
本文介绍BIT-CD模型复现,该模型将Transformer引入遥感图像变化检测。以改进的ResNet18孪生网络为Backbone提取特征,经Bitemporal Image Transformer处理,再由Prediction Head生成变化预测。还包含环境数据准备、模型训练验证及TIPC测试等内容,在LEVIR-CD测试集F1-Score达89.31%。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

【第六期论文复现赛-变化检测】Remote Sensing Image Change Detection with Transformers
一、前言介绍
Paper地址: Remote Sensing Image Change Detection with Transformers参考github:https://github.com/justchenhao/BIT_CD复现地址:https://github.com/kongdebug/BIT-CD-Paddle
论文简介
BIT-CD的结构如下图所示。作者通过一个CNN骨干网络(ResNet)从输入图像对中提取高层语义特征,并且使用空间注意力将每个时间特征图转换成一组紧凑的语义tokens。然后使用一个transformer编码器在两个tokens集中建模上下文,得到了富有上下文的tokens被一个连体transformer解码器重新投影到像素级空间,以增强原始像素级特征。最终,作者从两个细化的特征图计算特征差异图像(FDIs),然后将它们送到浅层CNN以产生像素级变化预测。
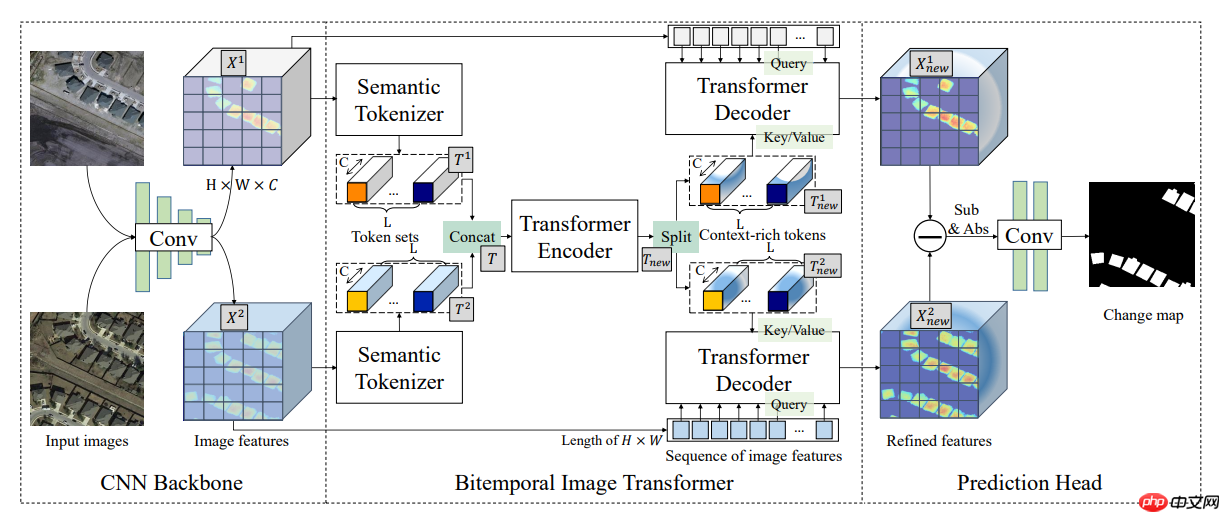
二、模型结构
注:以下BIT的模型分析参考CSDN博客:VisionTransformer(三)BIT—— 基于孪生网络的变化检测结构分析
BIT主要思想是将Transformer引入变化检测领域,整体结构如上图所示,分为三个大块:Backbone,为两个改进的ResNet18组成的孪生网络Bitemporal Image Transformer,为Transformer从孪生网络输出的相似特征图进一步提特征Prediction Head,利用Transormer decoder出来的特征,生成和输出尺寸一致的分割图像
2.1 backbone,改进的ResNet18孪生网络
孪生网络的概念在【第六期论文复现赛-变化检测】SNUNet-CD已经做出解释,不再赘述
BIT不同于SNUNet-CD使用UNet++的结构做主干提取变化的特征,而是使用了对ResNet18改进后的网络,主要做了以下两点修改:
将Resnet18中最后两个stages的下采样改为1在ResNet之后添加了一个逐点卷积降低特征维数,然后使用双线性插值得到下采样因子为4的特征图
这样的做法能够减少空间细节的损失,并一定程度上增大感受野,最后BIT模型取得性能最好的是使用前四个stages,然后直接加上最后的上采样和输出卷积的Backbone,论文中的命名为ResNet18_S4
代码如下
 论论App
论论App
AI文献搜索、学术讨论平台,涵盖了各类学术期刊、学位、会议论文,助力科研。
 23 查看详情
23 查看详情 
class Backbone(nn.Layer, KaimingInitMixin): def __init__(self, in_ch, out_ch=32, arch='resnet18', pretrained=True, n_stages=5): super(Backbone, self).__init__() expand = 1 strides = (2, 1, 2, 1, 1) if arch == 'resnet18': self.resnet = resnet.resnet18( pretrained=pretrained, strides=strides, norm_layer=get_norm_layer()) elif arch == 'resnet34': self.resnet = resnet.resnet34( pretrained=pretrained, strides=strides, norm_layer=get_norm_layer()) else: raise ValueError self.n_stages = n_stages if self.n_stages == 5: itm_ch = 512 * expand elif self.n_stages == 4: itm_ch = 256 * expand elif self.n_stages == 3: itm_ch = 128 * expand else: raise ValueError self.upsample = nn.Upsample(scale_factor=2) self.conv_out = Conv3x3(itm_ch, out_ch) self._trim_resnet() if in_ch != 3: self.resnet.conv1 = nn.Conv2D( in_ch, 64, kernel_size=7, stride=2, padding=3, bias_attr=False) if not pretrained: self.init_weight() def forward(self, x): y = self.resnet.conv1(x) y = self.resnet.bn1(y) y = self.resnet.relu(y) y = self.resnet.maxpool(y) y = self.resnet.layer1(y) y = self.resnet.layer2(y) y = self.resnet.layer3(y) y = self.resnet.layer4(y) y = self.upsample(y) return self.conv_out(y) def _trim_resnet(self): if self.n_stages > 5: raise ValueError if self.n_stages < 5: self.resnet.layer4 = Identity() if self.n_stages <= 3: self.resnet.layer3 = Identity() self.resnet.avgpool = Identity() self.resnet.fc = Identity()
2.2 Bitemporal Image Transformer,双时相图的Transformer
BIT这部分可以大体分为Semantic Tokenizer,Encoder和Decoder三个模块Semantic Tokenizer:作者将上一阶段输出的两幅特征图,用同一个Tokenizer的网络来对两幅图像之间变化的信息进行提取,孪生型的孪生型的tokens更加高效。这一步将backbone输出的特征图转换为了具有高维语义信息的token,就可以送入transformer进行处理了
代码如下
def _get_semantic_tokens(self, x): b, c = x.shape[:2] att_map = self.conv_att(x) att_map = att_map.reshape((b, self.token_len, 1, -1)) att_map = F.softmax(att_map, axis=-1) x = x.reshape((b, 1, c, -1)) tokens = (x * att_map).sum(-1) return tokens
Transformer-encoder:从孪生型的tokenizer网络得到两个token后,作者将两个token concact起来送到transformer的encoder进行特征提取。本文的encoder包括了多头注意力和MLP模块:多头注意力中与原始的transformer不同,而是参考VIT,在多头注意力之前进行norm,这里的norm是Layernorm。该模块并行执行多个独立的注意头,并将输出串联起来,然后进行投影以得到最终值,可以共同关注来自不同位置的不同表示子空间的信息MLP模块使用的是两个线性变换和dropout,第一个线性变换和dropout中间有一个有一个GELU激活
代码如下
class Residual(nn.Layer): def __init__(self, fn): super(Residual, self).__init__() self.fn = fn def forward(self, x, **kwargs): return self.fn(x, **kwargs) + x class PreNorm(nn.Layer): def __init__(self, dim, fn): super(PreNorm, self).__init__() self.norm = nn.LayerNorm(dim) self.fn = fn def forward(self, x, **kwargs): return self.fn(self.norm(x), **kwargs) class FeedForward(nn.Sequential): def __init__(self, dim, hidden_dim, dropout_rate=0.): super(FeedForward, self).__init__( nn.Linear(dim, hidden_dim), nn.GELU(), nn.Dropout(dropout_rate), nn.Linear(hidden_dim, dim), nn.Dropout(dropout_rate))class CrossAttention(nn.Layer): def __init__(self, dim, n_heads=8, head_dim=64, dropout_rate=0., apply_softmax=True): super(CrossAttention, self).__init__() inner_dim = head_dim * n_heads self.n_heads = n_heads self.scale = dim**-0.5 self.apply_softmax = apply_softmax self.fc_q = nn.Linear(dim, inner_dim, bias_attr=False) self.fc_k = nn.Linear(dim, inner_dim, bias_attr=False) self.fc_v = nn.Linear(dim, inner_dim, bias_attr=False) self.fc_out = nn.Sequential( nn.Linear(inner_dim, dim), nn.Dropout(dropout_rate)) def forward(self, x, ref): b, n = x.numpy().shape[:2] h = self.n_heads q = self.fc_q(x) k = self.fc_k(ref) v = self.fc_v(ref) q = q.reshape((b, n, h, -1)).transpose((0, 2, 1, 3)) k = k.reshape((b, paddle.shape(ref)[1], h, -1)).transpose((0, 2, 1, 3)) v = v.reshape((b, paddle.shape(ref)[1], h, -1)).transpose((0, 2, 1, 3)) mult = paddle.matmul(q, k, transpose_y=True) * self.scale if self.apply_softmax: mult = F.softmax(mult, axis=-1) out = paddle.matmul(mult, v) out = out.transpose((0, 2, 1, 3)).flatten(2) return self.fc_out(out)class SelfAttention(CrossAttention): def forward(self, x): return super(SelfAttention, self).forward(x, x)class TransformerEncoder(nn.Layer): def __init__(self, dim, depth, n_heads, head_dim, mlp_dim, dropout_rate): super(TransformerEncoder, self).__init__() self.layers = nn.LayerList([]) for _ in range(depth): self.layers.append( nn.LayerList([ Residual( PreNorm(dim, SelfAttention(dim, n_heads, head_dim, dropout_rate))), Residual( PreNorm(dim, FeedForward(dim, mlp_dim, dropout_rate))) ])) def forward(self, x): for att, ff in self.layers: x = att(x) x = ff(x) return x
Transformer-decoder:在BIT中,Decoder采用的孪生网络的形式,因为最终是要通过Decoder生成两张新特征图并且这两张新特征图应该具备区分其两者之间异同点的特点。所以需要将encoder的输出分为两部分,分别送入到decoder中.decoder将输入的高级语义,映射回像素空间,得到像素级的特征表示。可以把特征图中的像素当作queries,token当做keys,提供信息
代码如下
class Residual2(nn.Layer): def __init__(self, fn): super(Residual2, self).__init__() self.fn = fn def forward(self, x1, x2, **kwargs): return self.fn(x1, x2, **kwargs) + x1 class PreNorm2(nn.Layer): def __init__(self, dim, fn): super(PreNorm2, self).__init__() self.norm = nn.LayerNorm(dim) self.fn = fn def forward(self, x1, x2, **kwargs): return self.fn(self.norm(x1), self.norm(x2), **kwargs) class TransformerDecoder(nn.Layer): def __init__(self, dim, depth, n_heads, head_dim, mlp_dim, dropout_rate, apply_softmax=True): super(TransformerDecoder, self).__init__() self.layers = nn.LayerList([]) for _ in range(depth): self.layers.append( nn.LayerList([ Residual2( PreNorm2(dim, CrossAttention(dim, n_heads, head_dim, dropout_rate, apply_softmax))), Residual( PreNorm(dim, FeedForward(dim, mlp_dim, dropout_rate))) ])) def forward(self, x, m): for att, ff in self.layers: x = att(x, m) x = ff(x) return x
2.3 Prediction Head,推测头
类似目标检测领域里的输出头,先把根据Decoder翻译出来的特征图信息进行一个做差得到变化的信息,然后再通过上采样和一系列卷积调整通道,生成变化图
代码如下
y1 = self.decode(x1, token1)y2 = self.decode(x2, token2)# Feature differencingy = paddle.abs(y1 - y2)y = self.upsample(y)# Classifier forwardpred = self.conv_out(y)
三、复现精度
在LEVIR-CD的测试集的测试效果如下表,达到验收指标,F1-Score=89.31%
BITSGD2008LEVIR-CD89.32%
四、环境与数据准备
克隆仓库In [1]
!git clone https://github.com/kongdebug/BIT-CD-Paddle.git
正克隆到 'BIT-CD-Paddle'...remote: Enumerating objects: 1004, done.remote: Counting objects: 100% (1004/1004), done.remote: Compressing objects: 100% (779/779), done.remote: Total 1004 (delta 207), reused 976 (delta 194), pack-reused 0接收对象中: 100% (1004/1004), 28.86 MiB | 6.93 MiB/s, 完成.处理 delta 中: 100% (207/207), 完成.检查连接... 完成。
解压数据,并进行处理In [1]
# 解压数据!unzip -qo data/data136610/LEVIR-CD.zip -d data/data136610/
In [ ]
# 安装相应依赖%cd BIT-CD-Paddle/!pip install -r requirements.txt
In [ ]
# 对数据进行切片处理,注意输入文件夹和输出文件夹不能相同,这一步切割耗时较长!python data/spliter-cd.py --image_folder ../data/data136610/LEVIR-CD --block_size 256 --save_folder ../LEVIR-CD
In [9]
# 生成模型训练需要的.txt文件!python data/process_levir_data.py --data_dir ../LEVIR-CD
数据集划分已完成。
五、快速体验
模型训练In [ ]
!python tutorials/train/change_detection/bit_train.py --data_dir=../LEVIR-CD --out_dir=./output/BIT/
模型验证最优模型权重已放入work/BIT/best_model文件夹下可将–weight_path参数替换为自己训练出的模型权重路径In [12]
!python tutorials/eval/change_detection/bit_eval.py --data_dir=../LEVIR-CD/ --weight_path=../work/BIT/best_model/model.pdparams
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/tensor/creation.py:130: DeprecationWarning: `np.object` is a deprecated alias for the builtin `object`. To silence this warning, use `object` by itself. Doing this will not modify any behavior and is safe. Deprecated in NumPy 1.20; for more details and guidance: https://numpy.org/devdocs/release/1.20.0-notes.html#deprecations if data.dtype == np.object:[04-26 00:13:58 MainThread @logger.py:242] Argv: tutorials/eval/change_detection/bit_eval.py --data_dir=../LEVIR-CD/ --weight_path=../work/BIT/best_model/model.pdparams[04-26 00:13:58 MainThread @utils.py:79] WRN paddlepaddle version: 2.2.2. The dynamic graph version of PARL is under development, not fully tested and supported2022-04-26 00:13:59 [INFO]2048 samples in file ../LEVIR-CD/test.txtW0426 00:13:59.148581 9007 device_context.cc:447] Please NOTE: device: 0, GPU Compute Capability: 7.0, Driver API Version: 10.1, Runtime API Version: 10.1W0426 00:13:59.154322 9007 device_context.cc:465] device: 0, cuDNN Version: 7.6.2022-04-26 00:14:02 [INFO]Loading pretrained model from ../work/BIT/best_model/model.pdparams2022-04-26 00:14:02 [INFO]There are 203/203 variables loaded into BIT.2022-04-26 00:14:02 [INFO]Start to evaluate(total_samples=2048, total_steps=2048)...OrderedDict([('miou', 0.8980501731845956), ('category_iou', array([0.98892947, 0.80717087])), ('oacc', 0.9894197657704353), ('category_acc', array([0.99300849, 0.91857525])), ('kappa', 0.887736151189675), ('category_F1-score', array([0.99443393, 0.89329779]))])
模型预测使用最优模型权重对模型进行预测参数介绍:weight 训练好的权重A,B, 是T1影像路径,T2影像路径pre 预测图片存储的位置In [15]
!python tutorials/predict/change_detection/bit_predict.py --weight_path ../work/BIT/best_model/model.pdparams --A ../LEVIR-CD/test/A/test_2_0_0.png --B ../LEVIR-CD/test/B/test_2_0_0.png --pre ../work/pre.png
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/tensor/creation.py:130: DeprecationWarning: `np.object` is a deprecated alias for the builtin `object`. To silence this warning, use `object` by itself. Doing this will not modify any behavior and is safe. Deprecated in NumPy 1.20; for more details and guidance: https://numpy.org/devdocs/release/1.20.0-notes.html#deprecations if data.dtype == np.object:[04-26 00:40:19 MainThread @logger.py:242] Argv: tutorials/predict/change_detection/bit_predict.py --weight_path ../work/BIT/best_model/model.pdparams --A ../LEVIR-CD/test/A/test_2_0_0.png --B ../LEVIR-CD/test/B/test_2_0_0.png --pre ../work/pre.png[04-26 00:40:19 MainThread @utils.py:79] WRN paddlepaddle version: 2.2.2. The dynamic graph version of PARL is under development, not fully tested and supportedW0426 00:40:19.621413 10885 device_context.cc:447] Please NOTE: device: 0, GPU Compute Capability: 7.0, Driver API Version: 10.1, Runtime API Version: 10.1W0426 00:40:19.627353 10885 device_context.cc:465] device: 0, cuDNN Version: 7.6.2022-04-26 00:40:23 [INFO]Loading pretrained model from ../work/BIT/best_model/model.pdparams2022-04-26 00:40:23 [INFO]There are 203/203 variables loaded into BIT.okfinish!
In [19]
# 展示预测的结果,最后一张为真值import matplotlib.pyplot as pltfrom PIL import ImageT1 = Image.open(r"../LEVIR-CD/test/A/test_2_0_0.png")T2 = Image.open(r"../LEVIR-CD/test/B/test_2_0_0.png")GT = Image.open(r"../LEVIR-CD/test/label/test_2_0_0.png")pred = Image.open(r"../work/pre.png")plt.figure(figsize=(16, 8))plt.subplot(1,4,1), plt.title('T1')plt.imshow(T1), plt.axis('off')plt.subplot(1,4,2), plt.title('T2') plt.imshow(T2), plt.axis('off')plt.subplot(1,4,3), plt.title('pred') plt.imshow(pred), plt.axis('off')plt.subplot(1,4,4), plt.title('GT') plt.imshow(GT), plt.axis('off')plt.show()
BIT模型导出 注意:导出BIT模型时,请保证指定–fixed_input_shape,并且数值不包含负数,因为BIT用到空间注意力,需要从tensor中获取b,c,h,w的属性,若为负数则报错In [20]
!python deploy/export/export_model.py --model_dir=../work/BIT/best_model/ --save_dir=./inference_model/ --fixed_input_shape=[1,3,256,256]
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/tensor/creation.py:130: DeprecationWarning: `np.object` is a deprecated alias for the builtin `object`. To silence this warning, use `object` by itself. Doing this will not modify any behavior and is safe. Deprecated in NumPy 1.20; for more details and guidance: https://numpy.org/devdocs/release/1.20.0-notes.html#deprecations if data.dtype == np.object:[04-26 01:00:27 MainThread @logger.py:242] Argv: deploy/export/export_model.py --model_dir=../work/BIT/best_model/ --save_dir=./inference_model/ --fixed_input_shape=[1,3,256,256][04-26 01:00:27 MainThread @utils.py:79] WRN paddlepaddle version: 2.2.2. The dynamic graph version of PARL is under development, not fully tested and supportedW0426 01:00:28.290376 12365 device_context.cc:447] Please NOTE: device: 0, GPU Compute Capability: 7.0, Driver API Version: 10.1, Runtime API Version: 10.1W0426 01:00:28.296492 12365 device_context.cc:465] device: 0, cuDNN Version: 7.6.2022-04-26 01:00:32 [INFO]Model[BIT] loaded.2022-04-26 01:00:36 [INFO]The model for the inference deployment is saved in ./inference_model/.
六、TIPC基础链条测试
该部分依赖auto_log,需要进行安装,安装方式如下:
auto_log的详细介绍参考https://github.com/LDOUBLEV/AutoLog。
In [ ]
!git clone https://github.com/LDOUBLEV/AutoLog!pip3 install -r requirements.txt!python3 setup.py bdist_wheel!pip3 install ./dist/auto_log-1.0.0-py3-none-any.whl
准备数据In [ ]
!bash ./test_tipc/prepare.sh test_tipc/configs/BIT/train_infer_python.txt 'lite_train_lite_infer'
测试In [ ]
!bash test_tipc/test_train_inference_python.sh test_tipc/configs/BIT/train_infer_python.txt 'lite_train_lite_infer'
以上就是【第六期论文复现赛-变化检测】BIT的详细内容,更多请关注创想鸟其它相关文章!
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 chuangxiangniao@163.com 举报,一经查实,本站将立刻删除。
发布者:程序猿,转转请注明出处:https://www.chuangxiangniao.com/p/315902.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 






















