
清华大学联合快手可灵团队推出了一款全新的生成模型——svg(无 vae 潜在扩散模型),在图像生成领域实现了突破性进展。该模型不仅将训练效率提升了6200%,更在生成速度上实现了高达3500% 的飞跃,标志着对传统 vae 架构的重大超越。
长期以来,VAE 在图像生成中的应用受限于“语义纠缠”问题:当试图修改图像某一属性(例如猫的毛色)时,其他无关特征(如姿态、体型)也可能被意外改变,导致控制精度下降。为应对这一挑战,清华与快手团队设计了全新的 SVG 模型,摒弃传统 VAE 编码方式,转而构建一个既能保留高层语义又能捕捉细节纹理的统一特征空间。
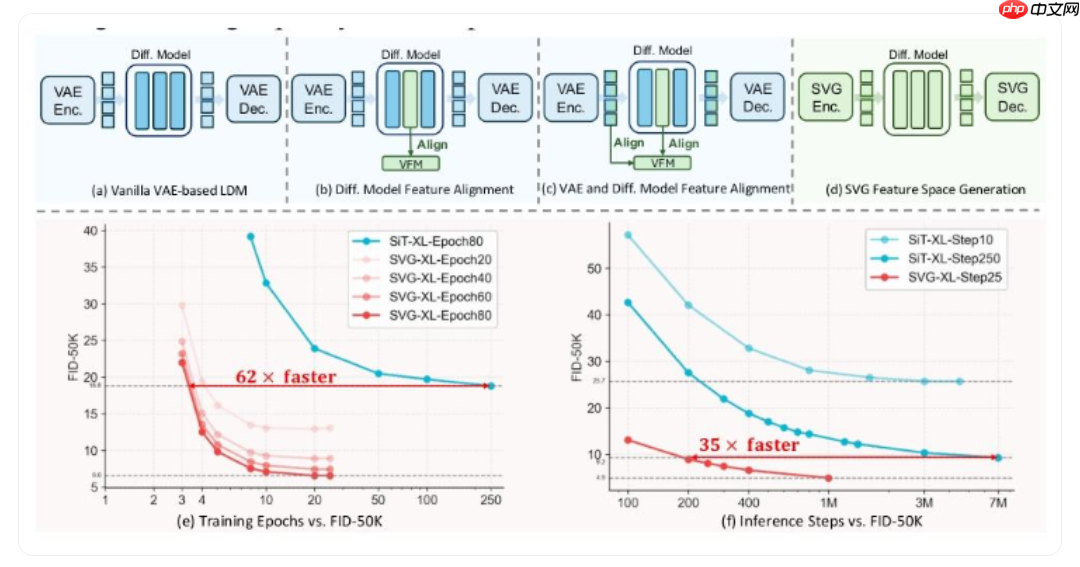
SVG 的核心架构首先引入 DINOv3 预训练模型作为语义编码器。得益于其强大的自监督学习能力,DINOv3 能精准提取并分离图像中的类别级语义信息,有效避免了语义混淆。与此同时,研究团队开发了一个轻量化的残差编码器,专门负责捕获细微的局部结构和纹理细节,并确保这些信息与高层语义互不干扰。通过引入关键的分布对齐机制,两种特征得以高效融合,从而保障最终生成图像的质量与一致性。
 可图大模型
可图大模型
可图大模型(Kolors)是快手大模型团队自研打造的文生图AI大模型
 32 查看详情
32 查看详情 

实验证明,SVG 模型在多项指标上显著优于传统 VAE 方法。在 ImageNet 数据集上,仅经过80轮训练,SVG 即达到6.57的 FID 分数(越低表示生成图像越接近真实),性能远超同级别 VAE 模型。在推理阶段,SVG 同样表现出色,能够在极少采样步数下稳定输出高清晰度图像。更重要的是,其学习到的特征空间具备出色的泛化能力,可直接应用于图像分类、语义分割等下游任务,无需额外微调,极大增强了模型的实用性和部署灵活性。
以上就是清华与快手联手推出新型 SVG 扩散模型,训练效率暴增 6200%的详细内容,更多请关注创想鸟其它相关文章!
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 chuangxiangniao@163.com 举报,一经查实,本站将立刻删除。
发布者:程序猿,转转请注明出处:https://www.chuangxiangniao.com/p/320989.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 





















