
ola:一款性能卓越的全模态语言模型,超越现有同类模型!
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

AIxiv专栏持续报道全球顶尖AI研究成果,如果您有优秀工作,欢迎投稿或联系报道 (liyazhou@jiqizhixin.com; zhaoyunfeng@jiqizhixin.com)。
Ola模型,由腾讯混元Research、清华大学智能视觉实验室和南洋理工大学S-Lab联合研发,在图像、视频和音频理解方面展现出强大的竞争力。论文共同一作:清华大学刘祖炎博士、南洋理工大学董宇昊博士;通讯作者:腾讯饶永铭高级研究员、清华大学鲁继文教授。
GPT-4o的出现激发了全模态模型的研究热潮。虽然已有开源替代方案,但性能仍逊色于专用单模态模型。Ola模型的核心创新在于其渐进式模态对齐策略,它逐步扩展模型支持的模态,先从图像和文本入手,再逐步加入语音和视频数据,有效降低了训练成本并提升了模型性能。

项目地址:https://www.php.cn/link/42b1c6a5d2205c2a61dcc08c028e4592论文:https://www.php.cn/link/a18177565d506ce27ba1197cb765ee0b代码:https://www.php.cn/link/9754f4e85b915d1ecb9de2911d9d80cb模型:https://www.php.cn/link/b4a3c653ae58ddb2b96bd00536fb0620
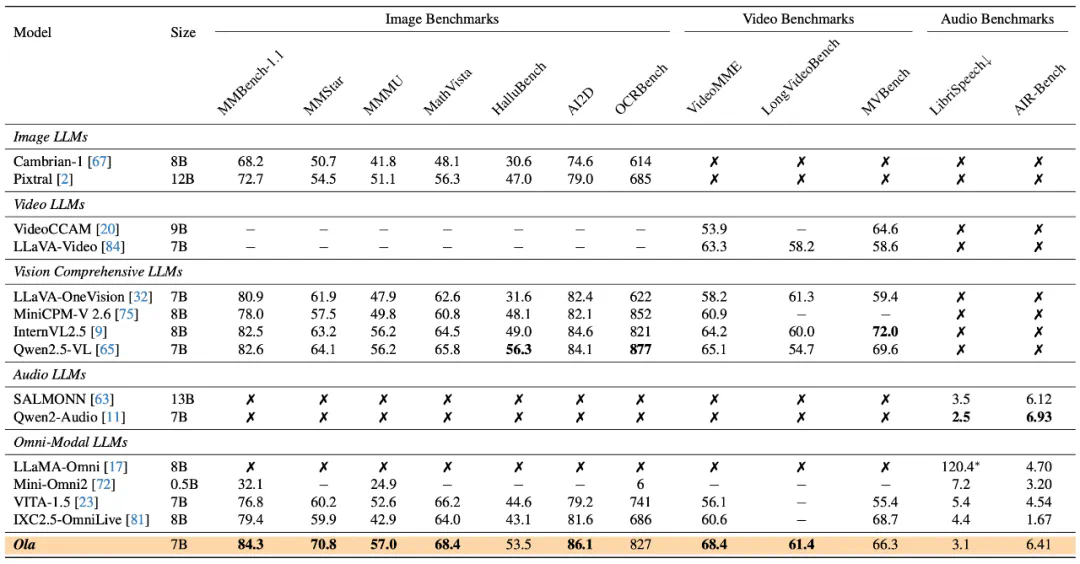
Ola模型在多个基准测试中显著超越了Qwen2.5-VL、InternVL2.5等主流模型。作为一款仅含70亿参数的全模态模型,它在图像、视频和音频理解方面均取得了突破性进展:
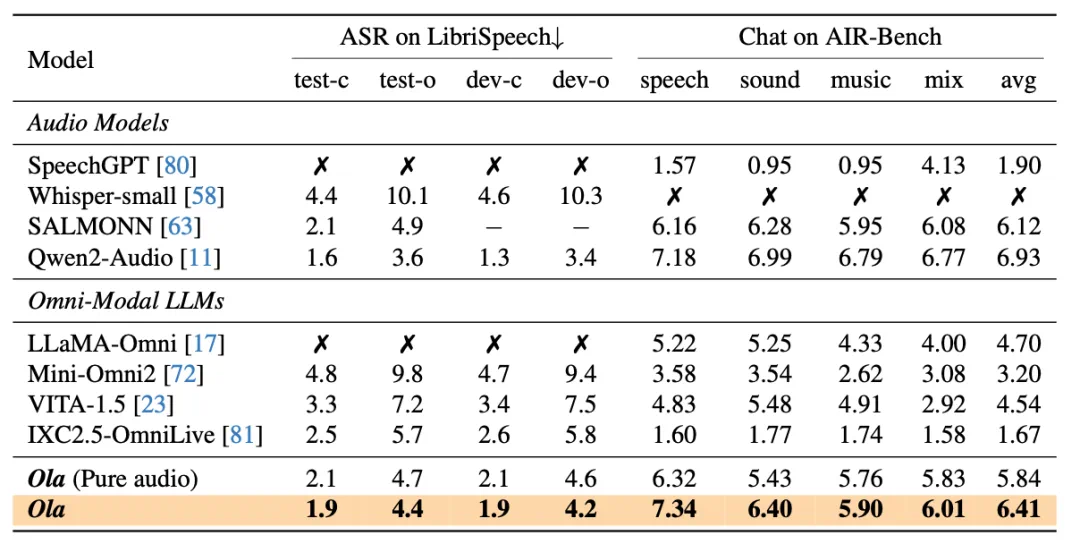
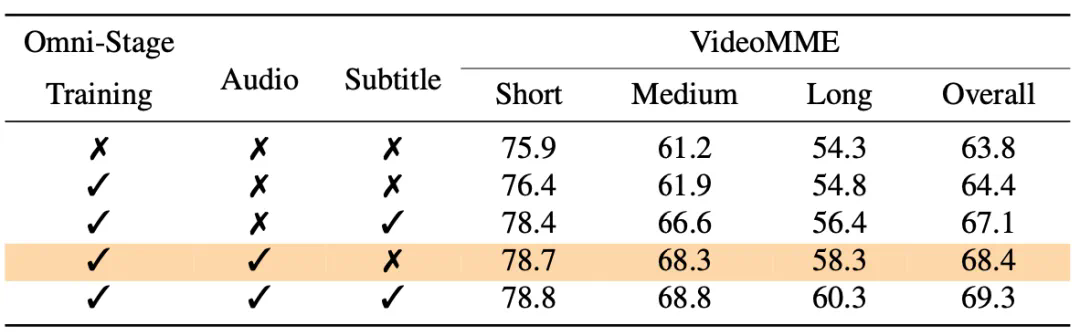
图像理解: 在OpenCompass基准测试中,其在8个数据集上的平均准确率达到72.6%,在所有参数量小于300亿的模型中排名第一,超越GPT-4o、InternVL2.5等。视频理解: 在VideoMME测试中,Ola在输入视频和音频的情况下,准确率达到68.4%,超越LLaVA-Video、VideoLLaMA3等。音频理解: 在语音识别和对话评估等任务中,Ola的表现也接近最先进的音频理解模型。
Ola模型、代码和训练数据均已开源,旨在推动全模态理解领域的研究发展。
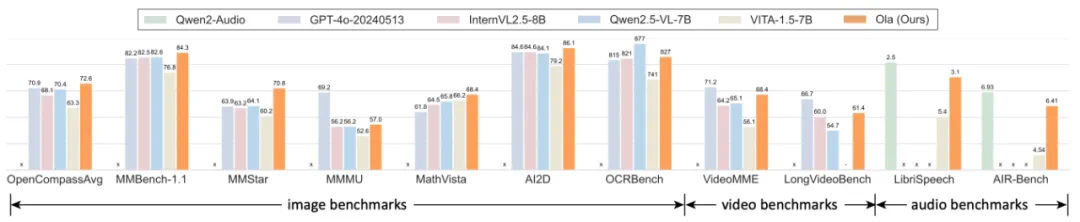
图1:Ola全模态模型超越Qwen2.5-VL、InternVL2.5等主流多模态模型。
 腾讯混元文生视频
腾讯混元文生视频
腾讯发布的AI视频生成大模型技术
 137 查看详情
137 查看详情 
Ola模型的成功,得益于其独特的渐进式模态对齐策略、高效的架构设计以及高质量的训练数据。 该策略将复杂的训练过程分解为更易管理的步骤,并有效利用了视频数据作为连接视觉和音频模态的桥梁。
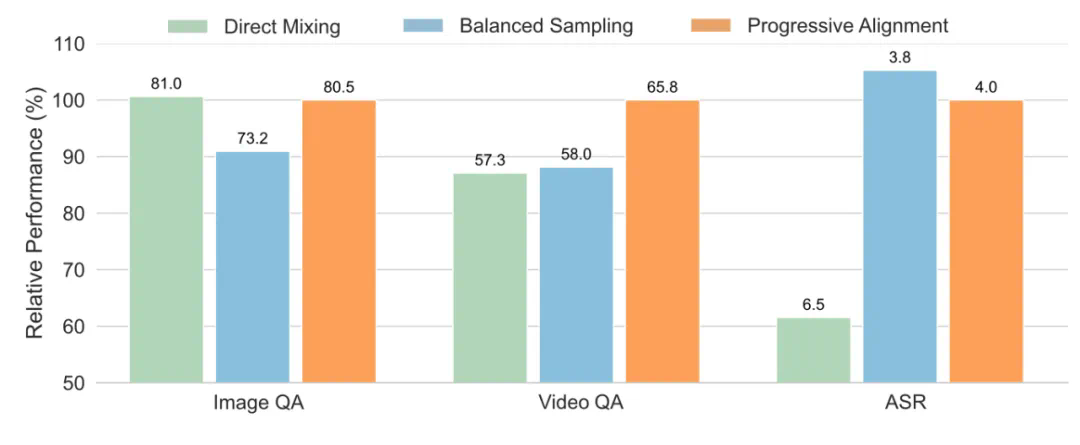
图2:渐进式模态学习能够训练更好的全模态模型
Ola模型的架构支持全模态输入和流式文本及语音生成,其视觉和音频联合对齐模块通过局部-全局注意力池化层有效融合了多模态信息。
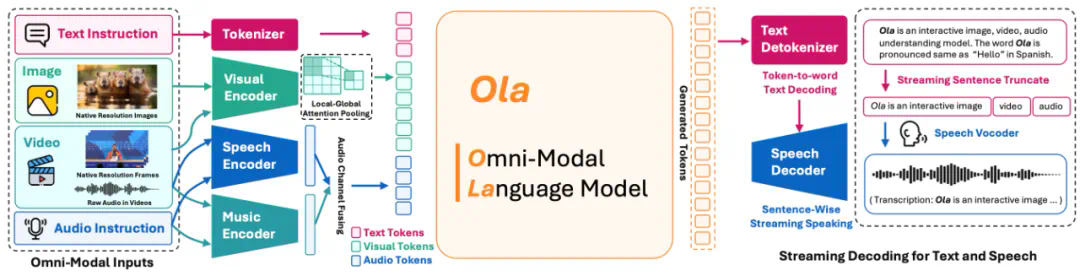
图3:Ola模型结构图
Ola的训练数据涵盖了图像、视频和音频等多种模态,并包含专门设计的跨模态视频数据,以增强模型对音频和视频之间关系的理解。 实验结果充分证明了Ola模型的优越性能和渐进式模态对齐策略的有效性。 Ola的出现为全模态大模型的研究和应用带来了新的突破。

以上就是最强全模态模型Ola-7B横扫图像、视频、音频主流榜单,腾讯混元Research&清华&NTU联手打造的详细内容,更多请关注创想鸟其它相关文章!
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 chuangxiangniao@163.com 举报,一经查实,本站将立刻删除。
发布者:程序猿,转转请注明出处:https://www.chuangxiangniao.com/p/282166.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 

























