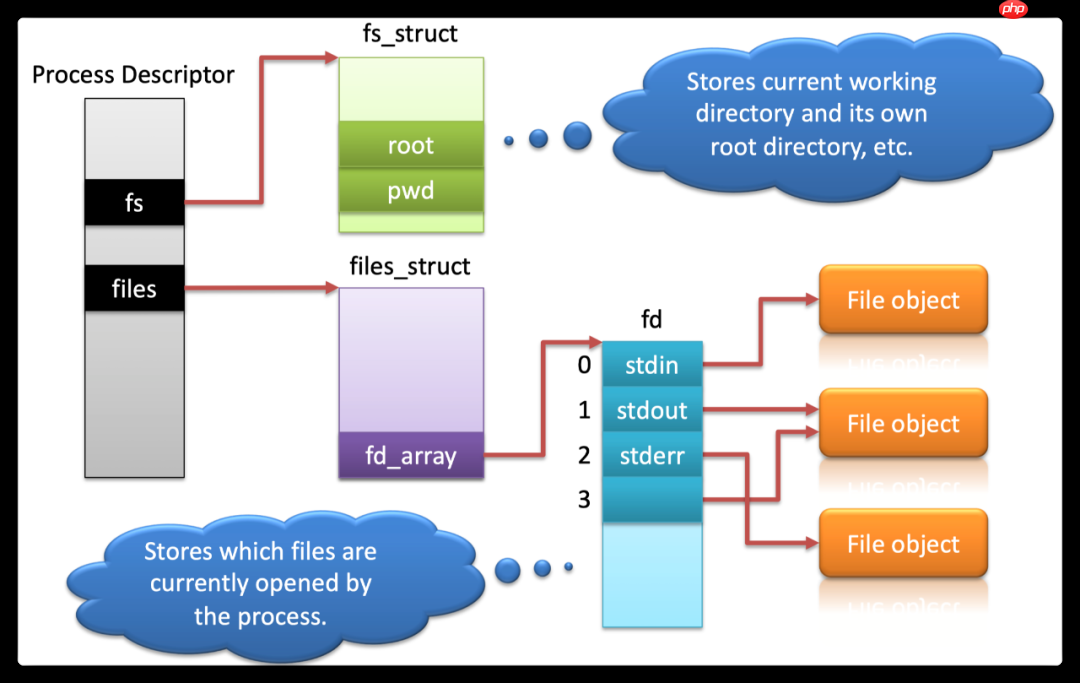
// 每当进程打开一个文件都会实例化一个struct file,这里面包含了标准的posix语义的操作struct file { // 文件路径 struct path f_path; // 文件指向的inode struct inode *f_inode; // 定义struct file的操作函数 const struct file_operations *f_op; // 文件的引用计数器 atomic_long_t f_count; // 文件打开的flags unsigned int f_flags; // 文件的mode fmode_t f_mode; // 文件的当前位置 loff_t f_pos; // struct file的私有数据 void *private_data; // 文件的page cache相关的address_space struct address_space *f_mapping;} __randomize_layout;
进程打开一个文件的呈现如下面所示:
以上就是浅谈文件系统中的核心数据结构的详细内容,更多请关注创想鸟其它相关文章!
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 chuangxiangniao@163.com 举报,一经查实,本站将立刻删除。
发布者:程序猿,转转请注明出处:https://www.chuangxiangniao.com/p/27990.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 




























