
本文介绍了使用PaddleNLP进行淘宝商品评论情感分析的过程。先处理数据,将原数据集转换为指定格式,再用load_dataset读取。选用ERNIE预训练模型,通过tokenizer处理文本,用DataLoader加载数据。设置优化策略后训练模型,最后用训练好的模型进行预测,实现对评论情感(正向、中立、负向)的分类。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

一、PaddleNLP之淘宝商品评论情感分析
在我国电子商务飞快发展的背景下,基本上所有的电子商务网站都支持消费者对产品的做工、快递、价格个等进行打分和发表评论。在网络平台上发布大量的留言和评论,这已经成为互联网的一种流行形式,而这种形势必然给互联网带来海量的信息。
对于卖家来说,可以从评论信息中获取客户的实际需求,以改善产品品质,提高自身的竞争力。另一方面,对于一些未知体验产品,客户可以通过网络来获取产品信息,特别是对一些未知的体验产品,客户为了降低自身的风险更加倾向于得到其他客户的意见和看法,这些评论对潜在的买家而言无疑是一笔财富,并以此作为决策的重要依据。
对于客户来说,可以借鉴别人的购买历史以及评论信息,更好的辅助自己制定购买决策。
因此,通过利用数据挖掘技术针对客户的大量评论进行分析,可以挖掘出这些信息的特征,而得到的这些信息有利于生产商改进自身产品和改善相关的服务,提高商家的核心竞争力。
数据标签分别为 {0: ‘negative’, 1: ‘neutral’, 2: ‘positive’}
In [1]
!pip install --upgrade paddlenlp
二、数据处理
1.数据查看
可见每条数据包含一句评论和对应的标签,0或1。0代表负向评论,1代表中立评论,2代表正向评论。
In [2]
# 解压缩# !unzip data/data94812/中文淘宝评论数据集.zip
In [17]
!head -n9 train.txt
质量 很棒 ! 又 厚实 , 就是 做工 不好 , 就是 有点 味道 得 跑跑做工0很好 , 很漂亮 , 质量 问题 就 不知道 了 , 得用 用 才 知道 , 这个 快递 太 垃圾 了快递0价格 上面 反正 折扣 之后 就是 市场 销售价格 , 搞 活动 也 就 随便说说 , 挺好吃 的价格0
2.数据集格式转换
In [4]
def read(data_path): data=['label'+'t'+'text_an'] with open(data_path, 'r', encoding='utf-8-sig') as f: lines=f.readlines() # 三行为一条记录 for i in range(int(len(lines)/3)): # 读取第一行为内容 word = lines[i*3].strip('n') # 读取第三行为标签 label = lines[i*3+2].strip('n') data.append(label+'t'+word+'n') i=i+1 return data with open('formated_train.txt','w') as f: f.writelines(read('train.txt'))with open('formated_test.txt','w') as f: f.writelines(read('test.txt'))
In [5]
!head formated_train.txt
labeltext_a0质量 很棒 ! 又 厚实 , 就是 做工 不好 , 就是 有点 味道 得 跑跑0很好 , 很漂亮 , 质量 问题 就 不知道 了 , 得用 用 才 知道 , 这个 快递 太 垃圾 了0价格 上面 反正 折扣 之后 就是 市场 销售价格 , 搞 活动 也 就 随便说说 , 挺好吃 的0漂亮 好看 质量 好 就是 快递 不 给力 , 派个件 要 派 两天0宝贝 很 满意 , 发小 刚刚 好 , 质量 也 不错 , 值得 购买 , 就是 快递 太慢 , 昨天 才 到0行李箱 就 不错 啊 ! 看上去 是 挺 结实 的 等 用 了 才 知道 是不是 真的 好 ! 拉链 也 很 顺滑 ! 快递 太差 , 太慢0质量 很好 , 发货 很快 , 果断 给 好评 ! 快递 小哥 有些 烦 , 让 他 等 我 五分钟 , 结果 五分钟 内 打 了 三次 电话 !0颜色 很小 清新 , 和 图片 一样 的 , 送 的 贴纸 很 可爱 。 轮子 在 瓷砖 上 走 挺 小声 的 , 要是 细节 处理 好 一点 就 完美 了 。 性价比 高 。 快递 没打 满分 一 是因为 不 给 送货 , 二是 我 说 等验 完货 在 签 , 她们 就 给 我 脸色 看 。0虽然 安装 师傅 不 给力 , 但是 东西 真的 很 给力 ! 很 喜欢 好评 !
In [6]
!head formated_test.txt
labeltext_a0非常 漂亮 的 拉杆箱 , 很 轻 , 跟 店家 描述 的 一致 , 快递 速度 不行 啊0款式 设计 的 很 好看 呀 , 客服 态度 很好 , 呃 , 质量 感觉 不太好 奥 , 就是 会 起球 , 而且 快递 好慢 啊0超值 啊 哈哈哈 , 就是 颜色 随机 我以 为什么 颜色 都 有 , 结果 全是 一个 颜色 的 , 不过 东西 好 就 可以 , 物超所值 。0卖家 很好 , 热情周到 , 包装 严实 , 遇到 快递 问题 都 极力 解决 。 我要 投诉 快递 , 太差 了 。0比 想象 的 要 好得多 , 音效 特别 好 , 还 带 环绕 音 , 总之 很 喜欢 , 就是 这个 价格 不是 很 实惠0买大 了 一点 , 不过 也 能 穿 , 孩子 很 喜欢 , 三件套 的 , 春秋 都 可以 穿 , 质量 还可以 , 蓝色 的 绒 颜色 感觉 有点 陈旧 , 还有 就是 有点 小贵 。 快递 公司 有点 小 差错 , 不过 老板 很快 就 解决 了 。0质量 一般 , 边板 是 多层板 , 快递 太慢 了 , 2 月 8 日 发货 , 21 日才 到 。0挺好 的 , 店家 很 用心 , 包装 的 非常 好 , 只是 快递 方面 太慢 了 , 希望 这方面 还是 改进 下 !0好吃 好吃 , 就是 分量 太少 了 , 有点 贵咯
3.重写read方法读取自定义数据集
通过查看课件,3行为一条记录,分别为评价内容、评价分类、评价正负标签,根据文件结构,自定义数据集
In [7]
from paddlenlp.datasets import load_datasetdef read(data_path): with open(data_path, 'r', encoding='utf-8') as f: # 跳过列名 next(f) for line in f: label, word= line.strip('n').split('t') yield {'text': word, 'label': label}# data_path为read()方法的参数train_ds = load_dataset(read, data_path='formated_train.txt',lazy=False)test_ds = load_dataset(read, data_path='formated_test.txt',lazy=False)dev_ds = load_dataset(read, data_path='formated_test.txt',lazy=False)
In [8]
print(len(train_ds))print(train_ds.label_list)for idx in range(10): print(train_ds[idx])
13339None{'text': '质量 很棒 ! 又 厚实 , 就是 做工 不好 , 就是 有点 味道 得 跑跑', 'label': '0'}{'text': '很好 , 很漂亮 , 质量 问题 就 不知道 了 , 得用 用 才 知道 , 这个 快递 太 垃圾 了', 'label': '0'}{'text': '价格 上面 反正 折扣 之后 就是 市场 销售价格 , 搞 活动 也 就 随便说说 , 挺好吃 的', 'label': '0'}{'text': '漂亮 好看 质量 好 就是 快递 不 给力 , 派个件 要 派 两天', 'label': '0'}{'text': '宝贝 很 满意 , 发小 刚刚 好 , 质量 也 不错 , 值得 购买 , 就是 快递 太慢 , 昨天 才 到', 'label': '0'}{'text': '行李箱 就 不错 啊 ! 看上去 是 挺 结实 的 等 用 了 才 知道 是不是 真的 好 ! 拉链 也 很 顺滑 ! 快递 太差 , 太慢', 'label': '0'}{'text': '质量 很好 , 发货 很快 , 果断 给 好评 ! 快递 小哥 有些 烦 , 让 他 等 我 五分钟 , 结果 五分钟 内 打 了 三次 电话 !', 'label': '0'}{'text': '颜色 很小 清新 , 和 图片 一样 的 , 送 的 贴纸 很 可爱 。 轮子 在 瓷砖 上 走 挺 小声 的 , 要是 细节 处理 好 一点 就 完美 了 。 性价比 高 。 快递 没打 满分 一 是因为 不 给 送货 , 二是 我 说 等验 完货 在 签 , 她们 就 给 我 脸色 看 。', 'label': '0'}{'text': '虽然 安装 师傅 不 给力 , 但是 东西 真的 很 给力 ! 很 喜欢 好评 !', 'label': '0'}{'text': '外观 还可以 , 送 了 很多 贴画 , 蛮 细心 的 。 快递 送 在 超市 门口 打个 电话 就 走 了 , 结果 被 别人 拿走 了 , 好歹 又 送 回来 了 & hellip ; & hellip ; 真是 糟心 !', 'label': '0'}
三、使用预训练模型
1.选取预训练模型
In [9]
import paddlenlp as ppnlp# 设置想要使用模型的名称MODEL_NAME = "ernie-1.0"ernie_model = ppnlp.transformers.ErnieModel.from_pretrained(MODEL_NAME)model = ppnlp.transformers.ErnieForSequenceClassification.from_pretrained(MODEL_NAME, num_classes=3)
[2021-06-15 23:40:55,574] [ INFO] - Downloading https://paddlenlp.bj.bcebos.com/models/transformers/ernie/ernie_v1_chn_base.pdparams and saved to /home/aistudio/.paddlenlp/models/ernie-1.0[2021-06-15 23:40:55,577] [ INFO] - Downloading ernie_v1_chn_base.pdparams from https://paddlenlp.bj.bcebos.com/models/transformers/ernie/ernie_v1_chn_base.pdparams100%|██████████| 392507/392507 [00:13<00:00, 29747.03it/s][2021-06-15 23:41:15,870] [ INFO] - Weights from pretrained model not used in ErnieModel: ['cls.predictions.layer_norm.weight', 'cls.predictions.decoder_bias', 'cls.predictions.transform.bias', 'cls.predictions.transform.weight', 'cls.predictions.layer_norm.bias'][2021-06-15 23:41:16,263] [ INFO] - Already cached /home/aistudio/.paddlenlp/models/ernie-1.0/ernie_v1_chn_base.pdparams/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/fluid/dygraph/layers.py:1297: UserWarning: Skip loading for classifier.weight. classifier.weight is not found in the provided dict. warnings.warn(("Skip loading for {}. ".format(key) + str(err)))/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/fluid/dygraph/layers.py:1297: UserWarning: Skip loading for classifier.bias. classifier.bias is not found in the provided dict. warnings.warn(("Skip loading for {}. ".format(key) + str(err)))
2.调用ppnlp.transformers.ErnieTokenizer进行数据处理
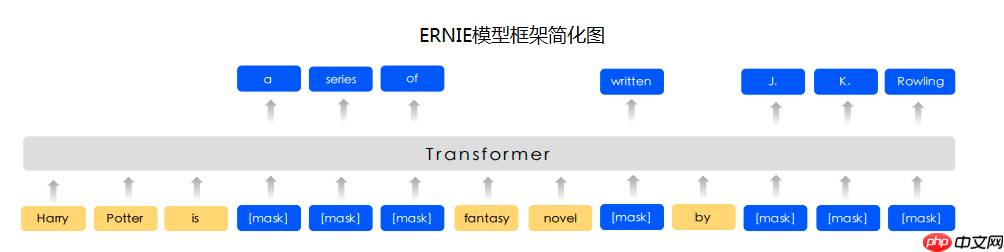
预训练模型ERNIE对中文数据的处理是以字为单位。PaddleNLP对于各种预训练模型已经内置了相应的tokenizer。指定想要使用的模型名字即可加载对应的tokenizer。
 灵感PPT
灵感PPT
AI灵感PPT – 免费一键PPT生成工具
 32 查看详情
32 查看详情 
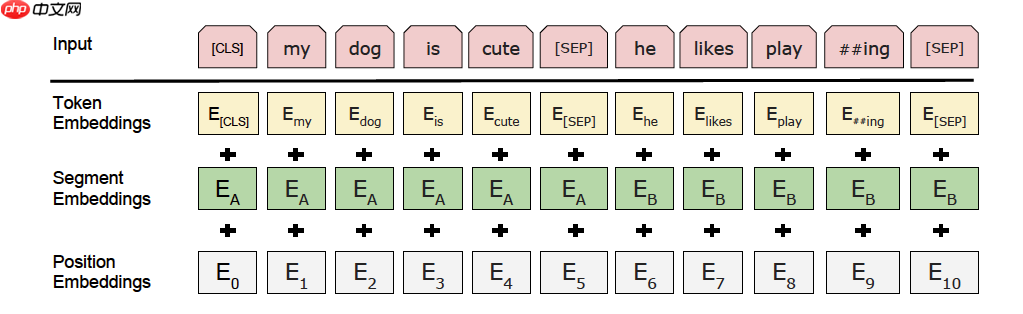
tokenizer作用为将原始输入文本转化成模型model可以接受的输入数据形式。
In [10]
tokenizer = ppnlp.transformers.ErnieTokenizer.from_pretrained(MODEL_NAME)
[2021-06-15 23:41:18,286] [ INFO] - Downloading vocab.txt from https://paddlenlp.bj.bcebos.com/models/transformers/ernie/vocab.txt100%|██████████| 90/90 [00:00<00:00, 3163.87it/s]
从以上代码可以看出,ERNIE模型输出有2个tensor。
sequence_output是对应每个输入token的语义特征表示,shape为(1, num_tokens, hidden_size)。其一般用于序列标注、问答等任务。pooled_output是对应整个句子的语义特征表示,shape为(1, hidden_size)。其一般用于文本分类、信息检索等任务。
NOTE:
如需使用ernie-tiny预训练模型,则对应的tokenizer应该使用paddlenlp.transformers.ErnieTinyTokenizer.from_pretrained(‘ernie-tiny’)以上代码示例展示了使用Transformer类预训练模型所需的数据处理步骤。为了更方便地使用,PaddleNLP同时提供了更加高阶API,一键即可返回模型所需数据格式。
3.数据读取
使用paddle.io.DataLoader接口多线程异步加载数据。
In [11]
from functools import partialfrom paddlenlp.data import Stack, Tuple, Padfrom utils import convert_example, create_dataloader# 模型运行批处理大小batch_size = 200max_seq_length = 128trans_func = partial( convert_example, tokenizer=tokenizer, max_seq_length=max_seq_length)batchify_fn = lambda samples, fn=Tuple( Pad(axis=0, pad_val=tokenizer.pad_token_id), # input Pad(axis=0, pad_val=tokenizer.pad_token_type_id), # segment Stack(dtype="int64") # label): [data for data in fn(samples)]train_data_loader = create_dataloader( train_ds, mode='train', batch_size=batch_size, batchify_fn=batchify_fn, trans_fn=trans_func)dev_data_loader = create_dataloader( dev_ds, mode='dev', batch_size=batch_size, batchify_fn=batchify_fn, trans_fn=trans_func)
4.设置Fine-Tune优化策略,接入评价指标
In [12]
from paddlenlp.transformers import LinearDecayWithWarmupimport paddle# 训练过程中的最大学习率learning_rate = 5e-5 # 训练轮次epochs = 5 #3# 学习率预热比例warmup_proportion = 0.1# 权重衰减系数,类似模型正则项策略,避免模型过拟合weight_decay = 0.01num_training_steps = len(train_data_loader) * epochslr_scheduler = LinearDecayWithWarmup(learning_rate, num_training_steps, warmup_proportion)optimizer = paddle.optimizer.AdamW( learning_rate=lr_scheduler, parameters=model.parameters(), weight_decay=weight_decay, apply_decay_param_fun=lambda x: x in [ p.name for n, p in model.named_parameters() if not any(nd in n for nd in ["bias", "norm"]) ])criterion = paddle.nn.loss.CrossEntropyLoss()metric = paddle.metric.Accuracy()
四、模型训练与评估
模型训练的过程通常有以下步骤:
从dataloader中取出一个batch data将batch data喂给model,做前向计算将前向计算结果传给损失函数,计算loss。将前向计算结果传给评价方法,计算评价指标。loss反向回传,更新梯度。重复以上步骤。
每训练一个epoch时,程序将会评估一次,评估当前模型训练的效果。
In [13]
# checkpoint文件夹用于保存训练模型!mkdir /home/aistudio/checkpoint
mkdir: cannot create directory ‘/home/aistudio/checkpoint’: File exists
In [14]
import paddle.nn.functional as Ffrom utils import evaluateglobal_step = 0for epoch in range(1, epochs + 1): for step, batch in enumerate(train_data_loader, start=1): input_ids, segment_ids, labels = batch logits = model(input_ids, segment_ids) loss = criterion(logits, labels) probs = F.softmax(logits, axis=1) correct = metric.compute(probs, labels) metric.update(correct) acc = metric.accumulate() global_step += 1 if global_step % 10 == 0 : print("global step %d, epoch: %d, batch: %d, loss: %.5f, acc: %.5f" % (global_step, epoch, step, loss, acc)) loss.backward() optimizer.step() lr_scheduler.step() optimizer.clear_grad() evaluate(model, criterion, metric, dev_data_loader)
global step 270, epoch: 5, batch: 2, loss: 0.43869, acc: 0.80500global step 280, epoch: 5, batch: 12, loss: 0.41893, acc: 0.80792global step 290, epoch: 5, batch: 22, loss: 0.44744, acc: 0.80523global step 300, epoch: 5, batch: 32, loss: 0.38977, acc: 0.80797global step 310, epoch: 5, batch: 42, loss: 0.39923, acc: 0.80774global step 320, epoch: 5, batch: 52, loss: 0.36724, acc: 0.81029global step 330, epoch: 5, batch: 62, loss: 0.40811, acc: 0.81008eval loss: 0.51191, accu: 0.74444
五、模型预测
训练保存好的训练,即可用于预测。如以下示例代码自定义预测数据,调用predict()函数即可一键预测。
In [16]
from utils import predictdata = [ {"text":'这个宾馆比较陈旧了,特价的房间也很一般。总体来说一般'}, {"text":'怀着十分激动的心情放映,可是看着看着发现,在放映完毕后,出现一集米老鼠的动画片'}, {"text":'作为老的四星酒店,房间依然很整洁,相当不错。机场接机服务很好,可以在车上办理入住手续,节省时间。'},]label_map = {0: 'negative', 1: 'neutral', 2: 'positive'}results = predict( model, data, tokenizer, label_map, batch_size=batch_size)for idx, text in enumerate(data): print('Data: {} t Lable: {}'.format(text, results[idx]))
Data: {'text': '这个宾馆比较陈旧了,特价的房间也很一般。总体来说一般'} Lable: neutralData: {'text': '怀着十分激动的心情放映,可是看着看着发现,在放映完毕后,出现一集米老鼠的动画片'} Lable: negativeData: {'text': '作为老的四星酒店,房间依然很整洁,相当不错。机场接机服务很好,可以在车上办理入住手续,节省时间。'} Lable: positive
以上就是PaddleNLP之淘宝商品评论情感分析的详细内容,更多请关注创想鸟其它相关文章!
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 chuangxiangniao@163.com 举报,一经查实,本站将立刻删除。
发布者:程序猿,转转请注明出处:https://www.chuangxiangniao.com/p/316544.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 






















