该项目可在一个项目中切换Stable Diffusion、waifu、NovelAI三大模型及权重,支持载入自主训练模型。进入Notebook后按步骤运行代码,含解压模型、安装库等,可实现文生图、图生图、超分等功能,也可批量生成,还介绍了参数、常见问题及非界面版玩法,方便用户集中操作。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

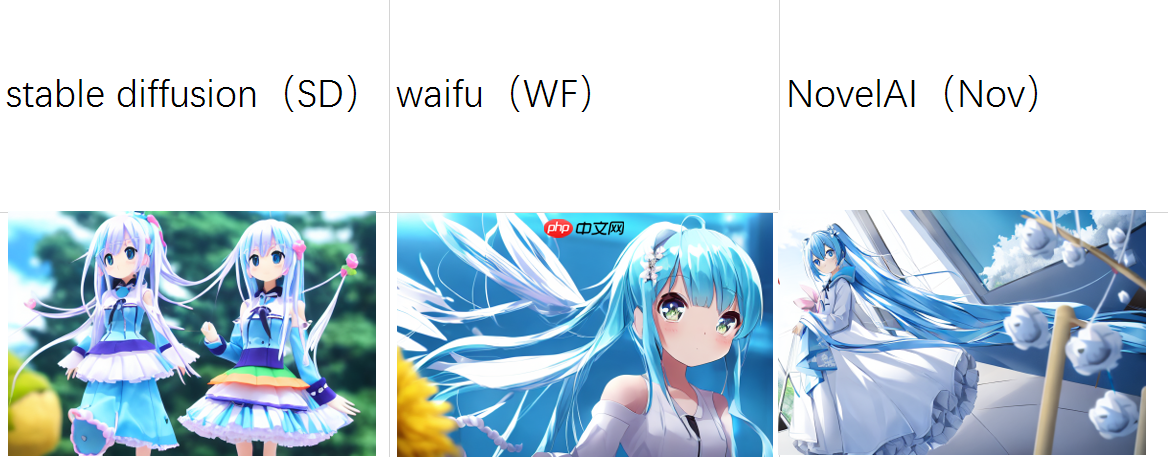
一个项目体验stable-diffusion、waifu、NovelAI三大模型!
Stable Diffusion、waifu、NovelAI三大模型及其权重 ,可以使用最基本模型权重组合,也同时可载入自主训练的模型(),模型无限创作无限。
有问题的话, 讨论区留言。
已知问题NovelAI 模型中CFG暂时无效果自训练模型中negative_prompt暂时无效果
项目背景 为了在一个项目中同时切换不同模型 权重 及自定义模型而设定,尽量增加多的功能,避免在不同项目执行和跳转。
一、进入 Notebook
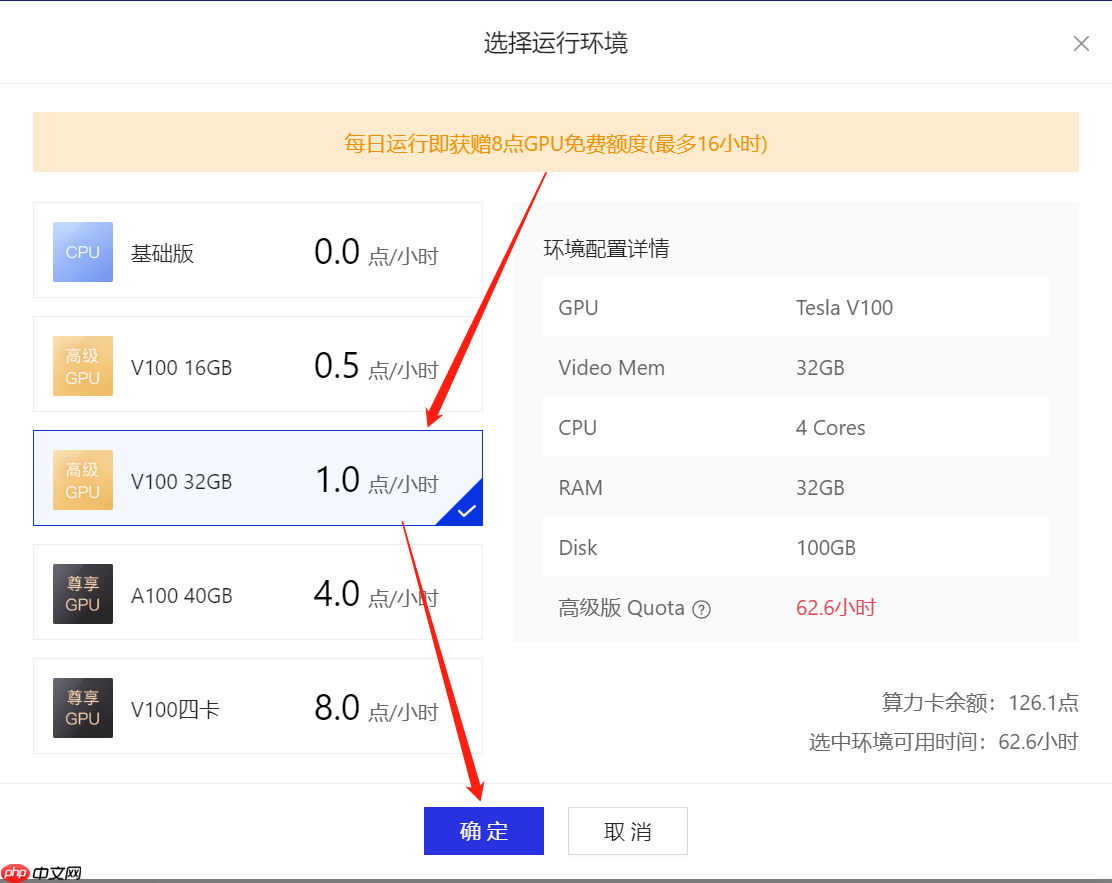
点击“运行一下”后,点击“启动环境”,选择合适的 GPU,进入项目。 AIStudio 每天自动赠送 8 小时的 GPU 算力。更厉害的 GPU 可以生成更大的图片。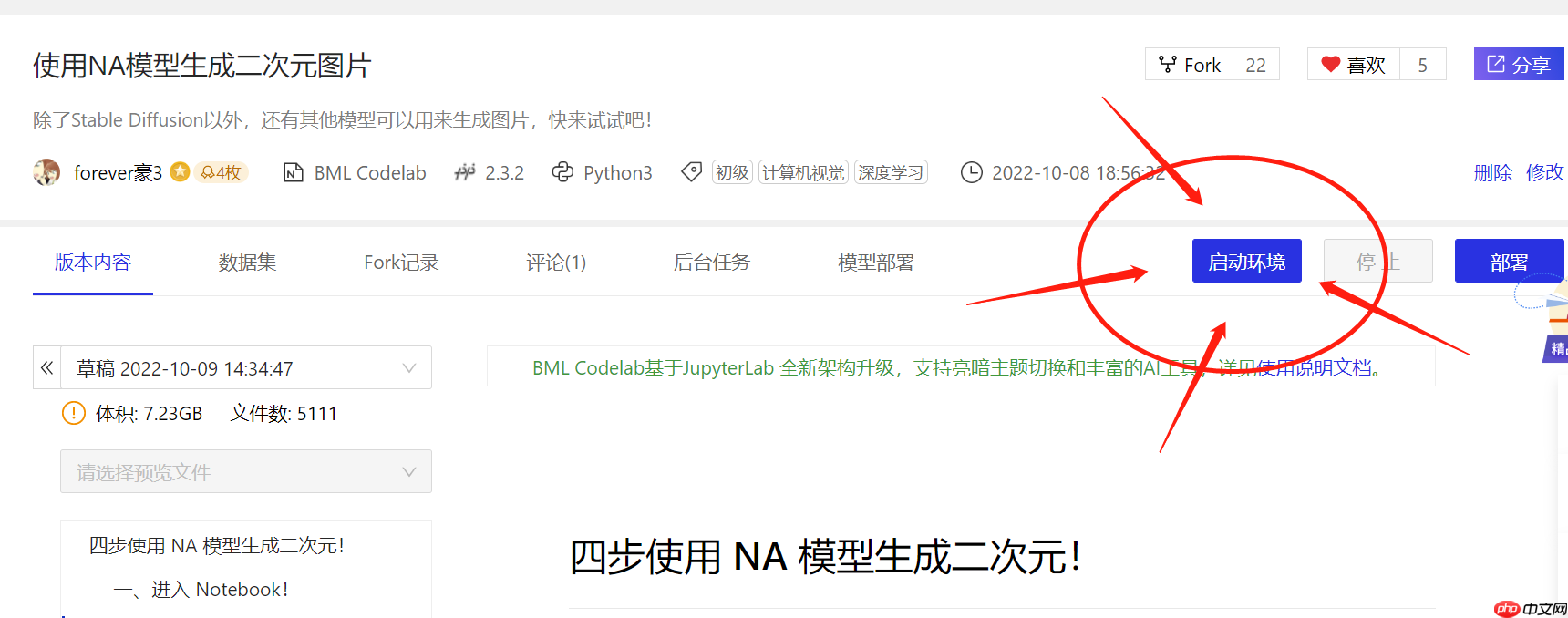
二、代码开始第一步 运行下面的代码!
进入之后,点击下边的框里左上角的“点击运行”(或者点进下面的框内用快捷键 Ctrl + Enter)
下面的代码只用在你第一次进入时运行!
下面的代码里在云环境里解压了模型文件,并且自动安装了各个文件。
等到显示“加载完毕”即可。如果中间可能出现红字:ERROR:pip’s …. 这个不用管,会自动继续。
(理想不超过7分钟,太慢可先用CPU环境解压,解压完了再换回GPU环境,或者去讨论区进入交流群)
In [1]
#下面的只能生成512 x 1024 的图,再大像素会报错 ,第一次运行后记得重启 ,第一次运行后记得重启 ,第一次运行后记得重启 import osfrom IPython.display import clear_outputfrom utils import check_is_model_completeprint('正在解压模型')if not check_is_model_complete("./NovelAI_latest_ab21ba3c_paddle"): # 解压 latest 模型 !unzip -o "/home/aistudio/data/data171442/NovelAI_latest_ab21ba3c_paddle.zip" # if not check_is_model_complete("./model_pruned_paddle"): # full 模型# !unzip -o "/home/aistudio/data/data171442/NovelAI_pruned_paddle.zip"if not os.path.exists("diffusers_paddle"): !unzip -o diffusers_paddle.zipprint('正在安装库')!pip install --upgrade pip -i https://mirror.baidu.com/pypi/simple!pip install -U fastcore paddlenlp ftfy regex --user -i https://mirror.baidu.com/pypi/simple!pip install --upgrade paddlenlp -i https://mirror.baidu.com/pypi/simpleprint('正在安装新版飞桨')# 如果需要生成 768 x 1024 则去掉下两行开头的井号运行一次 (运行成功一次即可), 但是可能卡, 建议挑人少的时候#!mv /home/aistudio/data/data168051/paddlepaddle-develop.whl /home/aistudio/data/data168051/paddlepaddle_gpu-0.0.0.post112-cp37-cp37m-linux_x86_64.whl#!pip install "/home/aistudio/data/data168051/paddlepaddle_gpu-0.0.0.post112-cp37-cp37m-linux_x86_64.whl" --userclear_output() # 清理很长的内容print('加载完毕, 下次不用再运行这里了')
加载完毕, 下次不用再运行这里了
重新启动项目也从这里开始
三、重启内核! 重新启动项目也从这里开始
点击上边栏的“重启内核” 重启内核图:

四、下载及解压SD预训练模型及waifu模型!
最后一步,点击左上角的“点击运行”运行下面的代码,等几秒加载模型就可以玩耍啦~ 以后每次进来直接运行下面这个就行啦~
In [ ]
# 下载及解压SD预训练模型及waifu模型 ,可能需要比较长的时间import osif not os.path.exists("CompVis-stable-diffusion-v1-4"): !wget https://paddlenlp.bj.bcebos.com/models/community/CompVis/stable-diffusion-v1-4/CompVis-stable-diffusion-v1-4.tar.gz !tar -zxvf CompVis-stable-diffusion-v1-4.tar.gz !rm -rf CompVis-stable-diffusion-v1-4.tar.gzif not os.path.exists("waifu-diffusion"): !wget http://bj.bcebos.com/paddlenlp/models/community/hakurei/waifu-diffusion/waifu-diffusion.tar.gz #waifu-diffusion-v1-2 !tar -zxvf waifu-diffusion.tar.gz !rm -rf waifu-diffusion.tar.gz #!wget https://paddlenlp.bj.bcebos.com/models/community/hakurei/waifu-diffusion/waifu-diffusion-v1-3.tar.gz #waifu-diffusion-v1-3 注意下面移动和解压 #!tar -zxvf waifu-diffusion-v1-3.tar.gz #!rm -rf waifu-diffusion-v1-3.tar.gz !unzip -o "data/data168051/stable-diffusion-v1-4.zip" !unzip -o "sd-concepts-library.zip"# if not os.path.exists("trinart_stable_diffusion_v2_95k"):# !wget http://bj.bcebos.com/paddlenlp/models/community/naclbit/trinart_stable_diffusion_v2/trinart_stable_diffusion_v2_95k.tar.gz# !tar -zxvf trinart_stable_diffusion_v2_95k.tar.gz# !rm -rf trinart_stable_diffusion_v2_95k.tar.gz
核心重启及项目重启后从这里开始 执行
In [17]
# 模型和权重加载都在这里,pipe 加载的权重,vae_path 加载的本体,如果第一次运行下面报错, 就重启内核重新运行一次from diffusers_paddle import StableDiffusionPipeline, StableDiffusionImg2ImgPipelineimport paddlefrom utils import save_image_infoimport ospipe = StableDiffusionPipeline.from_pretrained("./CompVis-stable-diffusion-v1-4") # 加载SD默认权重#pipe = StableDiffusionPipeline.from_pretrained("./waifu-diffusion") # 加载waifu权重#pipe = StableDiffusionPipeline.from_pretrained("./NovelAI_latest_ab21ba3c_paddle") # 加载NovelAI权重# pipe = StableDiffusionPipeline.from_pretrained("./model_pruned_paddle")vae_path = 'stable-diffusion-v1-4/model_state.pdparams' # 加载 SD默认 模型#vae_path = 'waifu-diffusion/unet/model_state.pdparams' # 加载 waifu 模型#vae_path = './NovelAI_latest_ab21ba3c_paddle/vae/animevae.pdparams' # 加载 NovelAI vae 模型pipe.vae.load_state_dict(paddle.load(vae_path)) # 换用更好的 vae (有效果!)# 图生图pipe_i2i = StableDiffusionImg2ImgPipeline(vae=pipe.vae,text_encoder=pipe.text_encoder,tokenizer=pipe.tokenizer,unet=pipe.unet,scheduler=pipe.scheduler,safety_checker=pipe.safety_checker,feature_extractor=pipe.feature_extractor)print('加载完毕')
加载完毕
In [1]
from ui import gui_txt2img # 文生图display(gui_txt2img.gui) # 生成的图片自动保存到左侧的 outputs 的文件夹里
VBox(children=(Textarea(value='extremely detailed CG unity 8k wallpaper,black long hair,cute face,1 adult girl…
In [3]
from ui import gui_img2img # 图生图, 在左侧上传图片, 然后修改 "需要转换的图片路径"display(gui_img2img.gui) # 生成的图片自动保存到左侧的 outputs 的文件夹里
VBox(children=(Textarea(value='Kurisu Makise, looking at viewer, long hair, standing, 1girl, hair ornament, ha…
In [2]
from ui import gui_superres # 超分 (图片放大一倍), 在左侧上传图片, 然后修改 "需要超分的图片路径"display(gui_superres.gui) # 生成的图片自动保存到左侧的 outputs 的文件夹里
VBox(children=(Text(value='image_Kurisu.png', description='需要超分的图片路径', layout=Layout(width='100%'), style=Desc…
常见问题
Q: 加载文件 main.ipynb 时出错 failed to fetch 错误是什么问题?
A:项目文件比较大有可能是挂载的问题,需要重新退出项目后再点启动项目试试,10.15后的版本已精简main文件。重新进入项目因加载模型过多各文件下的图片可能依然存在failed to fetch 错误,直接生成新图片即可.退出项目时记得保存生存图片并清理特定文件夹 同时清除全部输出!!!
Q: 能不能用使用自己训练的模型啊?
A: 可以的, 这里有2种训练方法https://aistudio.baidu.com/aistudio/projectdetail/4592929?channelType=0&channel=0。 直接把模型上传到sd-concepts-library 文件里后 就能使用,后期考虑添加相关的2种训练方法 inversion 和dreambooth 方法
Q: 能不能用中文描述啊?
A: 可以的, 但是效果不如英文。因为模型是用英语文本训练的。(可以去翻译软件里翻译一下)
Q: 生成的图怎么都一样的?
A: 如果设定了相同的随机数种子且其它参数相同,则生成的图也是一样的。
Q: 生成的时候进度条卡住, 然后弹出一个框框:The kernel for main.ipynb appears to have died. It will restart automatically.?
A: 生成图片尺寸太大了!可以重启内核改用较小的尺寸,或者重新进入更换更大的 GPU。
Q: 其它神秘问题?
A: 请去评论区进讨论群。如果是默认的参数无法生成,可以删除该项目重新 Fork 一份从头开始。
非界面版 (推荐)
如果你不满足于上面的界面玩法, 那么不妨来试试下面的部分!(下面有图生图哦)
 Stable Diffusion 2.1 Demo
Stable Diffusion 2.1 Demo
最新体验版 Stable Diffusion 2.1
 75 查看详情
75 查看详情 
如果第一次运行下面报错, 不要惊慌!重启内核重新运行一次!
文生图
参数:
height 图片高度 (常用 512,768,1024等)width 图片宽度 (常用 512,768,1024等)seed 随机数种子(如果是None则为自动随机)steps 生成步数cfg 引导比例prompt 描述内容negative_prompt 反面描述内容
注:生成图片尺寸越大, 则需要时间越久
注: 描述内容太长的话, 可以用右斜线 换行.
生成的图都在 outputs 文件夹里。
In [ ]
height = 512width = 768seed = 3354985548steps = 50cfg = 7 prompt = "miku, looking at viewer, long hair, standing, 1girl, hair ornament, hair flower, cute, jacket, white flower, white dress 精灵耳朵"#negative_prompt = "{mucha},{extremely detailed 4K CG},{original}, {{masterpiece}},lowres, bad anatomy, bad hands, text, error, missing fingers, extra digit, fewer digits, #cropped, worst quality, low quality, normal quality, jpeg artifacts, signature, watermark, username, blurry"image = pipe(prompt,height=height,width=width,num_inference_steps=steps,guidance_scale=cfg,seed=seed,negative_prompt=negative_prompt).images[0]print('Seed =', image.argument['seed'])display(image)save_image_info(image, path = './jpgout/') # 保存图片到指定位置
In [3]
image.argument # 查看图片生成使用的参数
{'prompt': 'miku, looking at viewer, long hair, standing, 1girl, hair ornament, hair flower, cute, jacket, white flower, white dress', 'height': 512, 'width': 768, 'num_inference_steps': 50, 'guidance_scale': 7, 'negative_prompt': 'lowres, bad anatomy, bad hands, text, error, missing fingers, extra digit, fewer digits, cropped, worst quality, low quality, normal quality, jpeg artifacts, signature, watermark, username, blurry', 'eta': 0.0, 'seed': 1835537382, 'latents': None}
批量文生图
参数:
number 生成图片数量
注:批量就不要设置种子, 否则出来的图都一样。
生成的图都在 outputs 文件夹里。
In [ ]
# 批量文生图number = 2height = 768 width = 512steps = 50cfg = 17.5 prompt = "kitsune made out of flames, digital art, synthwave . "negative_prompt = "{mucha},{extremely detailed 4K CG},{original}, {{masterpiece}},lowres, bad anatomy, bad hands, text, error, missing fingers, extra digit, fewer digits, cropped, worst quality, low quality, normal quality, jpeg artifacts, signature, watermark, username, blurry"for i in range(number): image = pipe(prompt,height=height,width=width,num_inference_steps=steps,guidance_scale=cfg,negative_prompt=negative_prompt).images[0] save_image_info(image, path = './jpgout/') display(image)
In [ ]
# 批量文生图number = 2height = 768 width = 512steps = 50cfg = 17.5 prompt = "kitsune made out of flames, digital art, synthwave . "negative_prompt = "lowres, bad anatomy, bad hands, text, error, missing fingers, extra digit, fewer digits, cropped, worst quality, low quality, normal quality, jpeg artifacts, signature, watermark, username, blurry"for i in range(number): image = pipe(prompt,height=height,width=width,num_inference_steps=steps,guidance_scale=cfg,negative_prompt=negative_prompt).images[0] save_image_info(image, path = './jpgout/') display(image)
图生图
参数:
path 图片路径 (在左边上传图片)steps 生成步数seed 随机数种子 (如果是 None 则为自动随机)strength 修改强度 (默认 0.8)cfg 引导比例 (默认 7.5)prompt 描述内容negative_prompt 反面描述内容
注: 描述内容太长的话, 可以用右斜线 换行.
生成的图都在 outputs 文件夹里。
In [ ]
path = "image_Kurisu.png"steps = 50seed = 20221008strength = 0.8cfg = 7.5prompt = "kitsune made out of flames, digital art, synthwave "negative_prompt = "lowres, bad anatomy, bad hands, text, error, missing fingers, extra digit, fewer digits, cropped, worst quality, low quality, normal quality, jpeg artifacts, signature, watermark, username, blurry" from utils import ReadImageinit_image = ReadImage(path, height=-1, width=-1) # -1 为自动判断图片大小image2 = pipe_i2i(prompt,init_image=init_image,num_inference_steps=steps,strength=strength,guidance_scale=cfg,seed=seed,negative_prompt=negative_prompt)[0][0]print('Seed =', image2.argument['seed'])display(image2)save_image_info(image2, path = './outputs/') # 保存图片到指定位置
In [9]
image2.argument # 查看图片生成使用的参数
{'prompt': 'Kurisu Makise', 'init_image': , 'strength': 0.8, 'num_inference_steps': 50, 'guidance_scale': 7.5, 'negative_prompt': 'lowres, bad anatomy, bad hands, text, error, missing fingers, extra digit, fewer digits, cropped, worst quality, low quality, normal quality, jpeg artifacts, signature, watermark, username, blurry', 'eta': 0.0, 'seed': 20221008}
 ### 批量图生图
### 批量图生图
参数:
number 生成图片数量
注:批量就不要设置种子, 否则出来的图都一样。
生成的图都在 outputs 文件夹里。
In [ ]
number = 10path = "https://www.chuangxiangniao.com/wp-content/uploads/2025/11/175306710847236.jpg" #替换了一个网络图片steps = 50strength = 0.8cfg = 13.5prompt = "miku is Sitting on a wooden chair with porcelain on a wooden multi-purpose shelf behind her while With incense burner at the top of the shelf, looking at viewer, long hair, standing, 1girl, hair ornament, hair flower, cute, jacket, white flower, white dress"negative_prompt = "lowres, bad anatomy, bad hands, text, error, missing fingers, extra digit, fewer digits, cropped, worst quality, low quality, normal quality, jpeg artifacts, signature, watermark, username, blurry" from utils import ReadImageinit_image = ReadImage(path, height=-1, width=-1) # -1 为自动判断图片大小for i in range(number): image2 = pipe_i2i(prompt,init_image=init_image,num_inference_steps=steps,strength=strength,guidance_scale=cfg,negative_prompt=negative_prompt)[0][0] save_image_info(image2, path = './outputs/') display(image2)
训练模型生图
直接用了 凉心半浅良心人的代码
**需要自己训练自己对象和风格的 直接点 **
Stable Diffsuion textual_inversion训练
https://aistudio.baidu.com/aistudio/projectdetail/4592929?channelType=0&channel=0
In [ ]
learned_embeded_path = "sd-concepts-library/Marc_Allante-style.pdparams"for token, embeds in paddle.load(learned_embeded_path).items(): pipe.tokenizer.add_tokens(token) pipe.text_encoder.resize_token_embeddings(len(pipe.tokenizer)) token_id = pipe.tokenizer.convert_tokens_to_ids(token) with paddle.no_grad(): pipe.text_encoder.get_input_embeddings().weight[token_id] = embedsprompt = f"a colorful color painting of {token} styles ,kitsune made out of flames, digital art, synthwave. " #如果不是图片风格是物体 使用a photo of a {token}# negative_prompt = "lowres, bad anatomy, bad hands, text, error, missing fingers, extra digit, fewer digits, cropped, worst quality, low quality, normal quality, jpeg artifacts, signature, watermark, username, blurry"num_samples = 1 #图片数量 images = pipe([prompt] * num_samples, height=704, width=512, num_inference_steps=50 , guidance_scale=7.5,seed=1788937216).imagesfor img in images: display(img) save_image_info(img, path = './learnout/')

In [ ]
learned_embeded_path = "sd-concepts-library/hitokomoru-style.pdparams"for token, embeds in paddle.load(learned_embeded_path).items(): pipe.tokenizer.add_tokens(token) pipe.text_encoder.resize_token_embeddings(len(pipe.tokenizer)) token_id = pipe.tokenizer.convert_tokens_to_ids(token) with paddle.no_grad(): pipe.text_encoder.get_input_embeddings().weight[token_id] = embedsprompt = f"a colorful color painting of {token} styles ,kitsune made out of flames, digital art, synthwave. "# negative_prompt = "lowres, bad anatomy, bad hands, text, error, missing fingers, extra digit, fewer digits, cropped, worst quality, low quality, normal quality, jpeg artifacts, signature, watermark, username, blurry"num_samples = 1 #图片数量 images = pipe([prompt] * num_samples, height=704, width=512, num_inference_steps=50, guidance_scale=17.5,seed=2788937216).imagesfor img in images: display(img)

自训练模型批量图生图
参数:
pipe 加载的权重learned_embeded_patnumg = 50 #生成图片数量
注:批量就不要设置种子, 否则出来的图都一样。
生成的图都在 outputs 文件夹里。
In [ ]
# 加载权重文件pipe = StableDiffusionPipeline.from_pretrained("./waifu-diffusion")#pipe = StableDiffusionPipeline.from_pretrained("./CompVis-stable-diffusion-v1-4")#pipe = StableDiffusionPipeline.from_pretrained("./NovelAI_latest_ab21ba3c_paddle")# 加载sd-concepts-library中的训练模型 learned_embeded_path = "sd-concepts-library/huang-guang-jian-style.pdparams"
In [ ]
# 自训练模型生成多张图片for token, embeds in paddle.load(learned_embeded_path).items(): pipe.tokenizer.add_tokens(token) pipe.text_encoder.resize_token_embeddings(len(pipe.tokenizer)) token_id = pipe.tokenizer.convert_tokens_to_ids(token) with paddle.no_grad(): pipe.text_encoder.get_input_embeddings().weight[token_id] = embedsimport timetimestring = time.strftime('%Y%m%d%H%M%S') #a colorful painting of {token} styles,prompt = f"a colorful color painting of {token} styles ,kitsune made out of flames, digital art, synthwave. "negative_prompt = "lowres, bad anatomy, bad hands, text, error, missing fingers, extra digit, fewer digits, cropped, worst quality, low quality, normal quality, jpeg artifacts, signature, watermark, username, blurry"numg = 50 #图片数量 num_samples = 1for _ in range(numg): with paddle.no_grad(): image = pipe([prompt] * num_samples,num_inference_steps=100,width=1024,height=512,negative_prompt=[negative_prompt],guidance_scale=13.5).images[0] timestring = time.strftime('%Y%m%d%H%M%S') image.save(f"./learnout/{timestring}_.png") # image.save(f"./jpg/{timestring}.png") with open(f'./learnout/{timestring}.txt', 'w') as f: print(image.argument,file = f) display(image.argument) display(image)
清理特定文件夹
确保已经下载该文件 且压缩文件能正常打开
如果清理后退出内核,需要清除本文档的全部输出 避免加载出错会清空相应文件夹下所有文件 运行前务必保存 ,运行前务必保存,运行前务必保存打包下载100M以上的文件有可能出现压缩包错误,所以就算下载后也务必检查 避免删除没保存的图In [31]
# 清理文件夹使用 确保已经下载文件#删除文件夹下面的所有文件(只删除文件,不删除文件夹)import osimport shutil#python删除文件的方法 os.remove(path)path指的是文件的绝对路径,如:def del_file(path_data): for i in os.listdir(path_data) :# os.listdir(path_data)#返回一个列表,里面是当前目录下面的所有东西的相对路径 file_data = path_data + "/" + i#当前文件夹的下面的所有东西的绝对路径 if os.path.isfile(file_data) == True:#os.path.isfile判断是否为文件,如果是文件,就删除.如果是文件夹.递归给del_file. os.remove(file_data) else: del_file(file_data)#path_data = r"jpgout" # 删除TXT 生成的文件path_data = r"outputs" #删除图生图 生成的文件#path_data = r"learnout" #删除自训练文生图 生成的文件del_file(path_data)
以上就是一个项目体验stable-diffusion、waifu、NovelAI三大模型的详细内容,更多请关注创想鸟其它相关文章!
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 chuangxiangniao@163.com 举报,一经查实,本站将立刻删除。
发布者:程序猿,转转请注明出处:https://www.chuangxiangniao.com/p/317078.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫