deepin v20不能直接安装mysql所以先进行换源,更换成阿里源,这样以后速度可以更快,今天我们就来介绍一下deepin v20安装mysql的方法,有需要的可以参考一下。

deepin v20 换源和安装mysql
由于deepin v20不能直接安装mysql所以先进行换源,更换成阿里源,这样以后速度可以更快
修改文件 sudo vim /etc/apt/sources.list
#删除内容,并添加以下内容:## Generated by deepin-installerdeb [by-hash=force] https://mirrors.aliyun.com/deepin/ panda main contrib non-free
执行sudo apt-get update
执行sudo apt-get upgrade命令。
安装mysql
1.执行安装mysql的语句
sudo apt-get install mysql-server mysql-client
2.查看可登陆账户并查看密码
 如知AI笔记
如知AI笔记
如知笔记——支持markdown的在线笔记,支持ai智能写作、AI搜索,支持DeepseekR1满血大模型
 27 查看详情
27 查看详情 
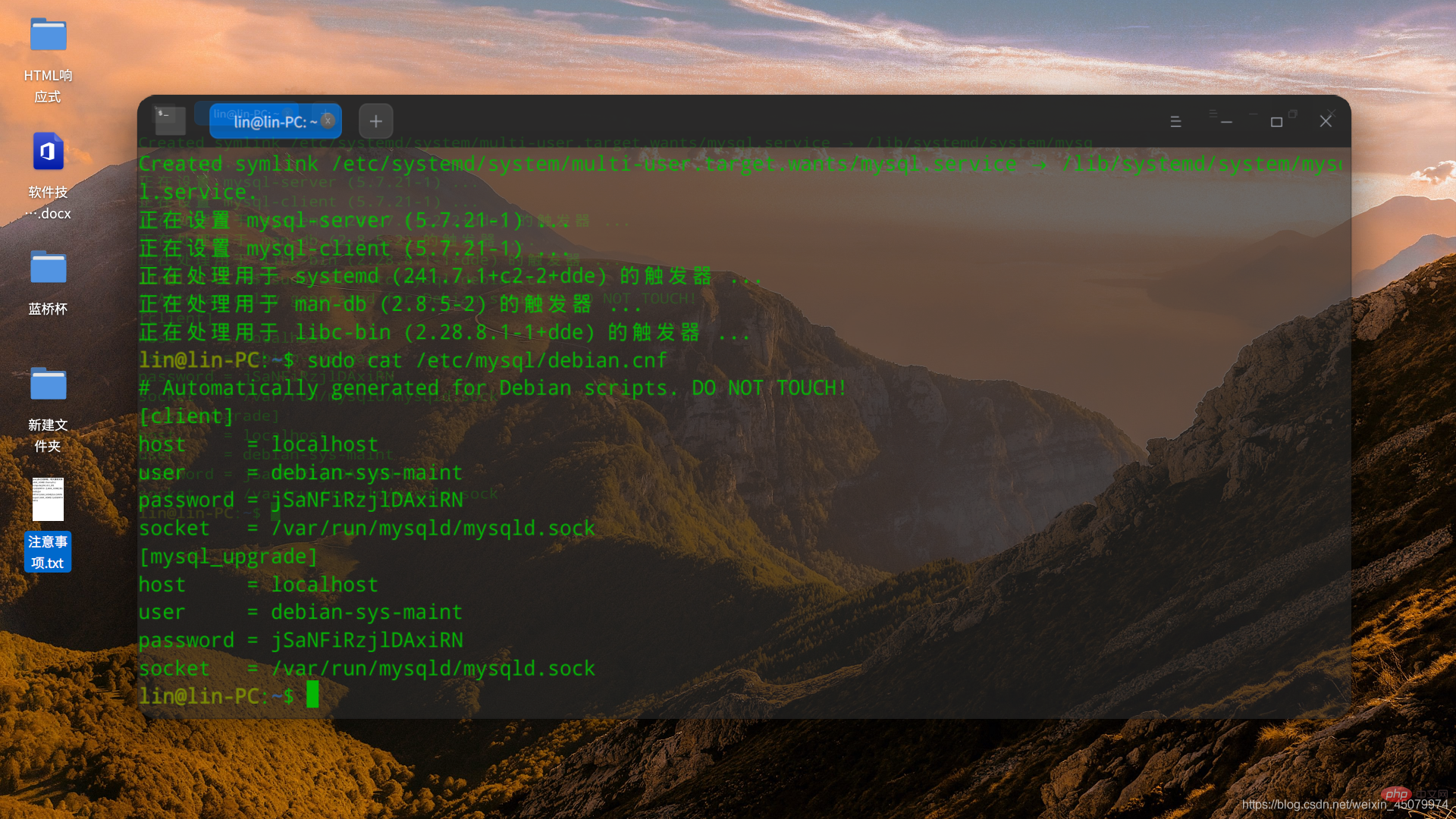
3.获取到了登陆mysql的账户密码
lin@lin-PC:~$ mysql -udebian-sys-maint -pjSaNFiRzjlDAxiRNmysql: [Warning] Using a password on the command line interface can be insecure.Welcome to the MySQL monitor. Commands end with ; or g.Your MySQL connection id is 2Server version: 5.7.21-1 (Debian)Copyright (c) 2000, 2018, Oracle and/or its affiliates. All rights reserved.Oracle is a registered trademark of Oracle Corporation and/or itsaffiliates. Other names may be trademarks of their respectiveowners.Type 'help;' or 'h' for help. Type 'c' to clear the current input statement.mysql>
4.之后依次进入mysql数据库,修改root密码,刷新缓存。之后就可以exit退出使用root账户登录了:
use mysql;update user set plugin="mysql_native_password",authentication_string=password('新密码') where user="root";FLUSH PRIVILEGES;
5.使用修改后的帐号密码登陆
mysql -uroot -p000000
相关推荐:《mysql教程》
以上就是deepin v20如何安装mysql的详细内容,更多请关注创想鸟其它相关文章!
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 chuangxiangniao@163.com 举报,一经查实,本站将立刻删除。
发布者:程序猿,转转请注明出处:https://www.chuangxiangniao.com/p/290176.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫