
该项目基于PPOCRLabel半自动化标注工具,使用Python和PyQt5编写,支持多种语言模型,可实现OCR数据高效标注。项目通过代码生成身份证数据集,利用PPOCRLabel标注后用于OCR模型训练,还提供了配置好的环境及相关资料,鼓励用户加入SIG小组共同开发。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

项目简介
本项目基于PPOCRLabel标注工具,PPOCRLabel是一款适用于OCR领域的半自动化图形标注工具,内置PPOCR模型对数据自动标注和重新识别,使用python3和pyqt5编写,支持矩形框标注和四点标注模式(多点标注我已经提交了PR,等待那边审核),导出格式可直接用于PPOCR检测和识别模型的训练。通过内置高质量的PPOCR中,英,法,日文等超轻量预训练模型,可以实现OCR数据的高效标注。CPU机器运行也是完全没问题的。
******** 标注环境 ******** 系统 : Windows + Anaconda 解释器环境 : 安装Anaconda,(Python 3+)
按官方文档执行完以下命令
conda install pyqt=5
cd ./PPOCRLabel # 将目录切换到PPOCRLabel文件夹下
pyrcc5 -o libs/resources.py resources.qrc
python PPOCRLabel.py
SIG兴趣小组
SIG队伍:如果您对以上内容感兴趣或对完善工具有不一样的想法,欢迎加入我们的SIG队伍与我们共同开发。可以在此处完成问卷和前置任务,经过我们确认相关内容后即可正式加入,享受SIG福利,共同为OCR开源事业贡献(特别说明:针对PPOCRLabel的改进也属于PaddleOCR前置任务) 还会有各种精美百度定制小礼品,期待你的加入!
关于本项目
本项目基于自己生成身份证数据集代码及其使用PPOCRLabel标注工具来自制数据集,完成全流OCR光学字符识别的从零开始到模型使用。对项目还存在的改进空间,希望大家多交流观点、介绍经验,共同学习进步,可以互相关注♥。个人主页
相关资料
已标注完毕身份证数据集链接
数据增广工具Style Text 这里就不多叙述了,在你的数据集不够的情况下可以使用数据增广工具Style Text. 可以参考这个项目 StyleText数据合成工具
基于OCR身份证号码识别全流程 已经训练完,正在完善MD笔记
PPOCRLabel半自动标注工具的环境配置比较麻烦,所以这里作者把已经配置好的环境放在百度云盘里面,直接免费提供。点我直接下载
1、代码制作身份证数据集
In [1]
#导入所需要的包from PIL import Image, ImageDraw, ImageFontimport numpy as npimport cv2import random
1.1 存放所需属性Person抽象类
In [2]
class Person(object): def __init__(self, name, sex, national, years, month, day, address, id_card): self.name=str(name), self.sex=str(sex), self.national=str(national), self.years=str(years), self.month=str(month), self.day=str(day), self.address=str(address), self.id_card=str(id_card)
1.2 定义生成姓名, 性别, 民族, 出生年月, 户籍地址, 身份证ID的函数
In [3]
def GBK2312(): """ 功能 : 随机生成一个汉字 """ head = random.randint(0xb0, 0xf7) body = random.randint(0xa1, 0xf9) # 在head区号为55的那一块最后5个汉字是乱码,为了方便缩减下范围 val = f'{head:x}{body:x}' st = bytes.fromhex(val).decode('gb2312') return stdef first_name(): """ 功能 : 随机取姓氏字典 """ first_name_list = [ '赵', '钱', '孙', '李', '周', '吴', '郑', '王', '冯', '陈', '褚', '卫', '蒋', '沈', '韩', '杨', '朱', '秦', '尤', '许', '何', '吕', '施', '张', '孔', '曹', '严', '华', '金', '魏', '陶', '姜', '戚', '谢', '邹', '喻', '柏', '水', '窦', '章', '云', '苏', '潘', '葛', '奚', '范', '彭', '郎', '鲁', '韦', '昌', '马', '苗', '凤', '花', '方', '俞', '任', '袁', '柳', '酆', '鲍', '史', '唐', '费', '廉', '岑', '薛', '雷', '贺', '倪', '汤', '滕', '殷', '罗', '毕', '郝', '邬', '安', '常', '乐', '于', '时', '傅', '皮', '卞', '齐', '康', '伍', '余', '元', '卜', '顾', '孟', '平', '黄', '和', '穆', '萧', '尹', '姚', '邵', '堪', '汪', '祁', '毛', '禹', '狄', '米', '贝', '明', '臧', '计', '伏', '成', '戴', '谈', '宋', '茅', '庞', '熊', '纪', '舒', '屈', '项', '祝', '董', '梁', '魏'] n = random.randint(0, len(first_name_list) - 1) f_name = first_name_list[n] return f_namedef second_name(): """ 功能 : 随机取数组中字符,取到空字符则没有second_name """ second_name_list = [GBK2312(), ''] n = random.randint(0, 1) s_name = second_name_list[n] return s_namedef last_name(): """ 功能 : 随机生成名字最后一位字 """ return GBK2312()def create_name(): """ 功能 : 随机生成名字 """ name = first_name() + second_name() + last_name() return namedef sex_word(): """ 功能 : 随机生成性别 """ nums = random.randint(0,3) sex_list = [ '男', '女', '机器人', '未知'] return sex_list[nums]def address_name(): """ 功能 : 随机生成省份 """ first_name_list = [ '黑龙江省哈尔滨', '吉林省长春', '辽宁省沈阳', '河北省石家庄', '山西省太原', '青海省西宁', '山东省济南', '河南省郑州', '江苏省南京', '安徽省合肥', '浙江省杭州', '福建省福州', '江西省南昌', '湖南省长沙', '湖北省武汉', '广东省广州', '台湾省台北', '海南省海口', '甘肃省兰州'] n = random.randint(0, len(first_name_list) - 1) address_name = first_name_list[n] return address_namedef random_id_card(): """ 功能 : 随机生成18位身份证ID """ num_str = '' _rand = random.randint(0, 100) for i in range(17): # # num_str=str(random.randint(0, 9)).zfill(17) num_str = num_str + str(random.randint(0, 9)) if _rand >= 92: num_str = num_str + 'X' else: num_str = num_str + str(random.randint(0, 9)) return num_strdef to_str(per): """ 功能 : 将元祖转为str """ _str =''.join(per) return _str
两种起名方式
import randomdef Unicode(): name = "" nums = random.randint(2,4) for n in range(nums): val = random.randint(0x4e00, 0x9fbf) name = name + chr(val) return namename = Unicode()name
1.3 定义画板, 黑体等函数
In [4]
# 定义写字函数def add_txt(image, size, draw_x, draw_y, txt): # 字体字号 setFont = ImageFont.truetype('IDTemplate/simhei.ttf', size) # 定义画板 draw = ImageDraw.Draw(image) # 绘制 draw.text((draw_x, draw_y), txt, font=setFont, fill=(0, 0, 0)) return image def make_fake_id_card(person): ori_image = cv2.imread('./IDTemplate/IDCard{}.png'.format(random.randint(0,8))) print('==ori_image.shape:', ori_image.shape) ori_image = cv2.resize(ori_image, (0, 0), fx=0.4, fy=0.4) print('==resize ori_image.shape:', ori_image.shape) # 向图片上写字 img = Image.fromarray(cv2.cvtColor(ori_image, cv2.COLOR_BGR2RGB)) img = add_txt(img, 19, 97, 58, to_str(person.name)) #字体 x坐标 y坐标 img = add_txt(img, 16, 97, 90, to_str(person.sex)) img = add_txt(img, 16, 190, 90, to_str(person.national)) img = add_txt(img, 16, 92, 118, to_str(person.years)) img = add_txt(img, 16, 162, 118, to_str(person.month)) img = add_txt(img, 16, 201, 118, to_str(person.day)) img = add_txt(img, 16, 94, 155, to_str(person.address)) img = add_txt(img, 16, 94, 176, '某某 666号') img = add_txt(img, 18, 147, 239, to_str(person.id_card)) cv2.imwrite('./train_data/middleIMG/word.jpg', np.array(img)[..., ::-1]) def make_white_mask(person, nums): # 生成一个空白的模板mask ori_image = cv2.imread('./IDTemplate/IDCard{}.png'.format(random.randint(0,8))) ori_image = cv2.resize(ori_image, (0, 0), fx=0.4, fy=0.4) mask_image = np.ones_like(ori_image) mask_image *= 255 print(mask_image.shape,' {}.jpg'.format(nums)) cv2.imwrite('./train_data/middleIMG/mask.jpg', mask_image) # 往空白模板上写字(这里只能用PIL写,因为OpenCV写中文会乱码) img = Image.fromarray(cv2.cvtColor(ori_image, cv2.COLOR_BGR2RGB)) img = add_txt(img, 19, 97, 58, to_str(person.name)) #字体 x坐标 y坐标 img = add_txt(img, 16, 97, 90, to_str(person.sex)) img = add_txt(img, 16, 190, 90, to_str(person.national)) img = add_txt(img, 16, 92, 118, to_str(person.years)) img = add_txt(img, 16, 162, 118, to_str(person.month)) img = add_txt(img, 16, 201, 118, to_str(person.day)) img = add_txt(img, 16, 94, 155, to_str(person.address)) img = add_txt(img, 16, 94, 176, '某某 666号--自制数据集') img = add_txt(img, 18, 147, 239, to_str(person.id_card)) mask_image_txt = cv2.cvtColor(np.array(img), cv2.COLOR_RGB2BGR) cv2.imwrite('./train_data/middleIMG/mask_image_txt.jpg', mask_image_txt) gray = cv2.cvtColor(mask_image_txt, cv2.COLOR_BGR2GRAY) # 高斯模糊,制造边缘模糊效果哦 gray_Gaussianblur = cv2.GaussianBlur(gray, (3, 3), 0) # 使用阈值对图片进行二值化 th, res = cv2.threshold(gray_Gaussianblur, 200, 255, cv2.THRESH_BINARY) res_inv = cv2.bitwise_not(res) cv2.imwrite('./train_data/middleIMG/res_inv.jpg', res_inv) # 写字的模板保留文字部分 img_bg = cv2.bitwise_and(mask_image_txt, mask_image_txt, mask=res_inv) cv2.imwrite('./train_data/middleIMG/img_bg.jpg', img_bg) # 原图保留除文字的其他部分 img_fg = cv2.bitwise_and(ori_image, ori_image, mask=res) cv2.imwrite('./train_data/middleIMG/img_fg.jpg', img_fg) # 将两张图直接进行相加,即可 final = cv2.add(img_bg, img_fg) cv2.imwrite('./train_data/{}.jpg'.format(nums), final)
In [5]
!mkdir -p train_data/middleIMG
In [6]
if __name__ == '__main__': # make_fake_id_card() for i in range(3200): person = Person(name=create_name(), sex=sex_word(), national='汉', years=str(random.randint(1970, 2020)), month=str(random.randint(1, 12)), day=str(random.randint(1, 28)), address=address_name(), id_card=random_id_card()) make_white_mask(person, str(i).zfill(4))
1.4 自制数据集各个文件展示
二值化:train_data/middleIMG/res_inv.jpg

写字的模板保留文字部分:train_data/middleIMG/img_bg.jpg

原图保留除文字的其他部分:train_data/middleIMG/img_fg.jpg

最终效果 :
原图和写字的两张图直接进行相加:train_data/0000.jpg

1.5 存储自制数据集,准备放入PPOCRLabel自行标注
In [7]
#解压zip !zip -q -r train_data.zip train_data/
2、PPOCRLabel半自动标注工具
2.1 解压标注工具在本地
git clone https://github.com.cnpmjs.org/paddlepaddle/PaddleOCR.git

2.2 PyCharm 打开项目 (用别的工具也可以)
PPOCRLabel半自动标注工具的环境配置比较麻烦,所以这里作者把已经配置好的环境放在百度云盘里面,直接免费提供。点我直接下载
2.3 环境配置
第一步 : 要有Anaconda Navigator (Anaconda3) ,推荐去官网下载,下载完! 打开文件夹环境所在位置,例如我的环境是(D:Anaconda3envs)
 集简云
集简云
软件集成平台,快速建立企业自动化与智能化
 22 查看详情
22 查看详情 
下载完百度云盘的LabelImg.zip文件之后,解压到自己的 Anaconda3envs 文件夹下。完整目录就是 D:Anaconda3envsLabelImg 。
运行环境百度云链接与提取码—->链接:https://pan.baidu.com/s/1zYrmVkwkL69mziO_wnUNDg 提取码:6666
示例如下图所示:
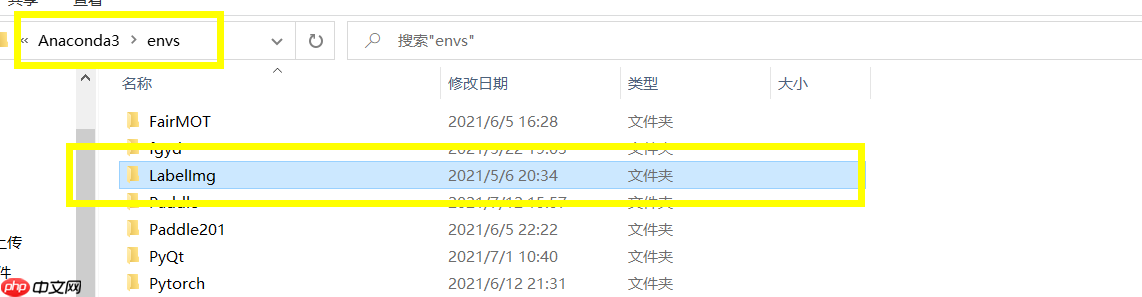
第二步 : 接下来图文操作, Ctrl + Alt + S 打开设置
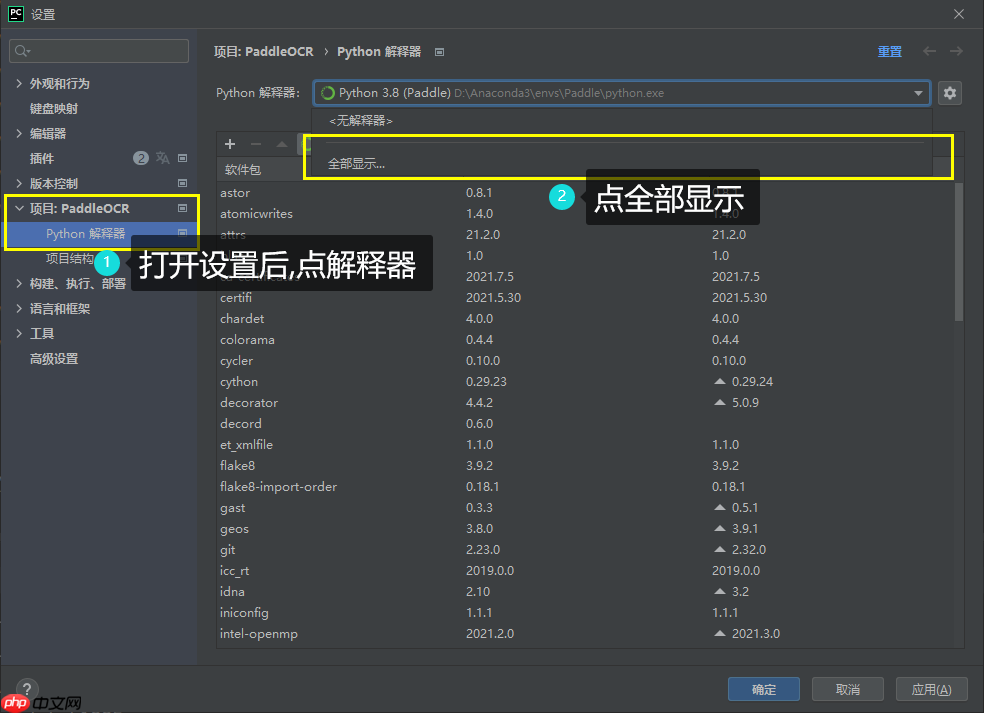
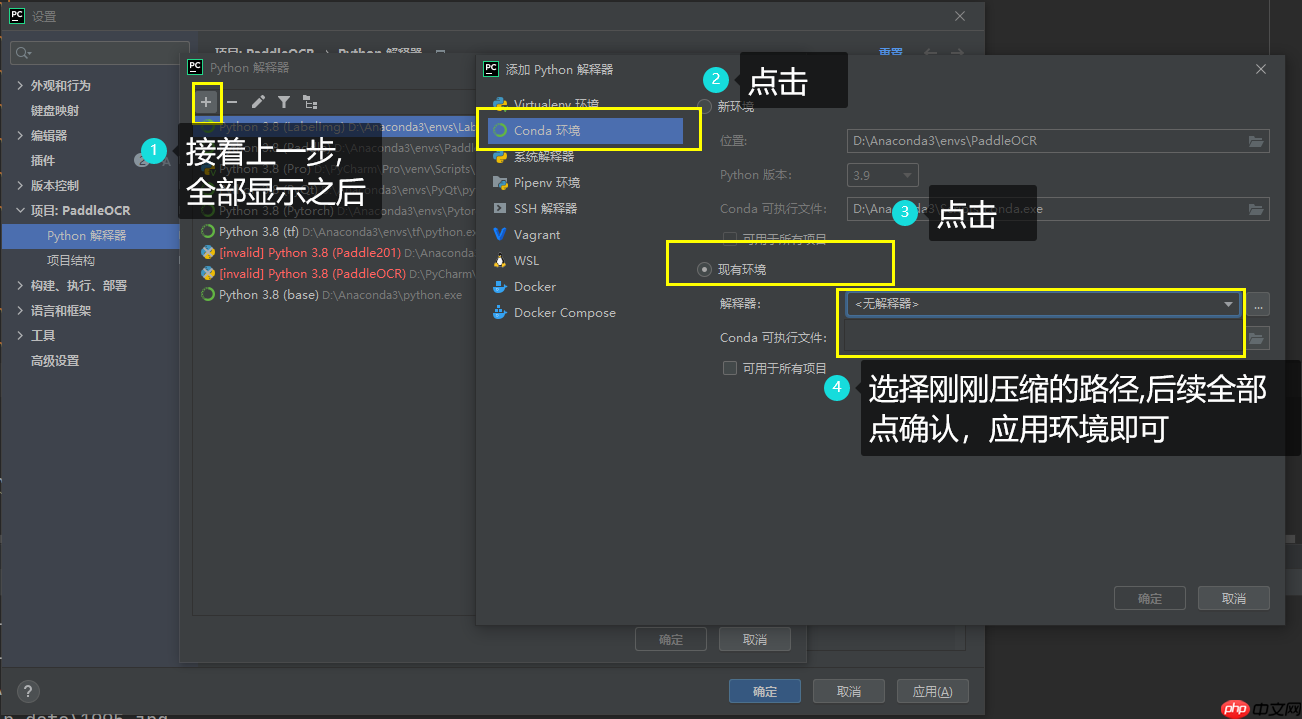
第三步 : 在pycharm终端运行更新资源指令: pyrcc5 -o libs/resources.py resources.qrc
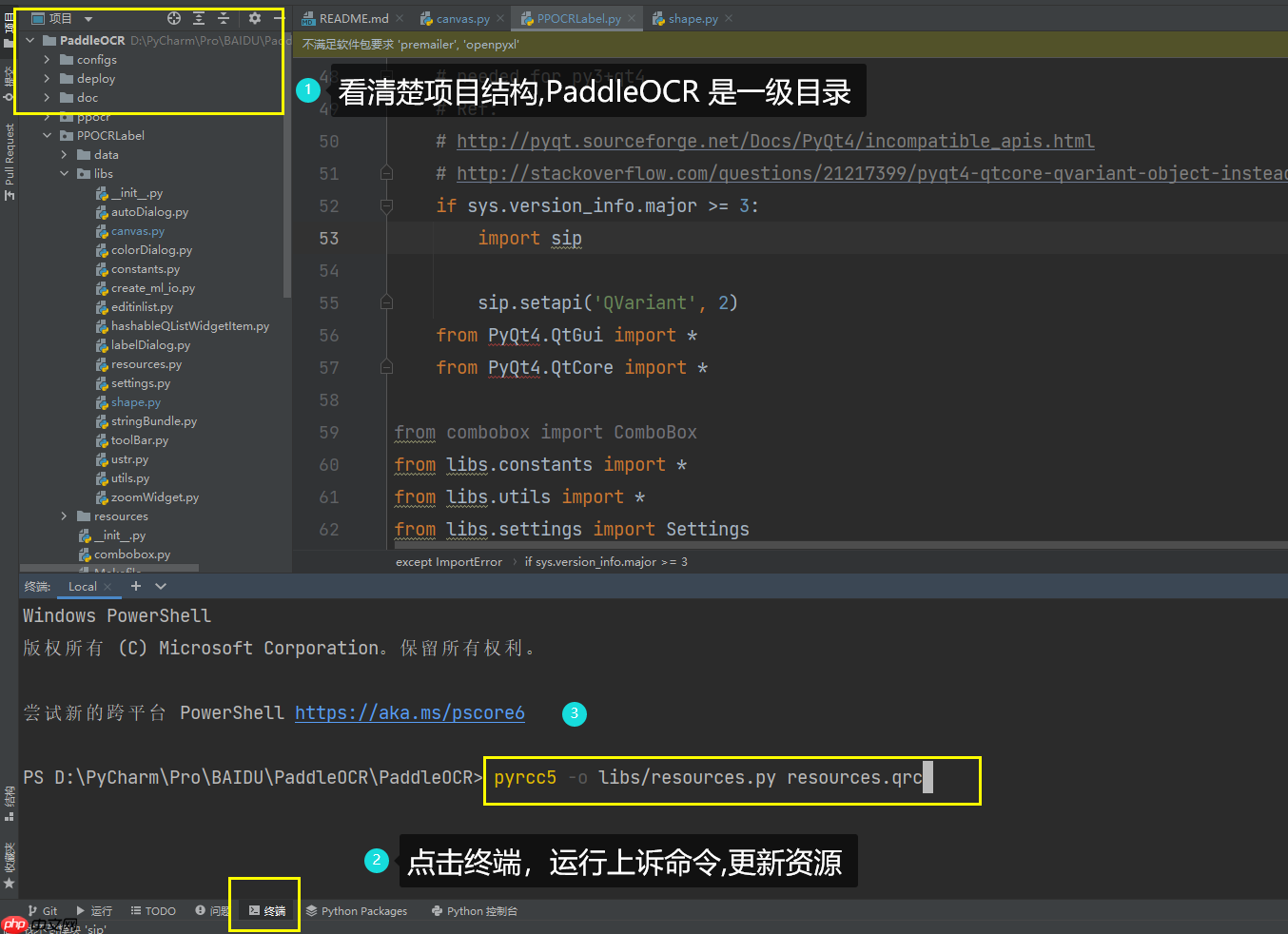
最后一步 : 运行即可 PaddleOCRPPOCRLabelPPOCRLabel.py 运行PPOCRLabel.py
开始会下载已经训练好的模型权重,如下图 :
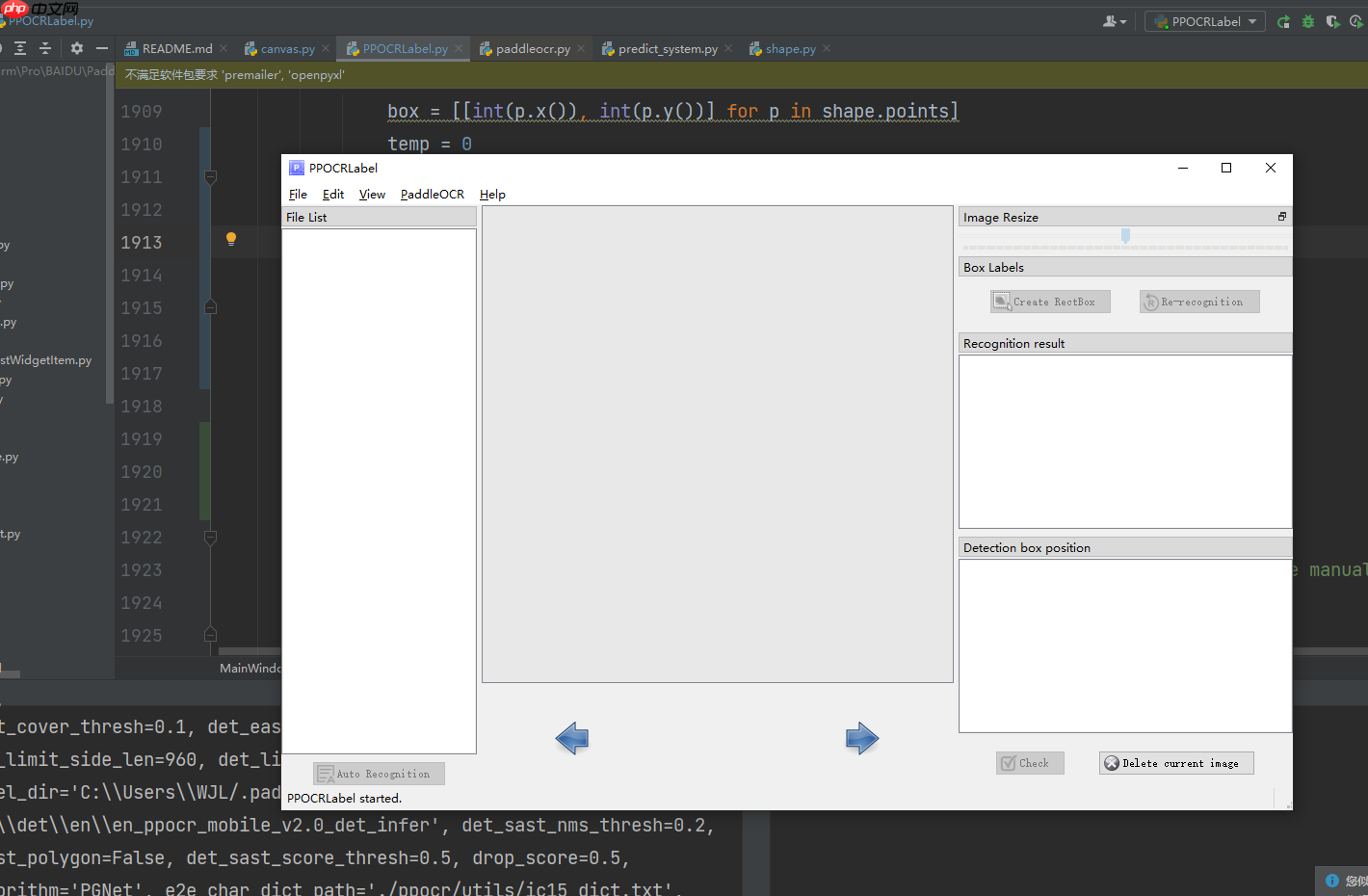
运行成功截图 :
3、使用PPOCRLabel标注工具标注
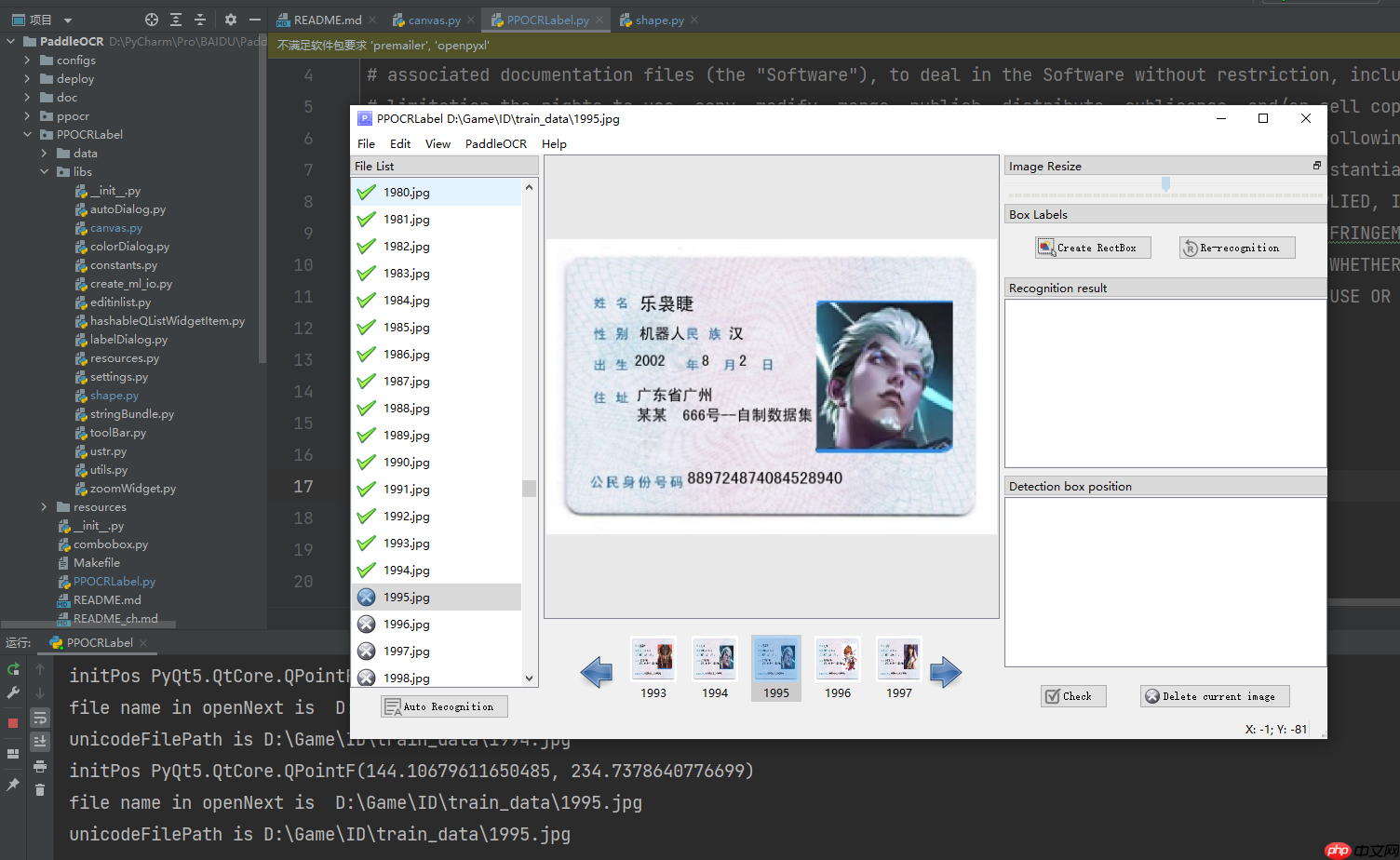
3.1 选择好我们生成的train_data数据集文件
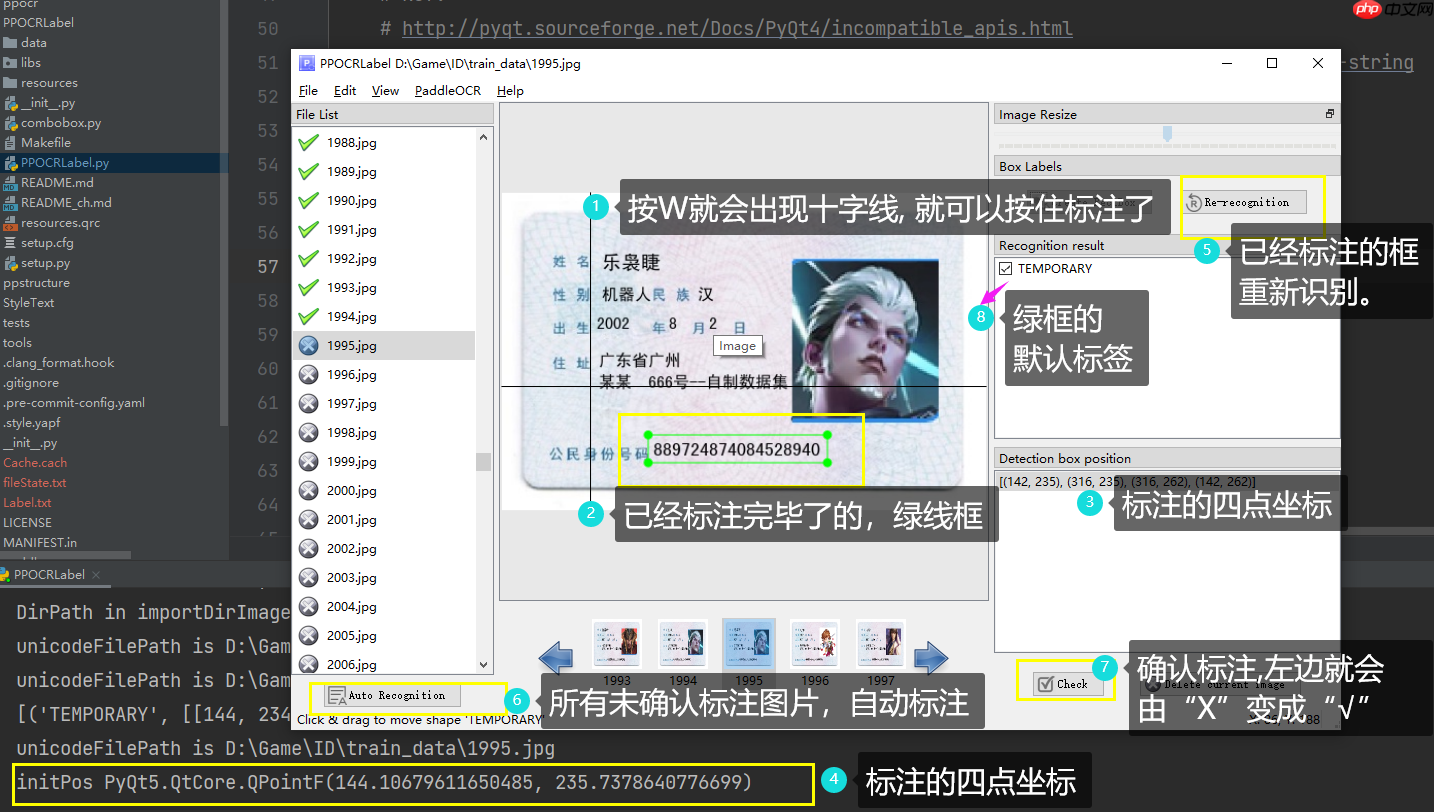
3.2 点标注或者四点矩形框标注
用过标注工具的同学,应该都知道怎么标注了。 按 W 是四点矩形框标注 ,按 Q 是点标注,我已经在SIG小组实现四点及其以上的标注框,欢迎大家参加SIG小组,为开源做贡献
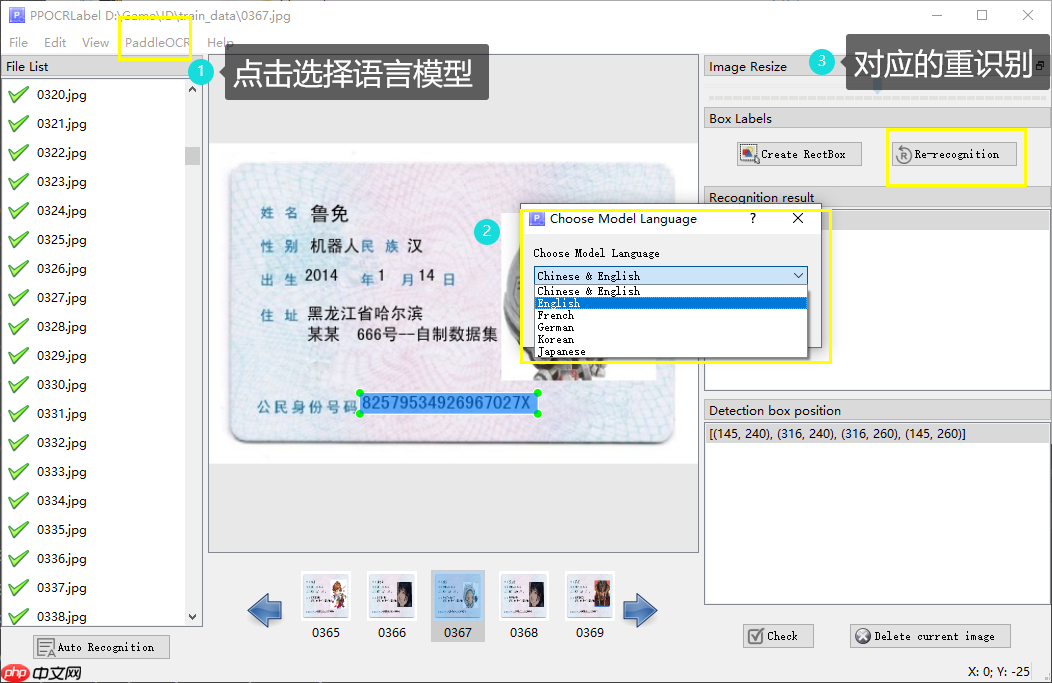
3.3 切换对应模型重识别,更高效的自动标注
PPOCRLabel人性化的推出了各个常见语言的训练模型,
如下图 :
1.中文与英文模型权重 2.英文模型权重 3.法语模型权重 4.德语模型权重 5.韩文模型权重 6.日文模型权重
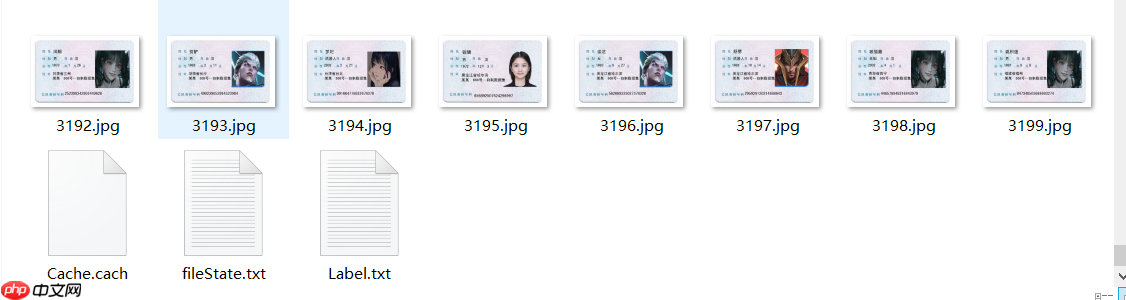
3.4 生成给Det的标注文件分别为如下三个
Cache.cach : 标注的缓存文件
fileState.txt : 标注的每个图片的状态文件 1 则是确认标注 0 则是未确认
Label.txt : 训练Det所需要的训练文件,数据集格式属于:SimpleDataSet
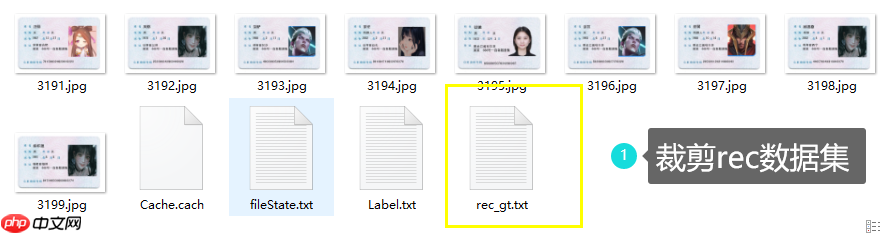
3.5 如何生成给Rec的标注文件
打开菜单点击导出rec识别的label即可,如右图文所示 : 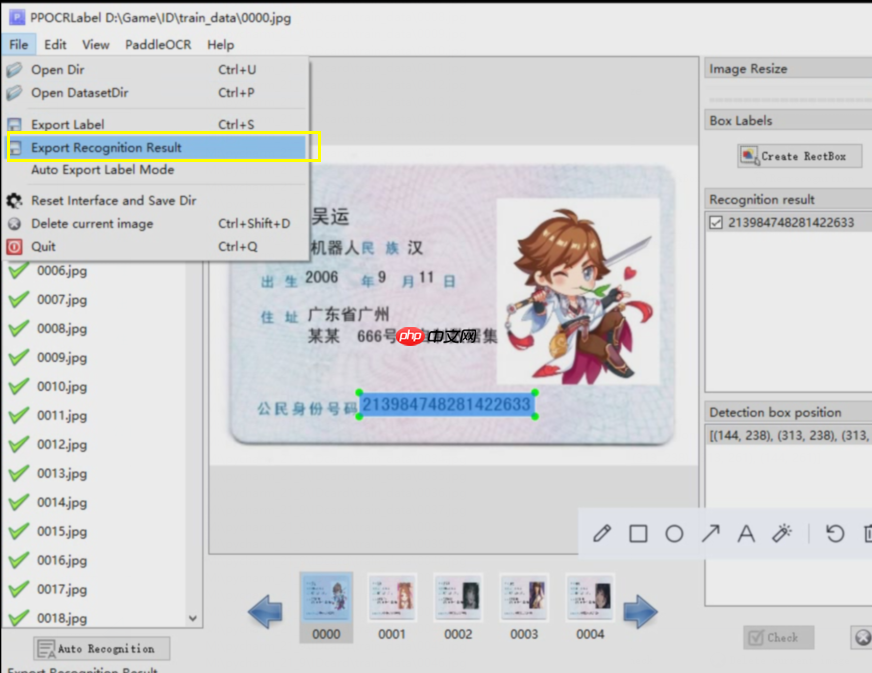
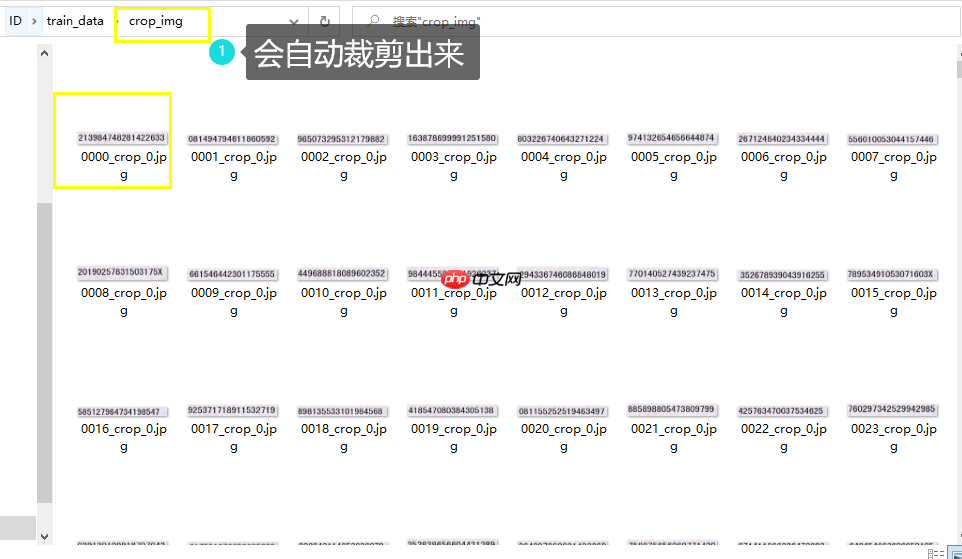
导出结果会生成一个截出框的图片文件夹,以及对应的rec标签
以上就是PPOCRLabel半自动工具标注自制身份证数据集的详细内容,更多请关注创想鸟其它相关文章!
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 chuangxiangniao@163.com 举报,一经查实,本站将立刻删除。
发布者:程序猿,转转请注明出处:https://www.chuangxiangniao.com/p/315564.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 





















