
本项目基于PaddleDetection套件的人脸检测模块和VGG情绪七分类模型,实现从图片中检测人脸并分类表情。先介绍项目背景、意义等,再说明fer2013数据集处理过程,构建VGG网络训练,经100轮迭代精度达63%左右,还结合PaddleDetection的人脸识别模型,最后尝试ResNet34优化,指出不足与改进方向。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

基于PaddleDetection的情绪识别
一、项目背景
1.1 引言
PaddleDetection:PaddleDetection为基于飞桨PaddlePaddle的端到端目标检测套件,内置30+模型算法及250+预训练模型,覆盖目标检测、实例分割、跟踪、关键点检测等方向,其中包括服务器端和移动端高精度、轻量级产业级SOTA模型、冠军方案和学术前沿算法,并提供目标检测、实例分割、多目标跟踪、关键点检测等多种能力。本次项目就是基于PaddleDetection先进行了人脸识别,并利用Paddle组建VGG网络以实现了表情识别。
人脸表情识别(facialexpression recognition, FER)是计算机视觉领域中图像分类的一个最重要的应用场景。相较于目标检测、实例分割、行为识别、轨迹跟踪等难度较大的计算机视觉任务,图像分类只需要让计算机『看出』图片里的物体类别,相对更为基础一些,但也极为重要,广泛应用于现实生活中的各个场景。

1.2 项目简介
本项目基于PaddleDetection套件中的人脸检测模块和VGG情绪七分类模型联合构建而成,可以直接从给定图片中检测出人脸目标并进行表情分类,判定图中的人正处于何种情绪,并可视化识别结果。 其中的人脸检测模块直接使用了PaddleDetection套件来实现。VGG情绪七分类模型则是基于Paddle进行了自组网,并基于fer2013人脸表情数据集训练而得来,模型精度在63%左右。
1.3 项目意义
本项目的意义:我们小组分工合作,各司其职,共同完成此项目,有利于培养团队合作精神,整个项目完成后,对通过机器识别给定的静态图像或动态视频序列中分离出特定的表情状态,从而确定被识别对象的心理情绪,实现计算机对人脸表情的理解与识别,可从根本上改变人与计算机的关系有了更深刻的了解。使计算机可以更好地为人类服务,从而达到更好的人机交互。而且表情识别技术是人们探索和理解智能的有效途径。
1.4 项目案例
人脸表情识别(facialexpression recognition, FER)是计算机视觉领域中图像分类的一个最重要的应用场景,相较于目标检测、实例分割、行为识别、轨迹跟踪等难度较大的计算机视觉任务,图像分类只需要让计算机『看出』图片里的物体类别,更为基础但极为重要。我们今天要讲解的案例——人脸表情识别近年来引起了学术界和工业界的研究热潮,因为表情是我们在日常交流中非常重要的表达方式之一,在无法获取说话人语气的情况下,表情就成为了理解语言含义不可或缺的一部分。FER是一门交叉学科,涉及到计算机视觉、人机交互、生理学、心理学、模式识别等研究领域。在社会中的很多领域,例如机器人制造,自动化,人机交互、安全、医疗、驾驶和通信等,表情识别同样具有很高的实用价值。

1.5 整体流程
先使用PaddleDetection套件中的目标检测模型识别出人脸区域,再将此人脸区域送进基于VGG的表情判别网络以完成情感分类,最终实现FER任务。今天我们小组带大家利用飞桨框架搭建VGG网络,基于fer2013表情数据库实现其中七种表情的识别,让大家亲自感受图像分类与人脸表情识别的魅力。
表情识别的整体流程如下:
二、数据集介绍
2.1 数据集介绍
fer2013人脸表情数据集由35886张人脸表情图片组成,其中包括了训练图(Training),公共验证图(PublicTest)和私有验证图(PrivateTest)。
本案例使用全部的7钟情绪

2.2 解压数据集
将数据集的压缩包解压到emotic文件夹中:
In [1]
%cd /home/aistudio!unzip -oq data/data150109/archive.zip -d ./emotic
/home/aistudio
将数据集整理成以文件名表示类别的形式
In [2]
import osimport cv2import tqdmdef make_new_dir(root_dir, tag, save_dir): img_root = os.path.join(root_dir, tag) img_dir_list = os.listdir(img_root) if not os.path.isdir(save_dir): os.mkdir(save_dir) print(img_dir_list) for img_dir in tqdm.tqdm(img_dir_list): img_folder = os.path.join(img_root, img_dir) img_list = [f for f in os.listdir(img_folder) if f.endswith('.jpg')] name_first = img_dir[:2].upper() for index, filename in enumerate(img_list): img = cv2.imread(os.path.join(img_folder, filename), -1) save_name = name_first+"{0:0>5}.jpg".format(index) cv2.imwrite(os.path.join(save_dir, save_name), img)
In [3]
root_dir = r"emotic"save_dir = r"train"make_new_dir(root_dir, "train", save_dir) # 制作训练集
In [4]
root_dir = r"emotic"save_dir = r"test"make_new_dir(root_dir, "test", save_dir) # 制作测试集
In [5]
# 随机移动10%数量的图像到val文件夹中import shutilimport osimport randomdef move2newDir(inputFolder, saveFolder): filenames = [f for f in os.listdir(inputFolder) if f.endswith('.jpg')] random.shuffle(filenames) num_val = int(0.1*len(filenames)) if not os.path.isdir(saveFolder): os.mkdir(saveFolder) for index, filename in enumerate(filenames): src = os.path.join(inputFolder,filename) dst = os.path.join(saveFolder,filename) shutil.move(src, dst) if index == num_val: break
In [6]
inputFolder = r"train"saveFolder = r"val"move2newDir(inputFolder, saveFolder)
2.3 查看数据集
查看数据集图片:train/val/test文件夹里包含7种表情类型图片 以NE,HA,SU作为名称前缀的图片分别代表neutral,happy,surprised三种表情
In [7]
import osimport numpy as npimport matplotlib.pyplot as plt%matplotlib inlinefrom PIL import Image#选取 test文件夹 作为图片路径DATADIR = 'test' # 文件名以N开头的是普通表情的图片,以H开头的是高兴图片,以S开头的是惊讶的图片#file0-3选取了三个文件夹里的三个表情file0 = 'NE00127.jpg'file1 = 'HA00453.jpg'file2 = 'SU00224.jpg'# 读取图片img0 = Image.open(os.path.join(DATADIR, file0))img0 = np.array(img0)img1 = Image.open(os.path.join(DATADIR, file1))img1 = np.array(img1)img2 = Image.open(os.path.join(DATADIR, file2))img2 = np.array(img2)# 画出读取的图片plt.figure(figsize=(16, 8))f = plt.subplot(131)f.set_title('0', fontsize=20)plt.imshow(img0)f = plt.subplot(132)f.set_title('1', fontsize=20)plt.imshow(img1)f = plt.subplot(133)f.set_title('2', fontsize=20)plt.imshow(img2)#plt展示出三个表情plt.show()
三、数据处理
在训练神经网络之前,我们通常需要编写适合当前任务的数据处理程序,并进行数据校验,以保证传入神经网络的数据格式是正确的
3.1 定义数据读取器
使用OpenCV从磁盘读入图片,将每张图缩放到224×224大小,并且将像素值调整到[−1,1][-1, 1][−1,1]之间,代码如下所示:
In [8]
import cv2import randomimport numpy as npimport os# 对读入的图像数据进行预处理def transform_img(img): # 将图片尺寸缩放道 224x224 img = cv2.resize(img, (224, 224)) # 读入的图像数据格式是[H, W, C] # 使用转置操作将其变成[C, H, W] img = np.transpose(img, (2,0,1)) img = img.astype('float32') # 将数据范围调整到[-1.0, 1.0]之间 img = img / 255. img = img * 2.0 - 1.0 return img# 定义训练集数据读取器def data_loader(datadir, batch_size=20, mode = 'train'): # 将datadir目录下的文件列出来,每条文件都要读入 filenames = os.listdir(datadir) def reader(): if mode == 'train': # 训练时随机打乱数据顺序 random.shuffle(filenames) batch_imgs = [] batch_labels = [] for name in filenames: filepath = os.path.join(datadir, name) img = cv2.imread(filepath) img = transform_img(img) #依次读取每张图片的名称首字母用于标记标签 # 7类表情 'sad', 'disgust', 'happy', 'fear', 'surprise', 'neutral', 'angry' # SA开头表示sad表情用0标签 # DI开头表示disgust表情用1标签 # HA开头表示happy表情用2标签,以此类推 if name[:2] == 'SA': label = 0 elif name[:2] == 'DI': label = 1 elif name[:2] == 'HA': label = 2 elif name[:2] == 'FE': label = 3 elif name[:2] == 'SU': label = 4 elif name[:2] == 'NE': label = 5 elif name[:2] == 'AN': label = 6 else: raise('Not excepted file name') # 每读取一个样本的数据,就将其放入数据列表中 batch_imgs.append(img) batch_labels.append(label) if len(batch_imgs) == batch_size: # 当数据列表的长度等于batch_size的时候, # 把这些数据当作一个mini-batch,并作为数据生成器的一个输出 imgs_array = np.array(batch_imgs).astype('float32') labels_array = np.array(batch_labels).reshape(-1, 1) yield imgs_array, labels_array batch_imgs = [] batch_labels = [] if len(batch_imgs) > 0: # 剩余样本数目不足一个batch_size的数据,一起打包成一个mini-batch imgs_array = np.array(batch_imgs).astype('float32') labels_array = np.array(batch_labels).reshape(-1, 1) yield imgs_array, labels_array return reader# 定义验证集数据读取器def valid_data_loader(datadir, batch_size=20, mode='valid'): filenames = os.listdir(datadir) def reader(): batch_imgs = [] batch_labels = [] # 根据图片文件名加载图片,并对图像数据作预处理 for name in filenames: filepath = os.path.join(datadir, name) # 每读取一个样本的数据,就将其放入数据列表中 img = cv2.imread(filepath) img = transform_img(img) #根据名称判断标签 if name[:2] == 'SA': label = 0 elif name[:2] == 'DI': label = 1 elif name[:2] == 'HA': label = 2 elif name[:2] == 'FE': label = 3 elif name[:2] == 'SU': label = 4 elif name[:2] == 'NE': label = 5 elif name[:2] == 'AN': label = 6 else: raise('Not excepted file name') # 每读取一个样本的数据,就将其放入数据列表中 batch_imgs.append(img) batch_labels.append(label) if len(batch_imgs) == batch_size: # 当数据列表的长度等于batch_size的时候, # 把这些数据当作一个mini-batch,并作为数据生成器的一个输出 imgs_array = np.array(batch_imgs).astype('float32') labels_array = np.array(batch_labels).reshape(-1, 1) yield imgs_array, labels_array batch_imgs = [] batch_labels = [] if len(batch_imgs) > 0: # 剩余样本数目不足一个batch_size的数据,一起打包成一个mini-batch imgs_array = np.array(batch_imgs).astype('float32') labels_array = np.array(batch_labels).reshape(-1, 1) yield imgs_array, labels_array return reader
3.2 校验数据
将train文件夹中的数据传入到数据读取器,再输出处理后的数据格式
In [9]
# 查看数据形状DATADIR = 'train'train_loader = data_loader(DATADIR,batch_size=20, mode='train')data_reader = train_loader()data = next(data_reader) #返回迭代器的下一个项目给data# 输出表示: 图像数据(batchsize,通道数,224*224)标签(batchsize,标签维度)print("train mode's shape:")print("data[0].shape = %s, data[1].shape = %s" %(data[0].shape, data[1].shape))eval_loader = data_loader(DATADIR,batch_size=20, mode='eval')data_reader = eval_loader()data = next(data_reader)# 输出表示: 图像数据(batchsize,通道数,224*224)标签(batchsize,标签维度)print("eval mode's shape:")print("data[0].shape = %s, data[1].shape = %s" %(data[0].shape, data[1].shape))
四、VGG模型介绍
4.1 原理解析
本案例中我们使用VGG网络进行表情识别,首先我们来了解一下VGG模型。VGG是在AlexNet的基础上通过增加网络深度达到提高模型性能的目的,在2014年ImageNet竞赛中获得分类第二(第一是GoogLeNet),定位任务第一。
原理介绍: 其实VGG网络模型的设计思想很清晰,主要为了探究网络深度对模型精确度的影响,所以VGG的设计模仿了AlexNet,只是增加了卷基层conv的数量和减小卷积核尺寸,全连接层FC保留了AlexNet的结构,相比于AlexNet,VGG网络有如下优点:
1.卷积层的数量更多,提高模型的准确度
2.采用了较小的卷积核,减少模型的参数,VGG结构中只采用了3×3和1×1的卷积核
4.2 网络结构

4.3 VGG16模型

五、模型实现
VGG网络的定义代码如下:
In [10]
# -*- coding:utf-8 -*-# VGG模型代码import numpy as npimport paddle# from paddle.nn import Conv2D, MaxPool2D, BatchNorm, Linearfrom paddle.nn import Conv2D, MaxPool2D, BatchNorm2D, Linear# 定义vgg网络class VGG(paddle.nn.Layer): def __init__(self, num_class): super(VGG, self).__init__() in_channels = [3, 64, 128, 256, 512, 512] # 定义第一个卷积块,包含两个卷积 输入通道数是图片通道数即3 输出通道数即out_channels=in_channels[1]=64 self.conv1_1 = Conv2D(in_channels=in_channels[0], out_channels=in_channels[1], kernel_size=3, padding=1, stride=1) self.conv1_2 = Conv2D(in_channels=in_channels[1], out_channels=in_channels[1], kernel_size=3, padding=1, stride=1) # 定义第二个卷积块,包含两个卷积 输入通道数是上一个卷积块的输出通道数即64 输出通道数即out_channels=in_channels[2]=128 self.conv2_1 = Conv2D(in_channels=in_channels[1], out_channels=in_channels[2], kernel_size=3, padding=1, stride=1) self.conv2_2 = Conv2D(in_channels=in_channels[2], out_channels=in_channels[2], kernel_size=3, padding=1, stride=1) # 定义第三个卷积块,包含三个卷积 输入通道数是上一个卷积块的输出通道数即128 输出通道数即out_channels=in_channels[3]=256 self.conv3_1 = Conv2D(in_channels=in_channels[2], out_channels=in_channels[3], kernel_size=3, padding=1, stride=1) self.conv3_2 = Conv2D(in_channels=in_channels[3], out_channels=in_channels[3], kernel_size=3, padding=1, stride=1) self.conv3_3 = Conv2D(in_channels=in_channels[3], out_channels=in_channels[3], kernel_size=3, padding=1, stride=1) # 定义第四个卷积块,包含三个卷积 输入通道数是上一个卷积块的输出通道数即256 输出通道数即out_channels=in_channels[4]=512 self.conv4_1 = Conv2D(in_channels=in_channels[3], out_channels=in_channels[4], kernel_size=3, padding=1, stride=1) self.conv4_2 = Conv2D(in_channels=in_channels[4], out_channels=in_channels[4], kernel_size=3, padding=1, stride=1) self.conv4_3 = Conv2D(in_channels=in_channels[4], out_channels=in_channels[4], kernel_size=3, padding=1, stride=1) # 定义第五个卷积块,包含三个卷积 输入通道数是上一个卷积块的输出通道数即512 输出通道数即out_channels=in_channels[5]=512 self.conv5_1 = Conv2D(in_channels=in_channels[4], out_channels=in_channels[5], kernel_size=3, padding=1, stride=1) self.conv5_2 = Conv2D(in_channels=in_channels[5], out_channels=in_channels[5], kernel_size=3, padding=1, stride=1) self.conv5_3 = Conv2D(in_channels=in_channels[5], out_channels=in_channels[5], kernel_size=3, padding=1, stride=1) # VGG网络的设计严格使用3*3的卷积层和池化层来提取特征,并在网络的最后面使用三层全连接层,将最后一层全连接层的输出作为分类的预测。 # 使用Sequential 将全连接层和relu组成一个线性结构(fc + relu) # 当输入为224x224时,经过五个卷积块和池化层后,特征维度变为[512x7x7] self.fc1 = paddle.nn.Sequential(paddle.nn.Linear(512 * 7 * 7, 4096), paddle.nn.ReLU()) self.drop1_ratio = 0.5 self.dropout1 = paddle.nn.Dropout(self.drop1_ratio, mode='upscale_in_train') # 使用Sequential 将全连接层和relu组成一个线性结构(fc + relu) self.fc2 = paddle.nn.Sequential(paddle.nn.Linear(4096, 4096), paddle.nn.ReLU()) self.drop2_ratio = 0.5 self.dropout2 = paddle.nn.Dropout(self.drop2_ratio, mode='upscale_in_train') #全连接层的输出 # paddle.nn.Linear(in_features, out_features, weight_attr=None, bias_attr=None, name=None) # out_features 由输出标签的个数决定 本案例识别的7种表情,对应了3种标签。 因此 out_features = 3 self.fc3 = paddle.nn.Linear(4096, 1000) self.fc4 = paddle.nn.Linear(1000,num_class) self.relu = paddle.nn.ReLU() self.pool = MaxPool2D(stride=2, kernel_size=2) def forward(self, x): #激活函数用relu x = self.relu(self.conv1_1(x)) x = self.relu(self.conv1_2(x)) x = self.pool(x) x = self.relu(self.conv2_1(x)) x = self.relu(self.conv2_2(x)) x = self.pool(x) x = self.relu(self.conv3_1(x)) x = self.relu(self.conv3_2(x)) x = self.relu(self.conv3_3(x)) x = self.pool(x) x = self.relu(self.conv4_1(x)) x = self.relu(self.conv4_2(x)) x = self.relu(self.conv4_3(x)) x = self.pool(x) x = self.relu(self.conv5_1(x)) x = self.relu(self.conv5_2(x)) x = self.relu(self.conv5_3(x)) x = self.pool(x) x = paddle.flatten(x, 1, -1) #添加dropout抑制过拟合 x = self.dropout1(self.relu(self.fc1(x))) x = self.dropout2(self.relu(self.fc2(x))) x = self.fc3(x) x = self.fc4(x) return x
六、模型训练
6.1 训练设置
设置CrossEntropy损失函数 用于计算输入input和标签label间的交叉熵损失
In [11]
loss_fct = paddle.nn.CrossEntropyLoss() #结合了LogSoftmax和NLLLoss的OP计算,可用于训练一个n类分类器。
设置迭代轮数
In [12]
EPOCH_NUM = 100 #训练进行100次迭代
优化器选择paddle api中的momentum优化器
paddle.optimizer.Momentum(),具体参数如下:
learning_rate (float|_LRScheduler, 可选) – 学习率,用于参数更新的计算。可以是一个浮点型值或者一个_LRScheduler类,默认值为0.001
momentum (float, 可选) – 动量因子。
parameters (list, 可选) – 指定优化器需要优化的参数。在动态图模式下必须提供该参数;在静态图模式下默认值为None,这时所有的参数都将被优化。
use_nesterov (bool, 可选) – 赋能牛顿动量,默认值False。
 硅基智能
硅基智能
基于Web3.0的元宇宙,去中心化的互联网,高质量、沉浸式元宇宙直播平台,用数字化重新定义直播
 62 查看详情
62 查看详情 
weight_decay (float|Tensor, 可选) – 权重衰减系数,是一个float类型或者shape为[1] ,数据类型为float32的Tensor类型。默认值为0.01
grad_clip (GradientClipBase, 可选) – 梯度裁剪的策略,支持三种裁剪策略: paddle.nn.ClipGradByGlobalNorm 、 paddle.nn.ClipGradByNorm 、 paddle.nn.ClipGradByValue 。 默认值为None,此时将不进行梯度裁剪。
name (str, 可选)- 该参数供开发人员打印调试信息时使用,具体用法请参见 Name ,默认值为None
In [13]
model = VGG(num_class=7)opt = paddle.optimizer.Momentum(learning_rate=0.001, momentum=0.9, parameters=model.parameters()) #learning_rate为学习率,用于参数更新的计算。momentum为动量因子。
6.2 定义训练过程
下面利用定义好的数据处理函数,完成神经网络训练过程的定义。
In [14]
import paddleimport osimport randomimport numpy as npDATADIR = 'train'DATADIR2 = 'val'DATADIR3 = 'test'def train_pm(model, optimizer, loss_fct, EPOCH_NUM, model_name='vgg'): #optimizer表示优化器 loss_fict 为损失函数 EPOCH_NUM为迭代次数,model_name为调用的模型名称 # 开启0号GPU训练 use_gpu = True paddle.set_device('gpu:0') if use_gpu else paddle.set_device('cpu') print('start training ... ') model.train() # 定义数据读取器,训练数据读取器和验证数据读取器 train_loader = data_loader(DATADIR, batch_size=20, mode='train') for epoch in range(EPOCH_NUM): for batch_id, data in enumerate(train_loader()): x_data, y_data = data #将图片和标签都转化为tensor型 img = paddle.to_tensor(x_data) label = paddle.to_tensor(y_data) # 运行模型前向计算,得到预测值 logits = model(img) #计算输入input和标签label间的交叉熵损失 avg_loss = loss_fct(logits, label) if batch_id % 200 == 0: print("epoch: {}, batch_id: {}, loss is: {:.4f}".format(epoch, batch_id, float(avg_loss.numpy()))) # 反向传播,更新权重,清除梯度 avg_loss.backward() optimizer.step() optimizer.clear_grad() #保存模型 paddle.save(model.state_dict(), model_name + '.pdparams') paddle.save(optimizer.state_dict(), model_name + '.pdopt')
6.3 创建VGG模型并开启训练
In [ ]
# 启动训练过程train_pm(model, opt,loss_fct,EPOCH_NUM, model_name='vgg')
七、模型评估与测试
现在,我们使用验证集来评估训练过程保存的最终模型。首先加载模型参数,之后调用评估函数去遍历验证集进行预测并输出平均准确率
7.1 定义评估函数
In [15]
import paddle@paddle.no_grad()#定义评估函数def evaluation(model, loss_fct): print('start evaluation .......') model.eval() eval_loader = data_loader(DATADIR3, batch_size=20, mode='eval') acc_set = [] avg_loss_set = [] for batch_id, data in enumerate(eval_loader()): x_data, y_data = data #将图片和标签都转化为tensor型 img = paddle.to_tensor(x_data) label = paddle.to_tensor(y_data) # 计算预测和精度 logits = model(img) acc = paddle.metric.accuracy(logits, label) avg_loss = loss_fct(logits, label) acc_set.append(float(acc.numpy())) avg_loss_set.append(float(avg_loss.numpy())) # 求平均精度 acc_val_mean = np.array(acc_set).mean() avg_loss_val_mean = np.array(avg_loss_set).mean() model.train() print('loss={:.4f}, acc={:.4f}'.format(avg_loss_val_mean, acc_val_mean))
7.2 评估VGG模型
注: 这里如果不想训练可以跳到目录8.1运行解压代码,提前解压放在data/data150481/PaddleDetection.zip里面我们训练好的VGG情绪识别模型
In [16]
#开启0号GPU预估use_gpu = Truepaddle.set_device('gpu:0') if use_gpu else paddle.set_device('cpu')#加载模型参数params_file_path = './work/PaddleDetection/models/vgg.pdparams'model_state_dict = paddle.load(params_file_path)model.load_dict(model_state_dict)#调用验证evaluation(model, loss_fct)
由上个代码块的输出我们可以看到vgg网络模型的评估结果
损失率loss=2.5956, 准确率acc=0.6304(实际结果可能存在微小波动)
可见经过100个epoch的训练,vgg网络达到了约63.04%的分类精度
7.3 测试模型
完成网络模型的评估后,现在我们可以开始调用模型来进行表情识别
In [17]
import cv2import matplotlib.pyplot as plt%matplotlib inlinefrom PIL import Imagedef load_image(img): # 将图片尺寸缩放道 224x224 img = cv2.resize(img, (224, 224)) # 读入的图像数据格式是[H, W, C] # 使用转置操作将其变成[C, H, W] img = np.transpose(img, (2, 0, 1)) img = img.astype('float32') # 将数据范围调整到[-1.0, 1.0]之间 img = img / 255. img = img * 2.0 - 1.0 return imgmodel = VGG(num_class=7)params_file_path = './work/PaddleDetection/models/vgg.pdparams'#选取test文件夹里一张表情图片 H开头表示happyimg_path = 'test/SA00022.jpg'img = cv2.imread(img_path)plt.imshow(img)plt.axis('off')plt.show()param_dict = paddle.load(params_file_path)model.load_dict(param_dict)# 灌入数据model.eval()tensor_img = load_image(img)tensor_img = np.expand_dims(tensor_img, 0)results = model(paddle.to_tensor(tensor_img))# 取概率最大的标签作为预测输出lab = np.argsort(results.numpy())print("这次预测图片名称是:%s" %(img_path[5:]))# 7类表情 'sad', 'disgust', 'happy', 'fear', 'surprise', 'neutral', 'angry'if img_path[5:7] == 'NE': true_lab = 'NEUTRAL' elif img_path[5:7] == 'HA': true_lab = 'HAPPY'elif img_path[5:7] == 'SU': true_lab = 'SURPRISE'elif img_path[5:7] == 'SA': true_lab = 'SAD'elif img_path[5:7] == 'FE': true_lab = 'FEAR'elif img_path[5:7] == 'AN': true_lab = 'ANGRY'elif img_path[5:7] == 'DI': true_lab = 'DISGUST'else: raise('Not excepted file name')print("这次图片属于%s表情" %(true_lab))tap = lab[0][-1]print("这次预测结果是:")if tap == 0: print('SAD')elif tap == 1: print('DISGUST')elif tap == 2: print('HAPPY')elif tap == 3: print('FEAR')elif tap == 4: print('SURPRISE')elif tap == 5: print('NEUTRAL')elif tap == 6: print('ANGRY')else: raise('Not excepted file name')
八、基于PaddleDetection 人脸情绪检测
PaddleDetection目标检测库中,除了包含10余种主流目标检测算法外,还包含了人脸检测任务的blazeface和faceboxes模型,以及这两个模型的轻量级模型探索,相关配置文件位于configs/face_detection目录下,套件中的face_detection模块提供了高效、高速的人脸检测解决方案,包括最先进的模型和经典模型。 在这里我们采用blazeface_fpn_ssh_1000e的模型 此模块可直接调用以进行人脸识别,具体步骤为:
1.获取并安装PaddleDetection套件
2.从官方链接点击此处获取中下载已训练好的模型,并获取WIDER-FACE数据集用于评估
3.完成模型评估并进行人脸识别
8.1 解压/home/aistudio/data/data150481/PaddleDetection.zip 到work 目录下
In [1]
%cd work!unzip -oq /home/aistudio/data/data150481/PaddleDetection.zip
/home/aistudio/work
8.2 安装环境通过如下方式安装PaddleDetection依赖,并设置环境变量
In [19]
%cd PaddleDetection!pip install -r requirements.txt%env PYTHONPATH=.:$PYTHONPATH%env CUDA_VISIBLE_DEVICES=0!python setup.py install
8.3 人脸识别模型及VGG表情分类模型均已训练完成,此时只需要把两者结合起来,把通过PaddleDetection人脸识别模型识别到的图片中的人脸,输入到VGG模型中进行表情识别,而后再将识别的表情结果返回给PaddleDetection标注的人脸框上,完成人脸表情识别
In [ ]
! python tools/infer.py -c configs/face_detection/blazeface_fpn_ssh_1000e.yml --infer_img=input/simle.jpg -o weights=models/blazeface_fpn_ssh_1000e.pdparams
8.4 可视化展示
In [ ]
%matplotlib inlineimport matplotlib.pyplot as plt import cv2infer_img = cv2.imread("output/simle.jpg")plt.figure(figsize=(15, 10))plt.imshow(cv2.cvtColor(infer_img, cv2.COLOR_BGR2RGB))plt.show()
情绪识别效果展示:
九、模型的优化
为提升模型训练的效率和获得更高的预测精确度,下面介绍几种常见的优化方法
模型选择:
不同的神经网络具有不同的结构,深度和参数。针对于本次分类任务,VGG网络不一定是最合适的神经网络,为达到更高的精度,我们可以尝试更换其它神经网络来进行训练。
ResNet网络结构:
ResNet:
Kaiming He等人在2015年提出了ResNet,通过引入残差模块加深网络层数,在ImagNet数据集上的错误率降低到3.6%,超越了人眼识别水平。ResNet的设计思想深刻地影响了后来的深度神经网络的设计。
下图表示出了ResNet的结构:
In [ ]
model = paddle.vision.models.resnet34(pretrained=True, num_classes = 7) #pretrained:表示是否加载在imagenet数据集上的预训练权重 num_classes由数据集的标签数决定lr = paddle.optimizer.lr.ReduceOnPlateau(learning_rate=0.0001, factor=0.5, patience=2, verbose=True)opt = paddle.optimizer.Momentum(learning_rate=lr, momentum=0.9, parameters=model.parameters(), weight_decay=0.001) #选择momentum优化器# 启动训练过程train_pm(model, opt,loss_fct,EPOCH_NUM=30, model_name='resnet34')
ResNet34的评估效果
In [ ]
use_gpu = Truepaddle.set_device('gpu:0') if use_gpu else paddle.set_device('cpu')model = paddle.vision.models.resnet34(pretrained=True,num_classes = 7) params_file_path = './resnet34.pdparams'model_state_dict = paddle.load(params_file_path)model.load_dict(model_state_dict)#调用验证evaluation(model, loss_fct)
可以看出ResNet34训练出来的精度为62.79%,虽然没有VGG精度高但是后期可以调整参数可以训练出更好的模型
十、总结与致谢
10.1 总结
在深度学习神经网络模型中,通常使用标准的随机梯度下降算法更新参数,学习率代表参数更新幅度的大小,即步长。当学习率最优时,模型的有效容量最大,最终能达到的效果最好。学习率和深度学习任务类型有关,合适的学习率往往需要大量的实验和调参经验。探索学习率最优值时需要注意如下两点:
学习率不是越小越好。学习率越小,损失函数的变化速度越慢,意味着我们需要花费更长的时间进行收敛,如 图2 左图所示。学习率不是越大越好。只根据总样本集中的一个批次计算梯度,抽样误差会导致计算出的梯度不是全局最优的方向,且存在波动。在接近最优解时,过大的学习率会导致参数在最优解附近震荡,损失难以收敛,如下图所示。
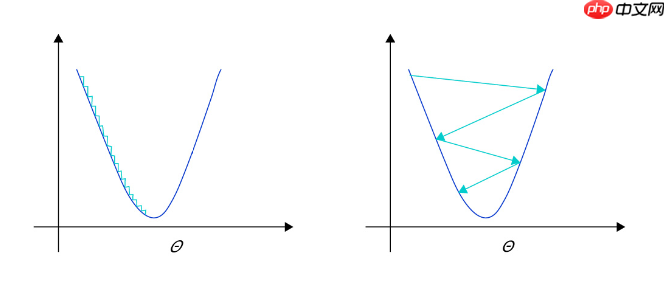
上图为不同学习率(步长过大/过小)的示意图
10.2 不足与改进
Fer2013数据集中的人脸数据都较小,因而在此基础上训练出来的模型对一些人脸区域较大的图片的识别效果不是很好,可能会直接无法检测出人脸。精度有待提高,目前训练出的最好精度为63.04%可以尝试使用Resnet50模型进行训练
以上就是基于PaddleDetection的情绪识别的详细内容,更多请关注创想鸟其它相关文章!
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 chuangxiangniao@163.com 举报,一经查实,本站将立刻删除。
发布者:程序猿,转转请注明出处:https://www.chuangxiangniao.com/p/316465.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 






















