
在mysql中,可以利用“mysql-proxy”实现读写分离;“mysql-proxy”是一个mysql官方提供用于实现读写分离的软件,也叫中间件,可以让主数据库处理写操作,而从数据库处理查询的操作,数据库的一致性则通过主从复制来实现。

本教程操作环境:windows10系统、mysql8.0.22版本、Dell G3电脑。
mysql读写分离的实现方式是什么
Mysql中可以实现读写分离的插件有mysql-proxy / Mycat / Amoeba ,mysql-proxy是系统自带的一个插件,此次实验主要用它来实现读写分离
mysql-proxy是实现”读写分离(Read/Write Splitting)”的一个软件(MySQL官方提供 ,也叫中间件),基本的原理是让主数据库处理写操作(insert、update、delete),而从数据库处理查询操作(select)。而数据库的一致性则通过主从复制来实现
MySQL-proxy 它能实现读写语句的区分主要依靠内部的一个lua脚本(能实现读写语句的判断)
如果只在主服务器(写服务器)上完成数据的写操作,此时从服务器上没有执行写操作,是没有数据的
这个时候需要使用另外一个技术来实现主从服务器的数据一致性,这个技术叫做 主从复制技术, 所以说主从复制是读写分离的基础
读写分离(MySQL- Proxy)是指让master处理写操作,让slave处理读操作,非常适用于读操作量比较大的场景,可减轻master的压力
使用mysql-proxy实现mysql的读写分离,mysql-proxy实际上是作为后端mysql主从服务器的代理,它直接接受客户端的请求,对SQL语句进行分析,判断出是读操作还是写操作,然后分发至对应的mysql服务器上
因为数据库的写操作相对读操作是比较耗时的,所以数据库的读写分离,解决的是数据库的写入,影响了查询的效率
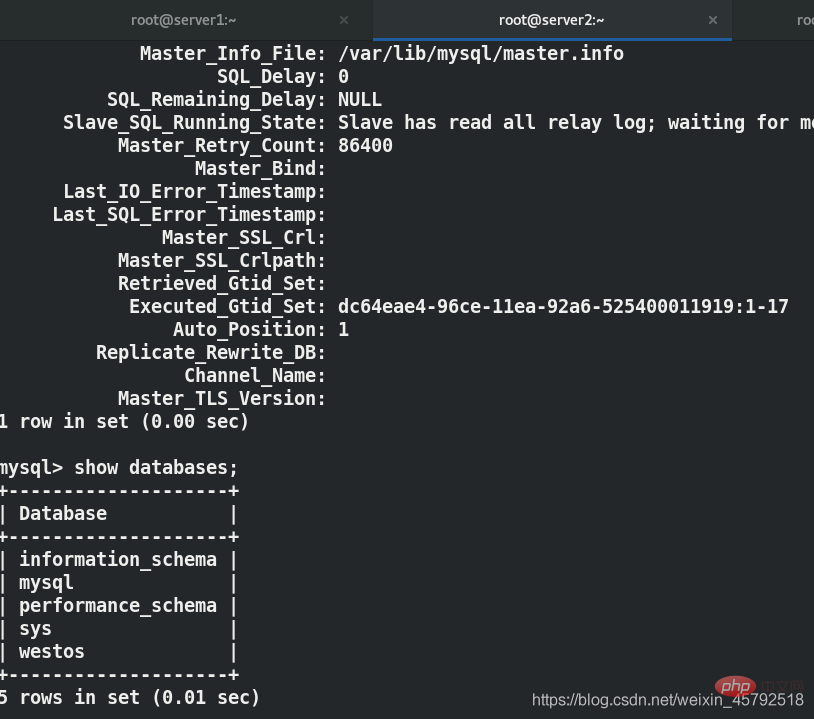
在server1和server2先配置gtid主从复制
gtid主从复制上篇博客已经说明,这里不再赘述,只展示最终效果
可以看到server1上建立一个westos数据库,对应的server2上会同步过来
配置server3代理端(mysql-proxy)
在server3上搭建mysql-proxy代理服务器(实现客户端写在server1上、读server2上的数据)
(1) 从物理机获取mysql-proxy安装包到server3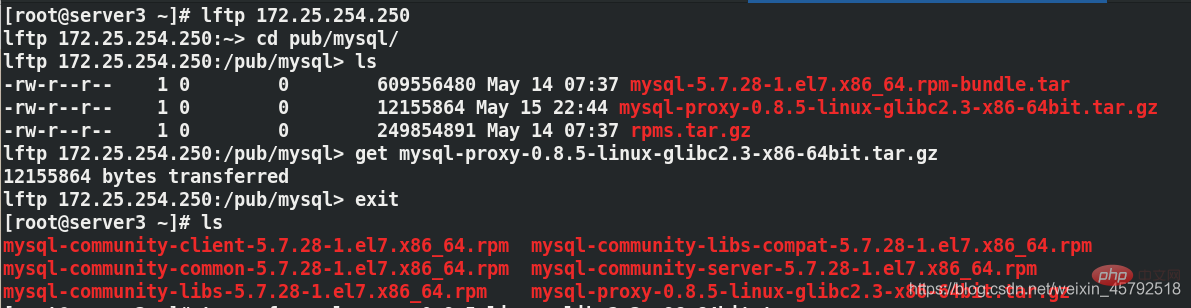
(2)在server3上进行配置
 火龙果写作
火龙果写作
用火龙果,轻松写作,通过校对、改写、扩展等功能实现高质量内容生产。
 106 查看详情
106 查看详情 
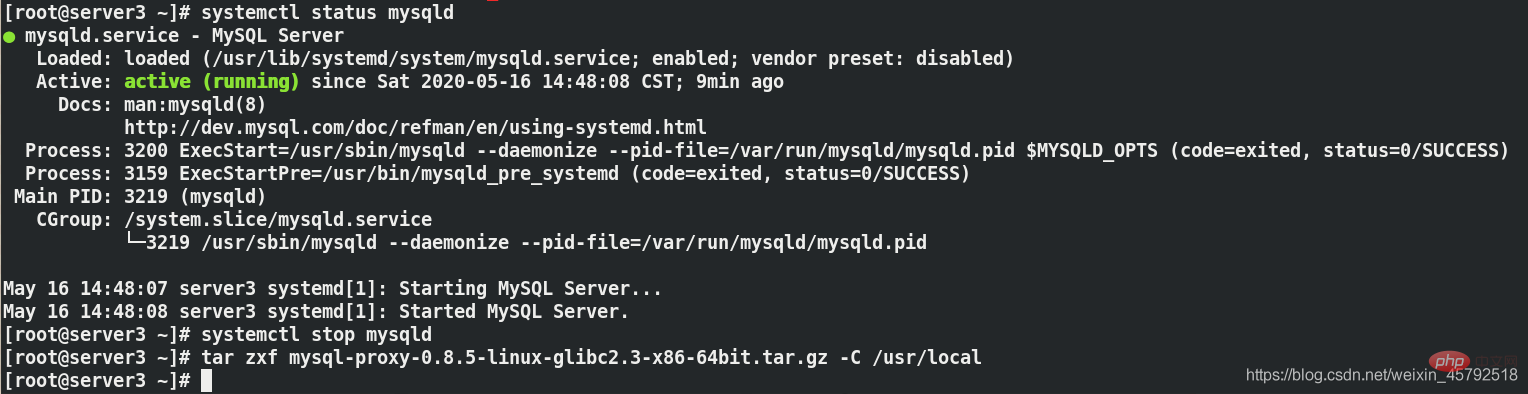
[root@server3 ~]# systemctl status mysqld##查看mysqld服务状态[root@server3 ~]# systemctl stop mysqld##关闭mysqld服务,因为代理服务器要用3306端口[root@server3 ~]# tar zxf mysql-proxy-0.8.5-linux-glibc2-x86-64bit.tar.gz -C /usr/local/##解压到/usr/local/目录下
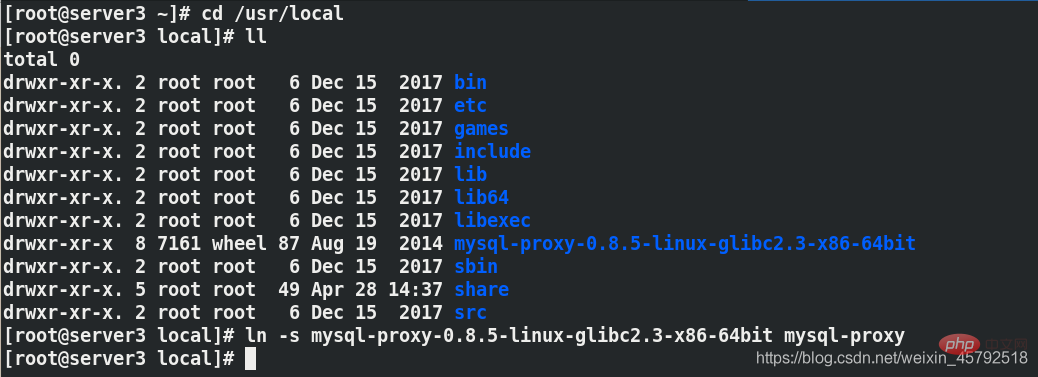
做一个软连接以便管理
ln -s mysql-proxy-0.8.5-linux-glibc2-x86-64bit mysql-proxy
mysql-proxy目录下是没有配置文件的,所以需要自行建立一个配置文件的目录,创建配置文件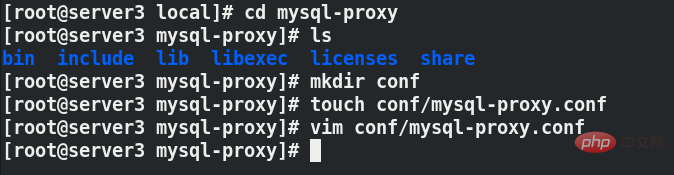
使用下面两条命令可以查配置文件中写入的参数
[root@server3 bin]# ./mysql-proxy --help[root@server3 bin]# ./mysql-proxy --help-proxy
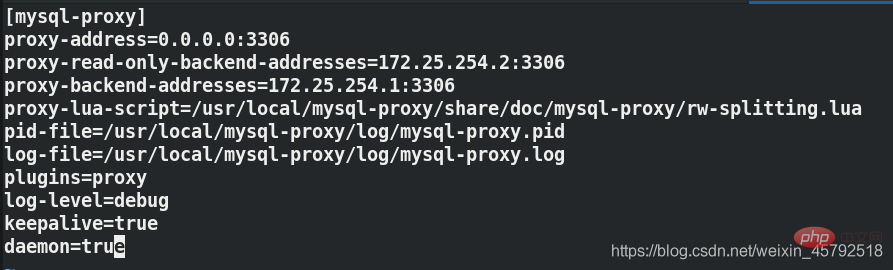
[mysql-proxy]##指定语句块proxy-address=0.0.0.0:3306##指定proxy访问的主机和端口,3306是一个对外的通用端口proxy-read-only-backend-addresses=172.25.254.2:3306##读主机的ip和端口proxy-backend-addresses=172.25.254.1:3306##执行写主机的ip和端口proxy-lua-script=/usr/local/mysql-proxy/share/doc/mysql-proxy/rw-splitting.lua##指定读写分离操作使用的lua文件路径pid-file=/usr/local/mysql-proxy/log/mysql-proxy.pid##pid存放路径log-file=/usr/local/mysql-proxy/log/mysql-proxy.log##日志存放路径plugins=proxy##指定使用的插件log-level=debug##日志的等级keepalive=true##开启守护进程daemon=true##使用后台方式运行
保存后需要将配置文件的权限改为660,需要创建 log 目录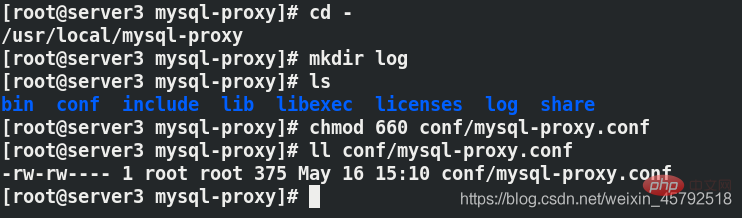
修改数据库发生读写分离时的最大和最小连接数
[root@server3 mysql-proxy]# find . -name *.lua ./share/doc/mysql-proxy/rw-splitting.lua[root@server3 mysql-proxy]# cd share/doc/mysql-proxy [root@server3 mysql-proxy]# ls [root@server3 mysql-proxy]# vim rw-splitting.lua##将lua脚本里原本启动机制的最小4个最大8个连接,改为1和2min_idle_connections = 1, 最小连接数 max_idle_connections = 2, 最大连接数
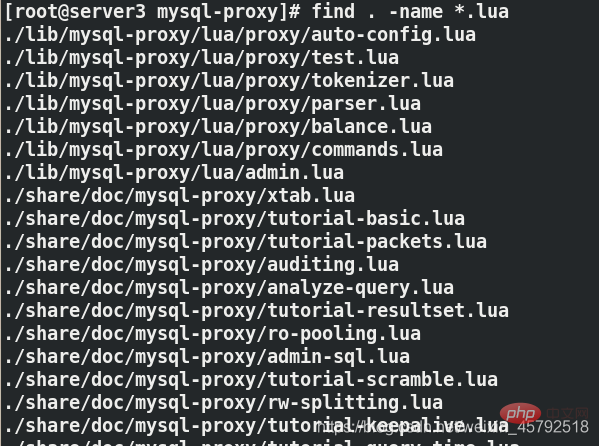

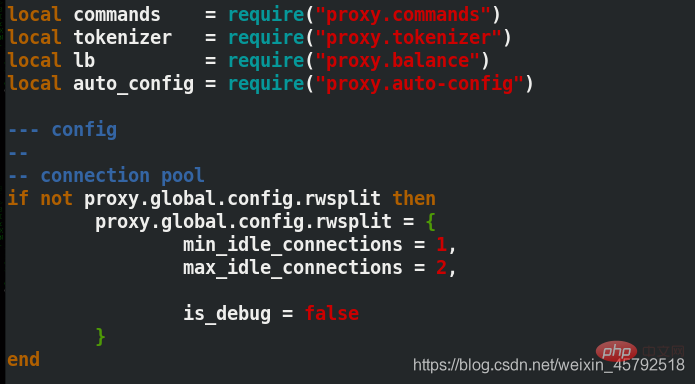
(3)启动mysql-proxy
/usr/local/mysql-proxy/bin/mysql-proxy --defaults-file=/usr/local/mysql-proxy/conf/mysql-proxy.conf##启动cat /usr/local/mysql-proxy/log/mysql-proxy.log##查看日志

测试读写分离
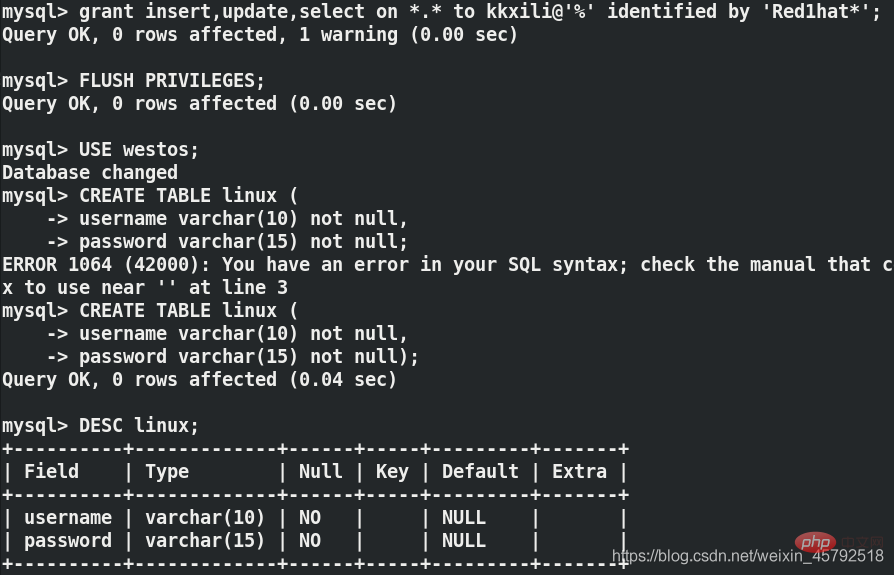
(1)在server1上创建新的用户并且授权
mysql> grant insert,update,select on *.* to kkxili@'%' identified by 'Red1hat*';mysql> FLUSH PRIVILEGES;##刷新授权表mysql> USE westos;Database changedmysql> CREATE TABLE linux ( -> username varchar(10) not null, -> password varchar(15) not null);mysql>DESC linux;
(2)server3安装lsof

(3)在用户端虚拟机server4上第一次连接数据库代理server3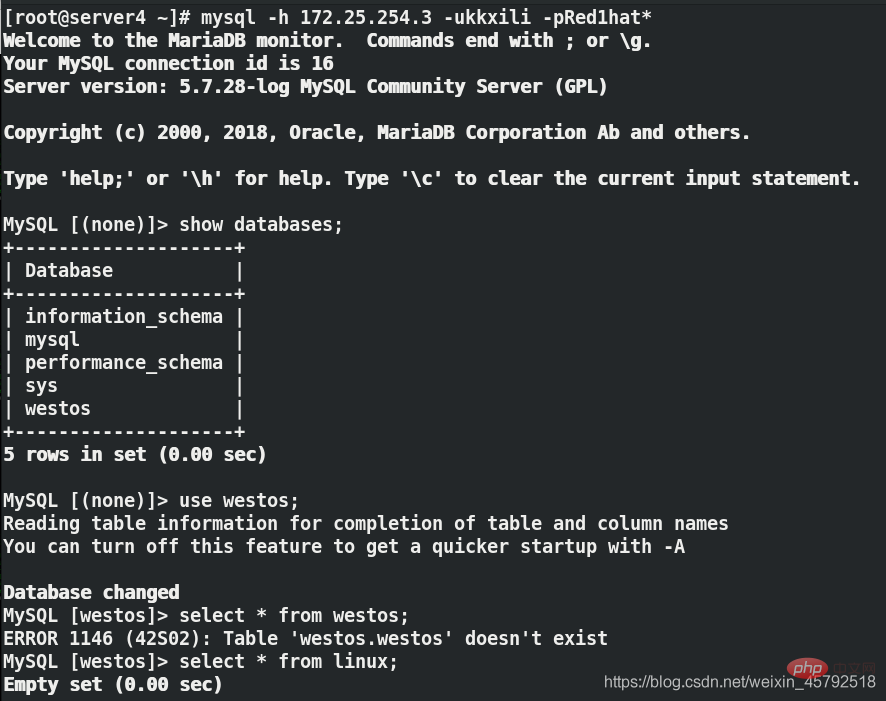
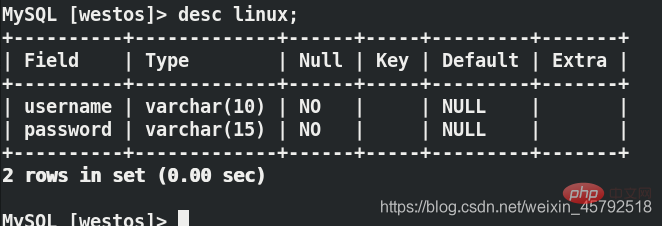
在server3上面:lsof -i:3306

(4)在用户端虚拟机server4上第二次连接数据库代理server3
在server3上面:lsof -i:3306

(5)在用户端虚拟机server4上第三次连接数据库代理server3
在server3上面:lsof -i:3306
开始读写分离
 上面是读写分离的读访问测试
上面是读写分离的读访问测试
写测试
在用户端插入数据
use westos;insert into linux values('user1','123');
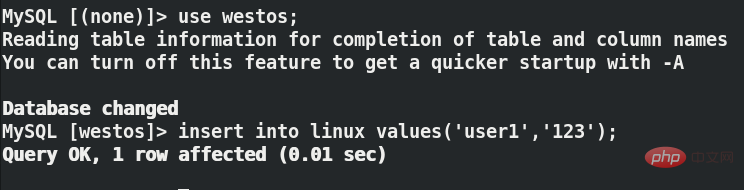
server1和server2都可以看到插入的数据
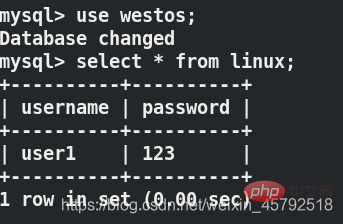
在server2中关闭主从复制
用户端再次写入数据,看不到刚刚写的数据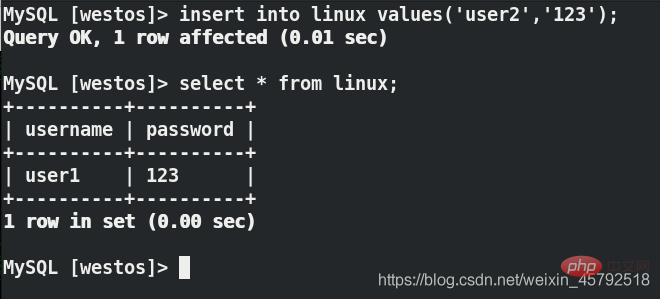
写在server1上,可以查看到数据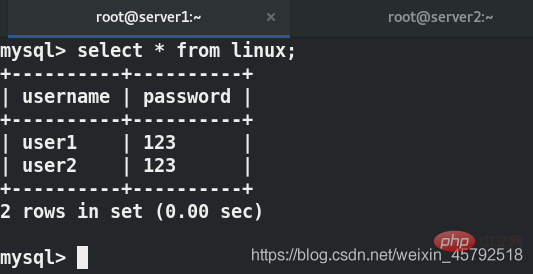
在server2上实现了读写分离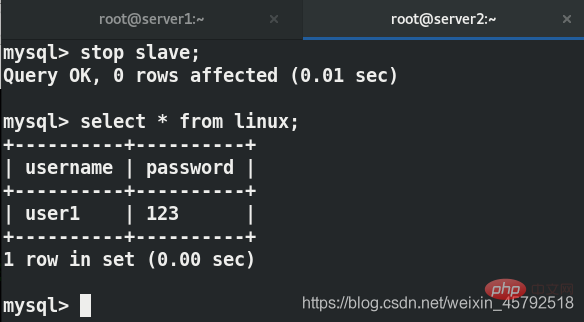
server2重新开启主从复制可以看到数据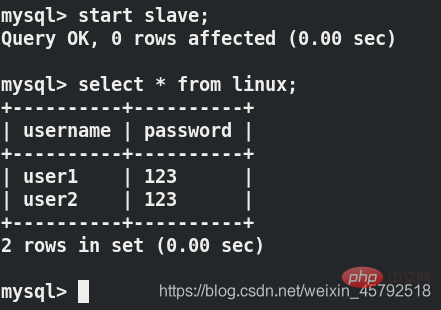
客户端读的是server2,server2只能读,不能写,因此看不到刚才写进去的东西,server1可以看到
实现了客户端(虚拟机)对server1的写,对server2的读
当访问数据库的用户数量很多时,数据库的代理就把后端的数据库实现读写分离
server1是写的数据库、server2是读的数据库
当server1和server2满足gtid的主从复制时,用户往数据库写入的数据其实是写入了server1,并没有写入server2,server2上面的数据是复制过去的,因此server1、server2、客户机上面都能查到刚刚写进去的数据,其实客户机查的是server2(读)
当关闭server1和server2的异步复制时,客户机往数据库写入的数据只写进了server1,没有写进去server2,server2也没有复制一份
因此server1可以查看到,server2和客户机上面都查不到刚刚写进去的数据,此时的客户机读的是server2
推荐学习:mysql视频教程
以上就是mysql读写分离实现方式是什么的详细内容,更多请关注创想鸟其它相关文章!
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 chuangxiangniao@163.com 举报,一经查实,本站将立刻删除。
发布者:程序猿,转转请注明出处:https://www.chuangxiangniao.com/p/283681.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 


















