
月之暗面发布了名为 “kimi linear” 的混合线性注意力架构,据称在短距离、长距离及强化学习(rl)等多种扩展场景中均优于传统全注意力方法。kimi linear 由 3 份 kimi delta attention(kda)和 1 份全局 mla 组成。kda 是对 gated deltanet 的改进,通过细粒度门控来压缩有限状态 rnn 的记忆。
近日,Kimi Linear 核心作者分享了关于他对于该项目的一些感想:
作者:yzhangcs 链接:https://www.zhihu.com/question/1967345030881584585/answer/1967730385816385407
终于忙完了 Kimi Linear 的 Model Card 和 Paper ArXiv 上传,放空了半天。现在稍微分享一下个人感想,顺便做一些澄清。
模型架构
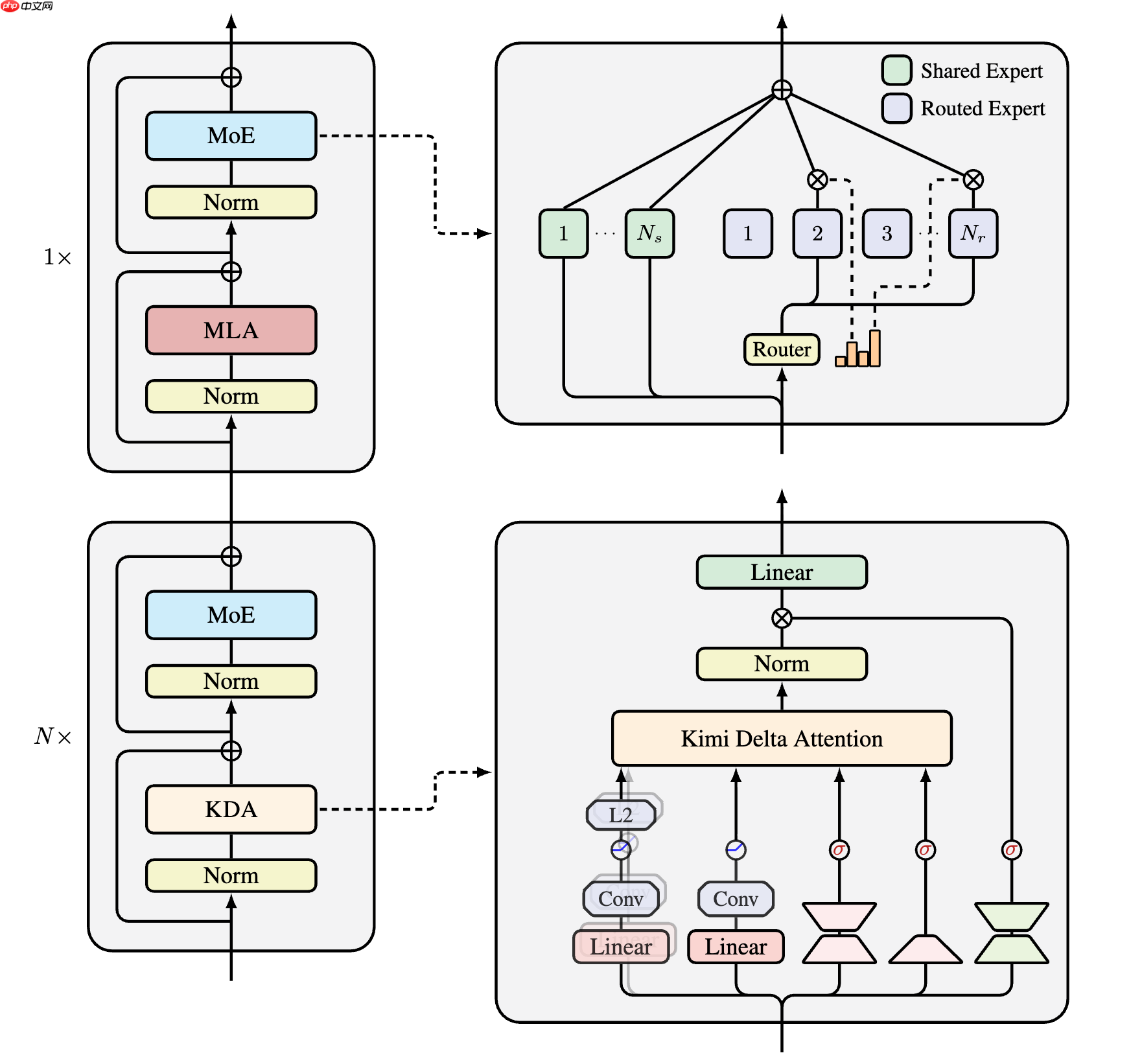
模型整体架构设计如图所示,延续了Moonlight的设计思路,别的回答已经有不少优秀的解读了。这次最大的不同在于我们将MoE的稀疏度设置得更激进,从8到32。 而 Kimi Linear 的核心设计原则,第一主要采用Linear Attention,这也是名字的由来,具体来说则是KDA,在GDN的基础上融入了 GLA 的细粒度门控。核心 Recurrent 公式中,关键的 Decay 部分已经标红了。
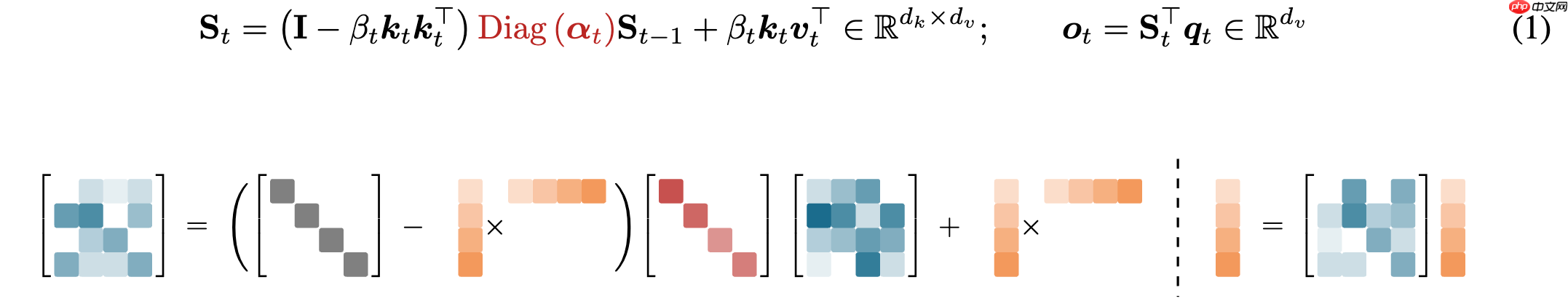
这张图的tikz代码主要修改自delta product,当然也借鉴了RWKV7,如果某些人认为这是抄袭那随便你
其次,这是一个hybrid model,考虑到纯Linear Attention对工业级 LLM 来说风险还是太大,我们最终采用了Hybrid Model的方案,也就是KDA:MLA的层混合比例为3:1。经过Ablation Study,我们发现3:1是兼顾效率和性能的最优比例。
最终成果是,在相同的 5.7T Token 训练量以及相似的 3B 激活参数下,模型效果得到了巨大提升。我们的许多 Benchmark 对比都呈现出「大人打小孩」的态势,说实话有些setting不太 fair,只能说它作为一个小规模模型训出的成果,能够给大家带来一些新的 vibe。
个人体验下来感觉非常棒,在一些野生玩家那里体验也挺好的。(https://www.reddit.com/r/LocalLLaMA/comments/1ojz8pz/kimi_linear_released/)
虽然在 math/code 等一些 benchmark 上由于训练量和参数规模还很不够,比不上其他厂商同参数规模的模型,但模型的 personality非常出色,比较有小K2感。在解码方面,如果考虑到 KDA 的 KV Cache 占用小带来的 Batch Size 补偿,最终加速比能达到 6 倍左右。整体效果完全符合预期。
个人感想
训练过程
这是第一次作为核心成员去 scale 这么大的模型,之前个人 research 玩得最多也就是 7B Dense,训个 100B Token,32 卡跑个几天也就够了。这次则是 scale 到了 48B MoE 的规模,5.7T 的训练量。当然,对真正的大模型来说这还是只小卡拉米,不过对我个人来说算是一次突破。 管理模型训练是一件非常难受的事情。分布式总是会中断,尽管有自动重启,但还是不太放心,因此总是需要人盯。然后本人作息又非常抽象,和 collaborator 们(johnson & momo,名字用代号了)经常是 UTC+8 过湾区时间,湾区过北京时间。
Ablation 也经过了漫长的过程,有不少细节论文中没有提到。比如NoPE 还是 RoPE经过怎样的选择;Forget gate 到底选择是 pure sigmoid 还是 GDN style;output gate 的作用,这些都经过了漫长的探索,我们综合考虑short & long context最终才收敛到了现在的形式。
Scaling Ladder 是 Kimi 内部 scale 模型的一个传统。我们会从一个小的(比如 1B 激活参数)开始做起,逐步在 Benchmark 上要打败 Baseline,与此同时需要监控相应的「内科」。等到每个 scale 的每一关都过了,才会进行到下一阶段。并且由于 Hybrid Linear 是开天辟地头一遭,自然经过了更多的审视。比如长文有很多典型Benchmark,MRCR、RULER、Frames 等等作为拦路虎,当有一个明显差异都要 revert 到上一阶段,无论是查 Bug 还是看推理引擎(对于 MoE 模型,评测时推理引擎的支持是必不可少的,否则速度无法忍受)。这些我都非常理解也很认同,但是当多种因素交织时——到底是推理 Bug 导致掉点,还是「内科」炸了,还是 Linear 本身不行——导致的失败会让人非常沮丧。 最终的5.7T训练过程也是波折不断,比如模型中有两个A_log,bias参数,一开始训的时候是保持的bf16,整个阶段虽然没炸,但一直都在上涨,让人很担心,后来训练中途切到了fp32,发现这两个vector的max value 飞速下降,这才意识到对于这些关键参数保持fp32是非常必要的,但是我们是中途切换,有多大的影响呢?不知道,只能说是对于flagship model的一次derisk了。
好在最后我们交出了一份还算满意的答卷。
关于postrain,之前 Moonlight 级别的 posttrain recipe 还不太成熟,有尝试过直接迁移 K2的方案,发现会遇到一些不太吸收的问题。为此和 fanqing & chengyin,还有 postrain team 的小伙伴进行了长时间的攻坚,期间尝试了几十种不同的数据配方。 我们也观测到许多有意思的现象,特别是对于 Kimi Linear 这种 scale 的小模型而言,榜单成绩和实际使用体验往往是不可兼得的。 如果 Math & Code 分数很高,你往往Vibe起来会非常差(非常 Thinking)。因此,最终我们选择了一个在榜单成绩和实际体验之间平衡得比较好的方案。
Bitter Lesson:这篇 Tech Report 最初的目标是达到类似size模型的SOTA。但事后来看资源限制短时间内没法达成这个目标。 因此最后我们的主战场放到了 1T fair comparisons 上,这些实验本身是 Scaling Ladder 的一部分,也都满足公平比较。后面还是希望释放更多的 Fair Baseline,有一些更丰富的比较。因此这个 Report 的定位是一个技术验证,也是下一代K3的前奏。
其他
这两天看到了非常多关于 model 和 arch 的评价,最大的部分是关于和 RWKV7 的比较,区别是什么 @sonta在另一个回答已经说了,如果你们还是觉得一样那随便你好了。
Kimi 的目标是下一代 flagship models,正如 Moonlight 中致敬了 Muon 的作者,Kimi Linear 也会引用能够aware 的 previous work,不存在刻意忽略的动机,以及我想说,与其整天拉踩别人,还是好好想想怎么 scale 自己的东西吧,整天对线又有啥用呢?
我想说我觉得个人在一个比较恰当的时机加入了 Kimi,恰好在 deepseek R1 开源的时候,促使各家厂商都纷纷转向了开源(因此今年仍然有机会继续维护 FLA,顺手实现了 NSA :)),刚好今年算是 agent 大年,对于动辄 32k + 的推理长度,Linear Attention 刚好可以发挥所长。并且个人作为 FLA 的 core contributors 之一,将之发扬光大给了我最大的驱动力。去年一整年都捐给了 FLA,增加了 scaling 的各种支持,各种配套的 fused kernels,Cache 管理,varlen training,FLA 各种状态都 ready 了,顺风顺水来到了一个关键的时间节点被 scaling。并且我也觉得时间窗口会比较短暂,大家本身就是对 hybrid model 将信将疑,如果 FLA team @sonta @zhiyuan1i 都没法去 scaling 或者 scaling 失败了,那这条技术路线就会受到很大的质疑。好在目前看起来的结果还行。
当前,Linear Attention 的迭代路线正逐渐收敛到 Delta-variants。近期也有很多其他工作浮现,如TTT/Titans,但这些方法在硬件效率方面似乎仍有待提升。与此同时,Sparse Attention 也成为了另一条备受关注的技术路线,尤其是 NSA的设计理念,我个人非常欣赏。然而,究竟哪条技术路线更具优势,目前仍是一个未知数。总的而言,Efficient Attention无疑是当前研究领域的一大聚焦点。希望 Kimi 此次开源的 KDA能够为业界带来更多启发,推动Hybrid models的真正落地!
以上就是Kimi Linear 一作张宇:关于模型训练的一些感想的详细内容,更多请关注创想鸟其它相关文章!
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 chuangxiangniao@163.com 举报,一经查实,本站将立刻删除。
发布者:程序猿,转转请注明出处:https://www.chuangxiangniao.com/p/303650.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 



























