
本项目基于PaddlePaddle2.0.0rc,用2010-2014年北京空气污染数据,通过LSTM和DNN对比预测未来一天某时刻PM2.5。经数据预处理、标准化和滑窗处理,构建模型训练。结果显示,LSTM在时序预测上效果更优,验证集MAE损失更低,未出现过拟合,更适合此类任务。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

项目介绍:基于PaddlePaddle2.0.0rc使用LSTM进行北京空气污染序列预测
使用长短期记忆网络LSTM来预测未来的北京的空气污染情况,数据集使用的是北京2010.1.1至2014.12.31之间的空气污染数据,数据采用结构化表格的形式,包括year,month,day,hour等时间信息,以及对应的pm2.5,DEWP,TEMP,PRES,cbwd,Iws,Is,Ir等指标,任务是通过给定的数据来预测未来一天某个时刻空气指标PM2.5的数值,本项目是采用七天的滑窗数据预测后一天第24小时的pm2.5数值。首先是搭建了DNN网络作为对比,再尝试了LSTM网络。对比两者的预测结果maeloss曲线,得出结论:对应本项目这样的时序预测任务,使用LSTM具有更好的效果
创建时间:2020年10月12日15:34:47
注意事项
请使用CPU版本的环境运行本项目,paddlepaddle2.0.0rc在使用LSTM时在GPU环境下存在无法运行的bug,在最新develop版本已修复。
安装PaddlePaddle2.0 develop
In [ ]
# !python -m pip install paddlepaddle-gpu==2.0.0rc0.post101 -f https://paddlepaddle.org.cn/whl/stable.html
导入必要的包
In [ ]
import paddleimport paddle.fluid as fluidimport paddle.fluid.layers as layersimport pandas as pdimport numpy as npimport matplotlib.pyplot as plt%matplotlib inline
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/pandas/core/tools/datetimes.py:3: DeprecationWarning: Using or importing the ABCs from 'collections' instead of from 'collections.abc' is deprecated, and in 3.8 it will stop working from collections import MutableMapping/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/matplotlib/rcsetup.py:20: DeprecationWarning: Using or importing the ABCs from 'collections' instead of from 'collections.abc' is deprecated, and in 3.8 it will stop working from collections import Iterable, Mapping/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/matplotlib/colors.py:53: DeprecationWarning: Using or importing the ABCs from 'collections' instead of from 'collections.abc' is deprecated, and in 3.8 it will stop working from collections import Sized
特征工程
读取数据集并查看
In [ ]
data = pd.read_csv('data/data55547/PRSA_data_2010.1.1-2014.12.31.csv')#查看数据大小,类型及是否存在缺失值data.info()
RangeIndex: 43824 entries, 0 to 43823Data columns (total 13 columns):No 43824 non-null int64year 43824 non-null int64month 43824 non-null int64day 43824 non-null int64hour 43824 non-null int64pm2.5 41757 non-null float64DEWP 43824 non-null int64TEMP 43824 non-null float64PRES 43824 non-null float64cbwd 43824 non-null objectIws 43824 non-null float64Is 43824 non-null int64Ir 43824 non-null int64dtypes: float64(4), int64(8), object(1)memory usage: 4.3+ MB
从上面的信息中可知pm2.5项目存在缺失值(non-null数量为41757少于其他项目43824 ),查看缺失数据
In [ ]
data[data['pm2.5'].isna()]
No year month day hour pm2.5 DEWP TEMP PRES cbwd Iws � 1 2010 1 1 0 NaN -21 -11.0 1021.0 NW 1.79 1 2 2010 1 1 1 NaN -21 -12.0 1020.0 NW 4.92 2 3 2010 1 1 2 NaN -21 -11.0 1019.0 NW 6.71 3 4 2010 1 1 3 NaN -21 -14.0 1019.0 NW 9.84 4 5 2010 1 1 4 NaN -20 -12.0 1018.0 NW 12.97 5 6 2010 1 1 5 NaN -19 -10.0 1017.0 NW 16.10 6 7 2010 1 1 6 NaN -19 -9.0 1017.0 NW 19.23 7 8 2010 1 1 7 NaN -19 -9.0 1017.0 NW 21.02 8 9 2010 1 1 8 NaN -19 -9.0 1017.0 NW 24.15 9 10 2010 1 1 9 NaN -20 -8.0 1017.0 NW 27.28 10 11 2010 1 1 10 NaN -19 -7.0 1017.0 NW 31.30 11 12 2010 1 1 11 NaN -18 -5.0 1017.0 NW 34.43 12 13 2010 1 1 12 NaN -19 -5.0 1015.0 NW 37.56 13 14 2010 1 1 13 NaN -18 -3.0 1015.0 NW 40.69 14 15 2010 1 1 14 NaN -18 -2.0 1014.0 NW 43.82 15 16 2010 1 1 15 NaN -18 -1.0 1014.0 cv 0.89 16 17 2010 1 1 16 NaN -19 -2.0 1015.0 NW 1.79 17 18 2010 1 1 17 NaN -18 -3.0 1015.0 NW 2.68 18 19 2010 1 1 18 NaN -18 -5.0 1016.0 NE 1.79 19 20 2010 1 1 19 NaN -17 -4.0 1017.0 NW 1.79 20 21 2010 1 1 20 NaN -17 -5.0 1017.0 cv 0.89 21 22 2010 1 1 21 NaN -17 -5.0 1018.0 NW 1.79 22 23 2010 1 1 22 NaN -17 -5.0 1018.0 NW 2.68 23 24 2010 1 1 23 NaN -17 -5.0 1020.0 cv 0.89 545 546 2010 1 23 17 NaN -18 2.0 1024.0 NW 91.22 546 547 2010 1 23 18 NaN -18 1.0 1024.0 NW 96.14 547 548 2010 1 23 19 NaN -17 0.0 1024.0 NW 100.16 548 549 2010 1 23 20 NaN -18 0.0 1024.0 SE 1.79 549 550 2010 1 23 21 NaN -15 -3.0 1024.0 cv 0.89 550 551 2010 1 23 22 NaN -16 0.0 1023.0 NW 1.79 ... ... ... ... ... ... ... ... ... ... ... ... 42847 42848 2014 11 21 7 NaN -3 0.0 1020.0 NW 11.17 42848 42849 2014 11 21 8 NaN -3 0.0 1020.0 cv 0.89 43190 43191 2014 12 5 14 NaN -22 4.0 1025.0 NW 41.12 43191 43192 2014 12 5 15 NaN -22 3.0 1025.0 NE 1.79 43264 43265 2014 12 8 16 NaN -13 3.0 1033.0 cv 1.79 43266 43267 2014 12 8 18 NaN -11 -2.0 1034.0 SE 0.89 43267 43268 2014 12 8 19 NaN -11 -2.0 1035.0 SE 1.78 43268 43269 2014 12 8 20 NaN -11 -4.0 1036.0 SE 2.67 43269 43270 2014 12 8 21 NaN -11 -5.0 1036.0 SE 3.56 43270 43271 2014 12 8 22 NaN -11 -5.0 1036.0 NE 0.89 43273 43274 2014 12 9 1 NaN -11 -4.0 1037.0 cv 0.89 43274 43275 2014 12 9 2 NaN -10 -5.0 1036.0 SE 0.89 43275 43276 2014 12 9 3 NaN -10 -6.0 1037.0 cv 0.89 43276 43277 2014 12 9 4 NaN -10 -7.0 1036.0 cv 1.78 43277 43278 2014 12 9 5 NaN -11 -6.0 1036.0 cv 2.67 43278 43279 2014 12 9 6 NaN -11 -7.0 1036.0 cv 3.56 43279 43280 2014 12 9 7 NaN -11 -8.0 1036.0 cv 4.45 43280 43281 2014 12 9 8 NaN -9 -6.0 1036.0 SE 0.89 43281 43282 2014 12 9 9 NaN -8 -5.0 1037.0 NE 1.79 43282 43283 2014 12 9 10 NaN -8 -4.0 1037.0 cv 0.89 43283 43284 2014 12 9 11 NaN -8 -3.0 1036.0 NE 1.79 43544 43545 2014 12 20 8 NaN -18 -4.0 1031.0 NW 225.30 43545 43546 2014 12 20 9 NaN -17 -4.0 1031.0 NW 228.43 43546 43547 2014 12 20 10 NaN -18 -2.0 1031.0 NW 233.35 43547 43548 2014 12 20 11 NaN -17 -1.0 1031.0 NW 239.16 43548 43549 2014 12 20 12 NaN -18 0.0 1030.0 NW 244.97 43549 43550 2014 12 20 13 NaN -19 1.0 1029.0 NW 249.89 43550 43551 2014 12 20 14 NaN -20 1.0 1029.0 NW 257.04 43551 43552 2014 12 20 15 NaN -20 2.0 1028.0 NW 262.85 43552 43553 2014 12 20 16 NaN -21 1.0 1028.0 NW 270.00 Is Ir 0 0 0 1 0 0 2 0 0 3 0 0 4 0 0 5 0 0 6 0 0 7 0 0 8 0 0 9 0 0 10 0 0 11 0 0 12 0 0 13 0 0 14 0 0 15 0 0 16 0 0 17 0 0 18 0 0 19 0 0 20 0 0 21 0 0 22 0 0 23 0 0 545 0 0 546 0 0 547 0 0 548 0 0 549 0 0 550 0 0 ... .. .. 42847 0 0 42848 0 0 43190 0 0 43191 0 0 43264 0 0 43266 0 0 43267 0 0 43268 0 0 43269 0 0 43270 0 0 43273 0 0 43274 0 0 43275 0 0 43276 0 0 43277 0 0 43278 0 0 43279 0 0 43280 0 0 43281 0 0 43282 0 0 43283 0 0 43544 0 0 43545 0 0 43546 0 0 43547 0 0 43548 0 0 43549 0 0 43550 0 0 43551 0 0 43552 0 0 [2067 rows x 13 columns]
对缺失数据进行填充
我们采用’ffill’的填充方法,由于0-24之间为nan且0-24前面无数据,无法实现填充,因此去除这段数据
查看数据,获得完整无缺失值的数据
In [ ]
data = data.iloc[24:].copy()#由于0-24之间为nan,我们采用'ffill'的填充方法,由于0-24前面无数据,无法实现填充data.fillna(method='ffill', inplace=True)data.info()
RangeIndex: 43800 entries, 24 to 43823Data columns (total 13 columns):No 43800 non-null int64year 43800 non-null int64month 43800 non-null int64day 43800 non-null int64hour 43800 non-null int64pm2.5 43800 non-null float64DEWP 43800 non-null int64TEMP 43800 non-null float64PRES 43800 non-null float64cbwd 43800 non-null objectIws 43800 non-null float64Is 43800 non-null int64Ir 43800 non-null int64dtypes: float64(4), int64(8), object(1)memory usage: 4.3+ MB
去除索引值,将索引值替换为时间,查看数据
In [ ]
data.drop('No', axis=1, inplace=True)
In [ ]
import datetimedata['time'] = data.apply(lambda x: datetime.datetime(year=x['year'], month=x['month'], day=x['day'], hour=x['hour']), axis=1)
In [ ]
data.set_index('time', inplace=True)data.drop(columns=['year', 'month', 'day', 'hour'], inplace=True)data.head()
pm2.5 DEWP TEMP PRES cbwd Iws Is Irtime 2010-01-02 00:00:00 129.0 -16 -4.0 1020.0 SE 1.79 0 02010-01-02 01:00:00 148.0 -15 -4.0 1020.0 SE 2.68 0 02010-01-02 02:00:00 159.0 -11 -5.0 1021.0 SE 3.57 0 02010-01-02 03:00:00 181.0 -7 -5.0 1022.0 SE 5.36 1 02010-01-02 04:00:00 138.0 -7 -5.0 1022.0 SE 6.25 2 0
为了方便理解数据含义,替换表头
In [ ]
data.columns = ['pm2.5', 'dew', 'temp', 'press', 'cbwd', 'iws', 'snow', 'rain']
查看cbwd项目下的数据,其数据只有四种不同的值,对整体的预测任务影响不大,去除该项目
In [ ]
data.cbwd.unique()
array(['SE', 'cv', 'NW', 'NE'], dtype=object)
In [ ]
del data['cbwd']
In [ ]
data.info()
DatetimeIndex: 43800 entries, 2010-01-02 00:00:00 to 2014-12-31 23:00:00Data columns (total 7 columns):pm2.5 43800 non-null float64dew 43800 non-null int64temp 43800 non-null float64press 43800 non-null float64iws 43800 non-null float64snow 43800 non-null int64rain 43800 non-null int64dtypes: float64(4), int64(3)memory usage: 2.7 MB
绘图查看数据
In [ ]
data['pm2.5'][-1000:].plot()
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/matplotlib/cbook/__init__.py:2349: DeprecationWarning: Using or importing the ABCs from 'collections' instead of from 'collections.abc' is deprecated, and in 3.8 it will stop working if isinstance(obj, collections.Iterator):/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/matplotlib/cbook/__init__.py:2366: DeprecationWarning: Using or importing the ABCs from 'collections' instead of from 'collections.abc' is deprecated, and in 3.8 it will stop working return list(data) if isinstance(data, collections.MappingView) else data
In [ ]
data['temp'][-1000:].plot()
In [ ]
#查看数据data.head(3)
pm2.5 dew temp press iws snow raintime 2010-01-02 00:00:00 129.0 -16 -4.0 1020.0 1.79 0 02010-01-02 01:00:00 148.0 -15 -4.0 1020.0 2.68 0 02010-01-02 02:00:00 159.0 -11 -5.0 1021.0 3.57 0 0
数据标准化,要注意数据标准化应该在训练数据集上,以训练数据的均值和方差作为整个数据的均值和方差
思考:为什么label不需要标准化呢? 从标准化的目的的角度来看,标准化是为了使得不同特征的数据规范到一个统一的范围,有利于神经网络的反向传播(假如不进行规范化,神经网络可能会刻意捕捉不同批次数据的变化,而忽视了预测任务本身),label也可以做标准化,但是预测时还得反向推导出需要的结果。
建立时间滑窗,我们使用前5天(每天24小时)来预测后一天(24小时中某个时间点的数据,这里预测第24时)
In [ ]
sequence_length = 5*24delay = 24# Generated training sequences for use in the model.def create_sequences(values, time_steps=sequence_length+delay): output = [] for i in range(len(values) - time_steps): output.append(values[i : (i + time_steps)]) return np.stack(output)data_ = create_sequences(data.values)print("Training input shape: ", data_.shape)
Training input shape: (43656, 144, 7)
划分数据集,80%为训练集,20%为测试集,查看数据集形状,使用前120个小时的数据预测接下来24个小时中某个时刻的pm2.5的值
对数据集进行标准化
In [ ]
split_boundary = int(data_.shape[0] * 0.8)train = data_[: split_boundary]test = data_[split_boundary:]mean = train.mean(axis=0)std = train.std(axis=0)train = (train - mean)/stdtest = (test - mean)/stdtrain.shape,test.shape
((34924, 144, 7), (8732, 144, 7))
In [ ]
#数据生成器def switch_reader(is_val: bool = False): def reader(): # 判断是否是验证集 if is_val: # 抽取数据使用迭代器返回 for te in test: yield te[:sequence_length],te[-1:][:,0] else: # 抽取数据使用迭代器返回 for tr in train: yield tr[:sequence_length],tr[-1:][:,0]#只取第0列pm2.5的值为label return reader # 注意!此处不需要带括号# 划分batchbatch_size = 128train_reader = fluid.io.batch(reader=switch_reader(), batch_size=batch_size)val_reader = fluid.io.batch(reader=switch_reader(is_val=True), batch_size=batch_size)for data in train_reader(): # print(data[0].shape,data[1].shape) train_x=np.array([x[0] for x in data],np.float32) train_y = np.array([x[1] for x in data]).astype('int64') print(train_x.shape,train_y.shape)
建立模型DNN
拿到一个任务,首先从简单的模型试起,这里首先选择最简单的两层神经网络,网络可以自己随意添加层数,可以自己尝试调整各种超参数
In [ ]
#定义DNN网络class MyModel(fluid.dygraph.Layer): ''' DNN网络 ''' def __init__(self): super(MyModel,self).__init__() self.fc1=fluid.dygraph.Linear(5*24*7,32,act='relu') self.fc2=fluid.dygraph.Linear(32,1) def forward(self,input): # forward 定义执行实际运行时网络的执行逻辑 '''前向计算''' # print('input',input.shape) input =fluid.layers.reshape(input,shape=[-1,5*24*7]) out=self.fc1(input) out=self.fc2(out) # print(out.shape) return out
定义绘图函数
In [ ]
Batch=0Batchs=[]all_train_loss=[]def draw_train_loss(Batchs, train_loss,eval_loss): title="training-eval loss" plt.title(title, fontsize=24) plt.xlabel("batch", fontsize=14) plt.ylabel("loss", fontsize=14) plt.plot(Batchs, train_loss, color='red', label='training loss') plt.plot(Batchs, eval_loss, color='g', label='eval loss') plt.legend() plt.grid() plt.show()
启动训练
In [ ]
# place = fluid.CUDAPlace(0) #非develop版本请勿使用GPU版本place = fluid.CPUPlace() with fluid.dygraph.guard(place): model=MyModel() #模型实例化 model.train() #训练模式 # opt=fluid.optimizer.SGDOptimizer(learning_rate=train_parameters['learning_strategy']['lr'], parameter_list=model.parameters())#优化器选用SGD随机梯度下降,学习率为0.001. opt=fluid.optimizer.AdamOptimizer(learning_rate=0.0001, parameter_list=model.parameters()) epochs_num=100#迭代次数 batch_size = 128*16 train_reader = fluid.io.batch(reader=switch_reader(), batch_size=batch_size) val_reader = fluid.io.batch(reader=switch_reader(is_val=True), batch_size=batch_size) Batch=0 Batchs=[] all_train_loss=[] all_eval_loss=[] for pass_num in range(epochs_num): for batch_id, data in enumerate(train_reader()): data_x=np.array([x[0] for x in data],np.float32) data_y = np.array([x[1] for x in data]).astype('float32') data_x = fluid.dygraph.to_variable(data_x) data_y = fluid.dygraph.to_variable(data_y) # print(data_x.shape, data_y.shape) predict=model(data_x) # print(predict.shape) loss=fluid.layers.mse_loss(predict,data_y) avg_loss=fluid.layers.mean(loss)#获取loss值 avg_loss.backward() opt.minimize(avg_loss) #优化器对象的minimize方法对参数进行更新 model.clear_gradients() #model.clear_gradients()来重置梯度 if batch_id!=0 and batch_id%10==0: Batch = Batch+10 Batchs.append(Batch) all_train_loss.append(avg_loss.numpy()[0]) evalavg_loss=[] for eval_data in val_reader(): eval_data_x = np.array([x[0] for x in eval_data],np.float32) eval_data_y = np.array([x[1] for x in eval_data]).astype('float32') eval_data_x = fluid.dygraph.to_variable(eval_data_x) eval_data_y = fluid.dygraph.to_variable(eval_data_y) eval_predict=model(eval_data_x) eval_loss=fluid.layers.mse_loss(eval_predict,eval_data_y) eval_loss=fluid.layers.mean(eval_loss) evalavg_loss.append(eval_loss.numpy()[0])#获取loss值 all_eval_loss.append(sum(evalavg_loss)/len(evalavg_loss)) print("epoch:{},batch_id:{},train_loss:{},eval_loss:{}".format(pass_num,batch_id,avg_loss.numpy(),sum(evalavg_loss)/len(evalavg_loss))) fluid.save_dygraph(model.state_dict(),'MyModel')#保存模型 fluid.save_dygraph(opt.state_dict(),'MyModel')#保存模型 print("Final loss: {}".format(avg_loss.numpy())) #让我们绘制训练图和验证损失图,以了解训练的进行情况。 draw_train_loss(Batchs,all_train_loss,all_eval_loss)
epoch:0,batch_id:17,train_loss:[2.0205],eval_loss:1.4090836882591247epoch:1,batch_id:17,train_loss:[0.95689076],eval_loss:1.3361332535743713epoch:2,batch_id:17,train_loss:[0.7040673],eval_loss:1.2218480825424194epoch:3,batch_id:17,train_loss:[0.55722934],eval_loss:1.1956807255744935epoch:4,batch_id:17,train_loss:[0.44944313],eval_loss:1.1633899331092834epoch:5,batch_id:17,train_loss:[0.37596697],eval_loss:1.1420036435127259epoch:6,batch_id:17,train_loss:[0.31873935],eval_loss:1.1268895626068116epoch:7,batch_id:17,train_loss:[0.27411735],eval_loss:1.1125162959098815epoch:8,batch_id:17,train_loss:[0.2403403],eval_loss:1.1013256669044496epoch:9,batch_id:17,train_loss:[0.21393616],eval_loss:1.0918826699256896epoch:10,batch_id:17,train_loss:[0.19293499],eval_loss:1.0833844304084779epoch:11,batch_id:17,train_loss:[0.17653875],eval_loss:1.076257163286209epoch:12,batch_id:17,train_loss:[0.16238903],eval_loss:1.0695580899715424epoch:13,batch_id:17,train_loss:[0.15100743],eval_loss:1.0639597535133363epoch:14,batch_id:17,train_loss:[0.14186515],eval_loss:1.0592819035053254epoch:15,batch_id:17,train_loss:[0.13479522],eval_loss:1.055191159248352epoch:16,batch_id:17,train_loss:[0.1290898],eval_loss:1.051255214214325epoch:17,batch_id:17,train_loss:[0.12424426],eval_loss:1.047574871778488epoch:18,batch_id:17,train_loss:[0.11999645],eval_loss:1.0441474676132203epoch:19,batch_id:17,train_loss:[0.11639561],eval_loss:1.0410736680030823epoch:20,batch_id:17,train_loss:[0.11316744],eval_loss:1.038214284181595epoch:21,batch_id:17,train_loss:[0.11018123],eval_loss:1.0353180170059204epoch:22,batch_id:17,train_loss:[0.10779685],eval_loss:1.032786226272583epoch:23,batch_id:17,train_loss:[0.10557291],eval_loss:1.0302606165409087epoch:24,batch_id:17,train_loss:[0.1037445],eval_loss:1.0279349327087401epoch:25,batch_id:17,train_loss:[0.10192361],eval_loss:1.025689673423767epoch:26,batch_id:17,train_loss:[0.10021695],eval_loss:1.023529589176178epoch:27,batch_id:17,train_loss:[0.0984721],eval_loss:1.0216342866420747epoch:28,batch_id:17,train_loss:[0.09707484],eval_loss:1.019782018661499epoch:29,batch_id:17,train_loss:[0.0957087],eval_loss:1.0179351627826692epoch:30,batch_id:17,train_loss:[0.09425645],eval_loss:1.0161666870117188epoch:31,batch_id:17,train_loss:[0.09265903],eval_loss:1.0144980549812317epoch:32,batch_id:17,train_loss:[0.09125529],eval_loss:1.0129337430000305epoch:33,batch_id:17,train_loss:[0.08980759],eval_loss:1.0113472878932952epoch:34,batch_id:17,train_loss:[0.08829899],eval_loss:1.0098000168800354epoch:35,batch_id:17,train_loss:[0.08709818],eval_loss:1.0085288822650909epoch:36,batch_id:17,train_loss:[0.08586626],eval_loss:1.0073016047477723epoch:37,batch_id:17,train_loss:[0.08476242],eval_loss:1.0060584604740144epoch:38,batch_id:17,train_loss:[0.08362537],eval_loss:1.0050600707530974epoch:39,batch_id:17,train_loss:[0.08273471],eval_loss:1.0040717482566834epoch:40,batch_id:17,train_loss:[0.08195919],eval_loss:1.0030322968959808epoch:41,batch_id:17,train_loss:[0.0810699],eval_loss:1.0020980298519135epoch:42,batch_id:17,train_loss:[0.07989511],eval_loss:1.0009490311145783epoch:43,batch_id:17,train_loss:[0.07878471],eval_loss:0.9999779641628266epoch:44,batch_id:17,train_loss:[0.07754707],eval_loss:0.9990507960319519epoch:45,batch_id:17,train_loss:[0.07625636],eval_loss:0.997998195886612epoch:46,batch_id:17,train_loss:[0.07513986],eval_loss:0.9971686065196991epoch:47,batch_id:17,train_loss:[0.07390005],eval_loss:0.9962048828601837epoch:48,batch_id:17,train_loss:[0.07286156],eval_loss:0.9953225016593933epoch:49,batch_id:17,train_loss:[0.07175022],eval_loss:0.9946246147155762epoch:50,batch_id:17,train_loss:[0.07077469],eval_loss:0.993957793712616epoch:51,batch_id:17,train_loss:[0.06977923],eval_loss:0.993251645565033epoch:52,batch_id:17,train_loss:[0.06907593],eval_loss:0.992446219921112epoch:53,batch_id:17,train_loss:[0.06824756],eval_loss:0.991847711801529epoch:54,batch_id:17,train_loss:[0.06763344],eval_loss:0.9912112653255463epoch:55,batch_id:17,train_loss:[0.06695005],eval_loss:0.9905830025672913epoch:56,batch_id:17,train_loss:[0.06627547],eval_loss:0.9900696039199829epoch:57,batch_id:17,train_loss:[0.06573104],eval_loss:0.9896724104881287epoch:58,batch_id:17,train_loss:[0.06506079],eval_loss:0.9892310202121735epoch:59,batch_id:17,train_loss:[0.06436179],eval_loss:0.9887569844722748epoch:60,batch_id:17,train_loss:[0.06374478],eval_loss:0.9883864879608154epoch:61,batch_id:17,train_loss:[0.06303963],eval_loss:0.9881407439708709epoch:62,batch_id:17,train_loss:[0.06245909],eval_loss:0.9878709852695465epoch:63,batch_id:17,train_loss:[0.06174919],eval_loss:0.9875110030174256epoch:64,batch_id:17,train_loss:[0.06118464],eval_loss:0.987206107378006epoch:65,batch_id:17,train_loss:[0.06051154],eval_loss:0.9869666278362275epoch:66,batch_id:17,train_loss:[0.05986768],eval_loss:0.9865923523902893epoch:67,batch_id:17,train_loss:[0.05928758],eval_loss:0.9863128185272216epoch:68,batch_id:17,train_loss:[0.05866254],eval_loss:0.9859303057193756epoch:69,batch_id:17,train_loss:[0.05802014],eval_loss:0.9856755137443542epoch:70,batch_id:17,train_loss:[0.0575587],eval_loss:0.9854108214378356epoch:71,batch_id:17,train_loss:[0.05704111],eval_loss:0.985070925951004epoch:72,batch_id:17,train_loss:[0.05671573],eval_loss:0.9848090887069703epoch:73,batch_id:17,train_loss:[0.05617322],eval_loss:0.9845478892326355epoch:74,batch_id:17,train_loss:[0.05566153],eval_loss:0.9842156410217285epoch:75,batch_id:17,train_loss:[0.05529902],eval_loss:0.9840305268764495epoch:76,batch_id:17,train_loss:[0.05462031],eval_loss:0.9837329030036926epoch:77,batch_id:17,train_loss:[0.05434851],eval_loss:0.9835087835788727epoch:78,batch_id:17,train_loss:[0.05377433],eval_loss:0.9832845091819763epoch:79,batch_id:17,train_loss:[0.05343863],eval_loss:0.9830455482006073epoch:80,batch_id:17,train_loss:[0.05288152],eval_loss:0.982842218875885epoch:81,batch_id:17,train_loss:[0.05258711],eval_loss:0.982667338848114epoch:82,batch_id:17,train_loss:[0.05217287],eval_loss:0.9824033558368683epoch:83,batch_id:17,train_loss:[0.05160918],eval_loss:0.9821954727172851epoch:84,batch_id:17,train_loss:[0.05129151],eval_loss:0.9820389568805694epoch:85,batch_id:17,train_loss:[0.05077891],eval_loss:0.9820009410381317epoch:86,batch_id:17,train_loss:[0.05045455],eval_loss:0.9819312691688538epoch:87,batch_id:17,train_loss:[0.04997],eval_loss:0.9818430423736573epoch:88,batch_id:17,train_loss:[0.04965632],eval_loss:0.9816549181938171epoch:89,batch_id:17,train_loss:[0.04909806],eval_loss:0.9816236138343811epoch:90,batch_id:17,train_loss:[0.04883103],eval_loss:0.9815687894821167epoch:91,batch_id:17,train_loss:[0.04832352],eval_loss:0.9815601170063019epoch:92,batch_id:17,train_loss:[0.04800665],eval_loss:0.9814506828784942epoch:93,batch_id:17,train_loss:[0.04761852],eval_loss:0.9812910079956054epoch:94,batch_id:17,train_loss:[0.04736731],eval_loss:0.9812990665435791epoch:95,batch_id:17,train_loss:[0.04682],eval_loss:0.9812341630458832epoch:96,batch_id:17,train_loss:[0.04646796],eval_loss:0.9810558021068573epoch:97,batch_id:17,train_loss:[0.04601882],eval_loss:0.9810874044895173epoch:98,batch_id:17,train_loss:[0.04565503],eval_loss:0.9811647534370422epoch:99,batch_id:17,train_loss:[0.04528417],eval_loss:0.9811281561851501Final loss: [0.04528417]
使用LSTM进行预测
长短期记忆网络飞桨API:
paddle.nn.LSTM(input_size, hidden_size, num_layers=1, direction=’forward’, dropout=0.0, time_major=False, weight_ih_attr=None, weight_hh_attr=None, bias_ih_attr=None, bias_hh_attr=None, name=None)
该OP是长短期记忆网络(LSTM),根据输出序列和给定的初始状态计算返回输出序列和最终状态。在该网络中的每一层对应输入的step,每个step根据当前时刻输入 xt 和上一时刻状态 ht−1,ct−1 计算当前时刻输出 yt 并更新状态 ht,ct 。
状态更新公式如下: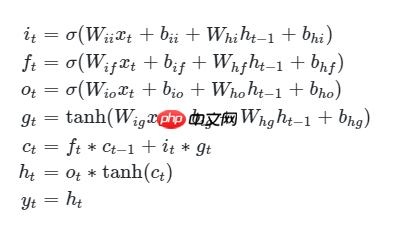
输入 :
inputs (Tensor) – 网络输入。如果time_major为True,则Tensor的形状为[time_steps,batch_size,input_size],如果time_major为False,则Tensor的形状为[batch_size,time_steps,input_size]。
initial_states (tuple,可选) – 网络的初始状态,一个包含h和c的元组,形状为[num_lauers * num_directions, batch_size, hidden_size]。如果没有给出则会以全零初始化。
sequence_length (Tensor,可选) – 指定输入序列的长度,形状为[batch_size],数据类型为int64或int32。在输入序列中所有time step不小于sequence_length的元素都会被当作填充元素处理(状态不再更新)。
 序列猴子开放平台
序列猴子开放平台
具有长序列、多模态、单模型、大数据等特点的超大规模语言模型
 0 查看详情
0 查看详情 
输出:
outputs (Tensor) – 输出,由前向和后向cell的输出拼接得到。如果time_major为True,则Tensor的形状为[time_steps,batch_size,num_directions * hidden_size],如果time_major为False,则Tensor的形状为[batch_size,time_steps,num_directions * hidden_size],当direction设置为bidirectional时,num_directions等于2,否则等于1。
final_states (tuple) – 最终状态,一个包含h和c的元组。形状为[num_lauers * num_directions, batch_size, hidden_size],当direction设置为bidirectional时,num_directions等于2,否则等于1。
In [ ]
#定义LSTM网络import paddle.fluid as fluidclass MyLSTMModel(fluid.dygraph.Layer): ''' DNN网络 ''' def __init__(self): super(MyLSTMModel,self).__init__() self.rnn = paddle.nn.LSTM(7, 14, 2) self.flatten = paddle.nn.Flatten() self.fc1=fluid.dygraph.Linear(120*14,120) self.fc2=fluid.dygraph.Linear(120,1) def forward(self,input): # forward 定义执行实际运行时网络的执行逻辑 '''前向计算''' # print('input',input.shape) out, (h, c)=self.rnn(input) out =self.flatten(out) out=self.fc1(out) out=self.fc2(out) return out
启动训练
lstm网络在cpu上会超级慢,想要使用GPU,可以安装paddlepaddle develop版本为了加快训练速度,使用了128*32大小的batch,这样一来训练数据少于10batch,所以设置为每1个batch评估一次In [ ]
Batch=0Batchs=[]all_train_loss=[]def draw_train_loss(Batchs, train_loss,eval_loss): title="training-eval loss" plt.title(title, fontsize=24) plt.xlabel("batch", fontsize=14) plt.ylabel("loss", fontsize=14) plt.plot(Batchs, train_loss, color='red', label='training loss') plt.plot(Batchs, eval_loss, color='g', label='eval loss') plt.legend() plt.grid() plt.show()
In [ ]
import paddle# place = fluid.CUDAPlace(0) #非develop版本请勿使用GPU版本place = fluid.CPUPlace()with fluid.dygraph.guard(place): model=MyLSTMModel() #模型实例化 # model=MyModel() model.train() #训练模式 # opt=fluid.optimizer.SGDOptimizer(learning_rate=0.001, parameter_list=model.parameters())#优化器选用SGD随机梯度下降,学习率为0.001. opt=fluid.optimizer.AdamOptimizer(learning_rate=0.01, parameter_list=model.parameters()) epochs_num=100#迭代次数 batch_size = 128*32 train_reader = fluid.io.batch(reader=switch_reader(), batch_size=batch_size) val_reader = fluid.io.batch(reader=switch_reader(is_val=True), batch_size=batch_size) Batch=0 Batchs=[] all_train_loss=[] all_eval_loss=[] for pass_num in range(epochs_num): for batch_id, data in enumerate(train_reader()): data_x=np.array([x[0] for x in data],np.float32) data_y = np.array([x[1] for x in data]).astype('float32') data_x = fluid.dygraph.to_variable(data_x) data_y = fluid.dygraph.to_variable(data_y) # print(data_x.shape, data_y.shape) predict=model(data_x) # print(predict.shape) loss=fluid.layers.mse_loss(predict,data_y) avg_loss=fluid.layers.mean(loss)#获取loss值 avg_loss.backward() opt.minimize(avg_loss) #优化器对象的minimize方法对参数进行更新 model.clear_gradients() #model.clear_gradients()来重置梯度 if batch_id!=0 and batch_id%1==0: Batch = Batch+1 Batchs.append(Batch) all_train_loss.append(avg_loss.numpy()[0]) evalavg_loss=[] for eval_data in val_reader(): eval_data_x = np.array([x[0] for x in eval_data],np.float32) eval_data_y = np.array([x[1] for x in eval_data]).astype('float32') eval_data_x = fluid.dygraph.to_variable(eval_data_x) eval_data_y = fluid.dygraph.to_variable(eval_data_y) eval_predict=model(eval_data_x) eval_loss=fluid.layers.mse_loss(eval_predict,eval_data_y) eval_loss=fluid.layers.mean(eval_loss) evalavg_loss.append(eval_loss.numpy()[0])#获取loss值 all_eval_loss.append(sum(evalavg_loss)/len(evalavg_loss)) print("epoch:{},batch_id:{},train_loss:{},eval_loss:{}".format(pass_num,batch_id,avg_loss.numpy(),sum(evalavg_loss)/len(evalavg_loss))) fluid.save_dygraph(model.state_dict(),'MyLSTMModel')#保存模型 fluid.save_dygraph(opt.state_dict(),'MyLSTMModel')#保存模型 print("Final loss: {}".format(avg_loss.numpy())) #让我们绘制训练图和验证损失图,以了解训练的进行情况。 draw_train_loss(Batchs,all_train_loss,all_eval_loss)
epoch:0,batch_id:8,train_loss:[41.62476],eval_loss:13.937688509623209epoch:1,batch_id:8,train_loss:[4.161157],eval_loss:2.6484082142512epoch:2,batch_id:8,train_loss:[2.1240506],eval_loss:1.698279857635498epoch:3,batch_id:8,train_loss:[1.1397613],eval_loss:1.2127376794815063epoch:4,batch_id:8,train_loss:[1.1065184],eval_loss:1.201335072517395epoch:5,batch_id:8,train_loss:[1.1207557],eval_loss:1.1899906992912292epoch:6,batch_id:8,train_loss:[1.126892],eval_loss:1.1028050978978474epoch:7,batch_id:8,train_loss:[1.1262866],eval_loss:1.0896229942639668epoch:8,batch_id:8,train_loss:[1.1331279],eval_loss:1.1011923948923747epoch:9,batch_id:8,train_loss:[1.1255071],eval_loss:1.101571758588155epoch:10,batch_id:8,train_loss:[1.1172327],eval_loss:1.0972675879796345epoch:11,batch_id:8,train_loss:[1.1123648],eval_loss:1.0952287912368774epoch:12,batch_id:8,train_loss:[1.1086842],eval_loss:1.0921181639035542epoch:13,batch_id:8,train_loss:[1.1045169],eval_loss:1.086412250995636epoch:14,batch_id:8,train_loss:[1.1000217],eval_loss:1.0816428860028584epoch:15,batch_id:8,train_loss:[1.0957059],eval_loss:1.0777405301729839epoch:16,batch_id:8,train_loss:[1.091319],eval_loss:1.073056121667226epoch:17,batch_id:8,train_loss:[1.0871797],eval_loss:1.0684852600097656epoch:18,batch_id:8,train_loss:[1.0834234],eval_loss:1.0644978284835815epoch:19,batch_id:8,train_loss:[1.0798335],eval_loss:1.0606069564819336epoch:20,batch_id:8,train_loss:[1.0764899],eval_loss:1.056948721408844epoch:21,batch_id:8,train_loss:[1.0734138],eval_loss:1.05355566740036epoch:22,batch_id:8,train_loss:[1.0705017],eval_loss:1.0503225127855937epoch:23,batch_id:8,train_loss:[1.0677806],eval_loss:1.0473219752311707epoch:24,batch_id:8,train_loss:[1.0652552],eval_loss:1.0444998741149902epoch:25,batch_id:8,train_loss:[1.0628968],eval_loss:1.0418291091918945epoch:26,batch_id:8,train_loss:[1.0606785],eval_loss:1.0393112301826477epoch:27,batch_id:8,train_loss:[1.058571],eval_loss:1.0369138320287068epoch:28,batch_id:8,train_loss:[1.0565668],eval_loss:1.0346330006917317epoch:29,batch_id:8,train_loss:[1.0546503],eval_loss:1.03245347738266epoch:30,batch_id:8,train_loss:[1.0528067],eval_loss:1.0303666790326436epoch:31,batch_id:8,train_loss:[1.0510274],eval_loss:1.0283629894256592epoch:32,batch_id:8,train_loss:[1.0493041],eval_loss:1.026433030764262epoch:33,batch_id:8,train_loss:[1.0476311],eval_loss:1.0245701869328816epoch:34,batch_id:8,train_loss:[1.0460036],eval_loss:1.0227669874827068epoch:35,batch_id:8,train_loss:[1.0444185],eval_loss:1.0210176308949788epoch:36,batch_id:8,train_loss:[1.0428716],eval_loss:1.0193172097206116epoch:37,batch_id:8,train_loss:[1.041361],eval_loss:1.0176609953244526epoch:38,batch_id:8,train_loss:[1.039884],eval_loss:1.016045093536377epoch:39,batch_id:8,train_loss:[1.0384375],eval_loss:1.0144659479459126epoch:40,batch_id:8,train_loss:[1.0370196],eval_loss:1.0129202802975972epoch:41,batch_id:8,train_loss:[1.0356268],eval_loss:1.0114047129948933epoch:42,batch_id:8,train_loss:[1.0342562],eval_loss:1.0099159677823384epoch:43,batch_id:8,train_loss:[1.0329046],eval_loss:1.0084505478541057epoch:44,batch_id:8,train_loss:[1.0315686],eval_loss:1.0070040822029114epoch:45,batch_id:8,train_loss:[1.030245],eval_loss:1.005572259426117epoch:46,batch_id:8,train_loss:[1.02893],eval_loss:1.0041507482528687epoch:47,batch_id:8,train_loss:[1.027621],eval_loss:1.0027351379394531epoch:48,batch_id:8,train_loss:[1.0263156],eval_loss:1.0013217131296794epoch:49,batch_id:8,train_loss:[1.0250111],eval_loss:0.9999080300331116epoch:50,batch_id:8,train_loss:[1.0237058],eval_loss:0.9984927773475647epoch:51,batch_id:8,train_loss:[1.0223969],eval_loss:0.9970751603444418epoch:52,batch_id:8,train_loss:[1.0210828],eval_loss:0.9956548611323038epoch:53,batch_id:8,train_loss:[1.0197608],eval_loss:0.9942313432693481epoch:54,batch_id:8,train_loss:[1.0184289],eval_loss:0.9928037524223328epoch:55,batch_id:8,train_loss:[1.0170839],eval_loss:0.9913713534673055epoch:56,batch_id:8,train_loss:[1.0157228],eval_loss:0.9899326960245768epoch:57,batch_id:8,train_loss:[1.0143429],eval_loss:0.9884872436523438epoch:58,batch_id:8,train_loss:[1.0129406],eval_loss:0.987034797668457epoch:59,batch_id:8,train_loss:[1.0115134],eval_loss:0.9855763912200928epoch:60,batch_id:8,train_loss:[1.0100583],eval_loss:0.9841130574544271epoch:61,batch_id:8,train_loss:[1.0085737],eval_loss:0.9826481342315674epoch:62,batch_id:8,train_loss:[1.0070602],eval_loss:0.9811853369077047epoch:63,batch_id:8,train_loss:[1.005519],eval_loss:0.9797286987304688epoch:64,batch_id:8,train_loss:[1.0039535],eval_loss:0.978282650311788epoch:65,batch_id:8,train_loss:[1.002368],eval_loss:0.9768513441085815epoch:66,batch_id:8,train_loss:[1.0007681],eval_loss:0.9754383365313212epoch:67,batch_id:8,train_loss:[0.99915963],eval_loss:0.9740457932154337epoch:68,batch_id:8,train_loss:[0.9975485],eval_loss:0.9726754426956177epoch:69,batch_id:8,train_loss:[0.9959406],eval_loss:0.9713284373283386epoch:70,batch_id:8,train_loss:[0.99434185],eval_loss:0.9700064063072205epoch:71,batch_id:8,train_loss:[0.9927588],eval_loss:0.9687100450197855epoch:72,batch_id:8,train_loss:[0.9911981],eval_loss:0.9674400091171265epoch:73,batch_id:8,train_loss:[0.9896648],eval_loss:0.9661963979403178epoch:74,batch_id:8,train_loss:[0.9881637],eval_loss:0.9649792909622192epoch:75,batch_id:8,train_loss:[0.9866975],eval_loss:0.963790496190389epoch:76,batch_id:8,train_loss:[0.9852681],eval_loss:0.9626333912213644epoch:77,batch_id:8,train_loss:[0.98387516],eval_loss:0.9615116119384766epoch:78,batch_id:8,train_loss:[0.98251814],eval_loss:0.9604288736979166epoch:79,batch_id:8,train_loss:[0.9811964],eval_loss:0.9593873818715414epoch:80,batch_id:8,train_loss:[0.9799079],eval_loss:0.958388884862264epoch:81,batch_id:8,train_loss:[0.9786506],eval_loss:0.9574349522590637epoch:82,batch_id:8,train_loss:[0.9774228],eval_loss:0.9565259019533793epoch:83,batch_id:8,train_loss:[0.97622156],eval_loss:0.9556620121002197epoch:84,batch_id:8,train_loss:[0.9750451],eval_loss:0.9548425475756327epoch:85,batch_id:8,train_loss:[0.9738902],eval_loss:0.954066793123881epoch:86,batch_id:8,train_loss:[0.9727558],eval_loss:0.9533333977063497epoch:87,batch_id:8,train_loss:[0.9716397],eval_loss:0.9526411096254984epoch:88,batch_id:8,train_loss:[0.9705405],eval_loss:0.9519882798194885epoch:89,batch_id:8,train_loss:[0.96945614],eval_loss:0.9513733386993408epoch:90,batch_id:8,train_loss:[0.96838456],eval_loss:0.9507946173350016epoch:91,batch_id:8,train_loss:[0.96732265],eval_loss:0.9502503275871277epoch:92,batch_id:8,train_loss:[0.9662684],eval_loss:0.9497395157814026epoch:93,batch_id:8,train_loss:[0.9652197],eval_loss:0.9492613275845846epoch:94,batch_id:8,train_loss:[0.9641763],eval_loss:0.9488150080045065epoch:95,batch_id:8,train_loss:[0.9631378],eval_loss:0.948401133219401epoch:96,batch_id:8,train_loss:[0.96210533],eval_loss:0.9480193853378296epoch:97,batch_id:8,train_loss:[0.9610793],eval_loss:0.9476695458094279epoch:98,batch_id:8,train_loss:[0.96005946],eval_loss:0.9473506410916647epoch:99,batch_id:8,train_loss:[0.9590464],eval_loss:0.9470618565877279Final loss: [0.9590464]
模型预测
由于没有划分测试集,在此使用验证集进行测试In [31]
import paddle# place = fluid.CUDAPlace(0) #非develop版本请勿使用GPU版本place = fluid.CPUPlace()with fluid.dygraph.guard(place): accs = [] # model_dict, _ = fluid.load_dygraph('MyLSTMModel.pdopt') model_dict, _ = fluid.load_dygraph('MyModel.pdopt') model = MyModel() # model=MyLSTMModel() model.load_dict(model_dict) #加载模型参数 val_reader = fluid.io.batch(reader=switch_reader(is_val=True), batch_size=batch_size) res=[] for batch_id, eval_data in enumerate(val_reader()): eval_data_x = np.array([x[0] for x in eval_data],np.float32) eval_data_y = np.array([x[1] for x in eval_data]).astype('float32') eval_data_x = fluid.dygraph.to_variable(eval_data_x) eval_data_y = fluid.dygraph.to_variable(eval_data_y) eval_predict=model(eval_data_x) res.append(eval_predict)res
总结
对比上面两个模型,都是采用相对比较简单的模型结构进行测试的DNN: 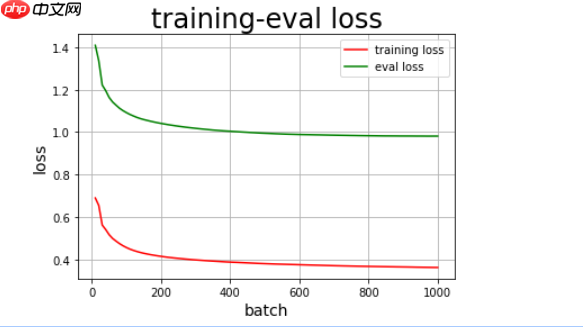 LSTM:
LSTM: 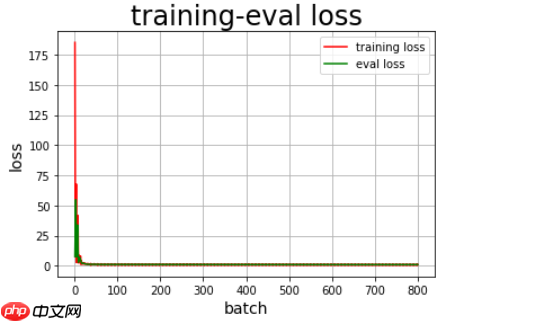 光看训练集的loss,会觉得DNN网络比较好,因为它的训练集loss下降到0.04528417,而添加了LSTM的网络loss只达到0.9590464,但我们再对比一下验证集的loss曲线会发现,DNN网络早就已经过拟合了,它的验证集maeloss最终只达到0.98左右,而同样的epoch,添加了LSTM的网络的maeloss与训练集的loss十分接近达到了0.94,甚至比训练集的loss还小一点。说明对于时序数据,LSTM更适合这样的任务。
光看训练集的loss,会觉得DNN网络比较好,因为它的训练集loss下降到0.04528417,而添加了LSTM的网络loss只达到0.9590464,但我们再对比一下验证集的loss曲线会发现,DNN网络早就已经过拟合了,它的验证集maeloss最终只达到0.98左右,而同样的epoch,添加了LSTM的网络的maeloss与训练集的loss十分接近达到了0.94,甚至比训练集的loss还小一点。说明对于时序数据,LSTM更适合这样的任务。
以上就是基于PaddlePaddle2.0.0rc使用LSTM进行北京空气污染序列预测的详细内容,更多请关注创想鸟其它相关文章!
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 chuangxiangniao@163.com 举报,一经查实,本站将立刻删除。
发布者:程序猿,转转请注明出处:https://www.chuangxiangniao.com/p/316686.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 






















