
我们以抓取博客内容为例,为大家展示如何操作。
#抓取标题与链接#
使用Python获取我的博客中所有文章的标题及其对应链接。(需翻页处理,各页面URL规律如下:第二页为https://www.php.cn/link/2c2c5fd01b61e3e0e687573af8f7e1fa/page/2/,第三页为 https://www.php.cn/link/649f7e2bf4d7efb62d56f6090cf943eb https://www.php.cn/link/9191b0a3b4c41e6732dbb644bd52d6fc 将最终结果导出为csv文件。文章标题的HTML结构示例如下:
Homeassistant界面美化
HAPPY TEACHER’S DAY
 代码小浣熊
代码小浣熊
代码小浣熊是基于商汤大语言模型的软件智能研发助手,覆盖软件需求分析、架构设计、代码编写、软件测试等环节
 51 查看详情
51 查看详情 
 可以看到,讲解非常详细。
可以看到,讲解非常详细。
运行生成的代码,效果如下:
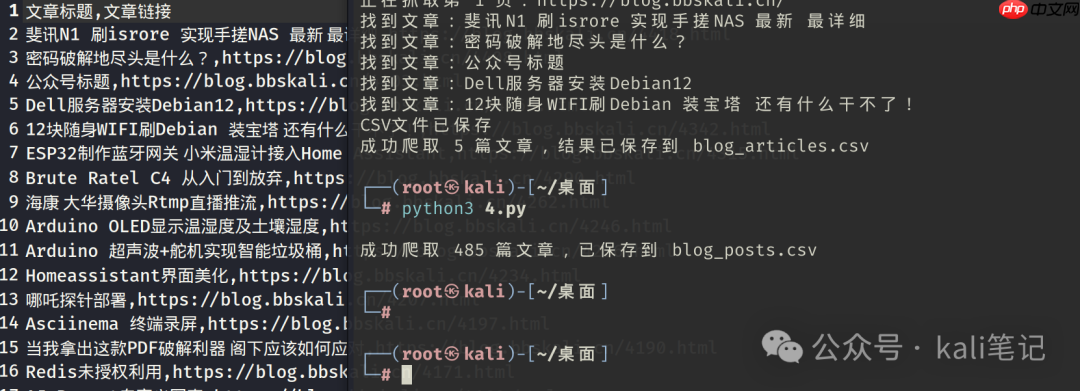 接下来,我们尝试更复杂一点的任务:提取每篇文章的阅读次数、评论数量以及发布时间。
接下来,我们尝试更复杂一点的任务:提取每篇文章的阅读次数、评论数量以及发布时间。
 新建对话内容如下:
新建对话内容如下:
#抓取文章阅读量、评论数、发布日期#
很好,之前的代码已经成功获取了博客的所有标题和链接。现在我需要你进入每一篇文章的具体页面,提取其阅读量、评论数和发布时间。相关HTML代码结构如下:
HAPPY TEACHER’S DAY

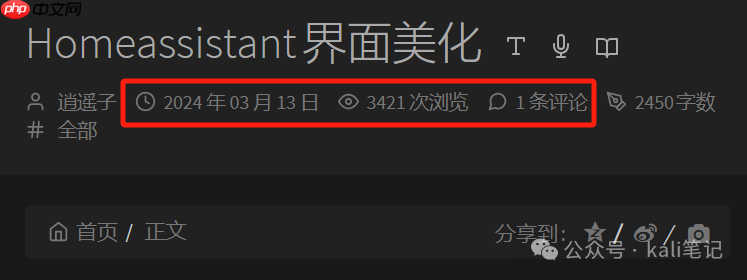
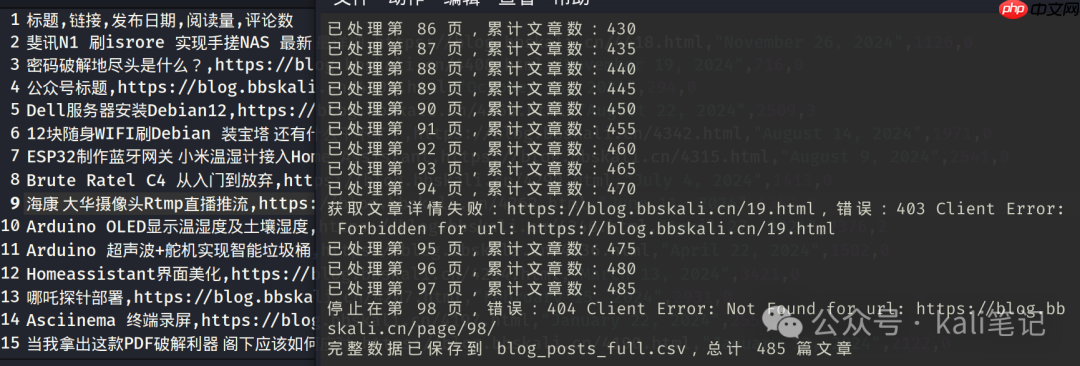 实际运行效果
实际运行效果
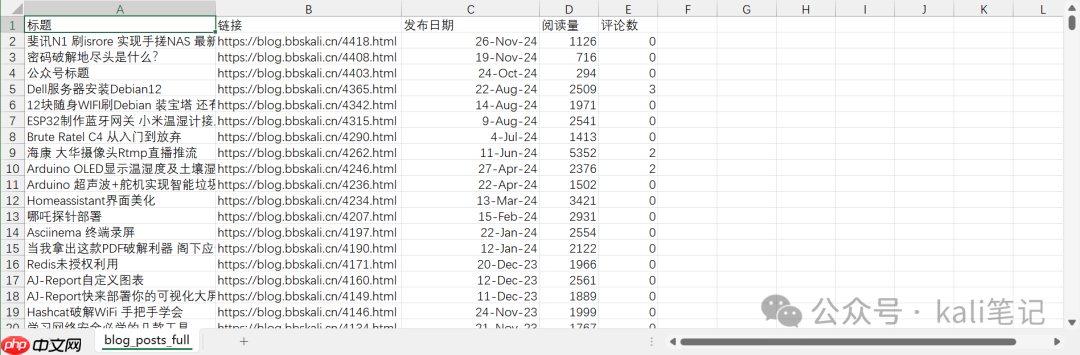 完整代码如下
完整代码如下
import requestsfrom bs4 import BeautifulSoupimport csvimport reimport timedef get_post_details(url, headers):try:response = requests.get(url, headers=headers)response.raise_for_status()except Exception as e:print(f"获取文章详情失败:{url},错误:{str(e)}")return None, None, None
soup = BeautifulSoup(response.text, 'html.parser')
提取发布时间
dateli = soup.find('li', class='meta-date')post_date = date_li.find('time').text.strip() if date_li else ''
提取阅读量
viewsli = soup.find('li', class='meta-views')views = 0if views_li:views_text = viewsli.find('span', class='meta-value').textmatch = re.search(r'(d+)', views_text.replace(' ', ' '))views = match.group(1) if match else 0
提取评论数
commentsli = soup.find('li', class='meta-comments')comments = 0if comments_li:comments_tag = commentsli.find('a', class='meta-value') or commentsli.find('span', class='meta-value')if comments_tag:match = re.search(r'(d+)', comments_tag.text)comments = match.group(1) if match else 0
return post_date, views, comments
def get_all_posts():base_url = "https://www.php.cn/link/2c2c5fd01b61e3e0e687573af8f7e1fa"headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3'}
all_data = []page_num = 1
while True:
构造分页链接
url = f"{base_url}/page/{page_num}/" if page_num > 1 else base_url try: response = requests.get(url, headers=headers) response.raise_for_status() except Exception as e: print(f"停止在第 {page_num} 页,错误:{str(e)}") break soup = BeautifulSoup(response.text, 'html.parser') posts = soup.find_all('div', class_='post_title_wrapper') if not posts: break for post in posts: h2_tag = post.find('h2', class_='index-post-title') if not h2_tag: continue a_tag = h2_tag.find('a') if a_tag and a_tag.has_attr('href'): title = a_tag.text.strip() link = a_tag['href'] # 获取文章详细信息 post_date, views, comments = get_post_details(link, headers) # 汇总数据 all_data.append([ title, link, post_date, views, comments ]) # 添加请求间隔,避免对服务器造成压力 time.sleep(0.5) print(f"已处理第 {page_num} 页,累计文章数:{len(all_data)}") page_num += 1写入CSV文件
with open('blog_posts_full.csv', 'w', newline='', encoding='utf-8-sig') as f:writer = csv.writer(f)writer.writerow(['标题', '链接', '发布日期', '阅读量', '评论数'])writer.writerows(all_data)
return len(all_data)
if name == "main":count = get_all_posts()print(f"完整数据已保存到 blog_posts_full.csv,总计 {count} 篇文章")
示例输出
"""已处理第 1 页,累计文章数:10已处理第 2 页,累计文章数:20...完整数据已保存到 blog_posts_full.csv,总计 56 篇文章"""
总结:
借助DeepSeek,我们可以轻松生成所需的爬虫代码。当然,前提是我们必须清晰准确地描述需求!
以上就是不会写代码 用DeepSeek实现爬虫的详细内容,更多请关注创想鸟其它相关文章!
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 chuangxiangniao@163.com 举报,一经查实,本站将立刻删除。
发布者:程序猿,转转请注明出处:https://www.chuangxiangniao.com/p/326369.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 























