
上海人工智能实验室 opendatalab 团队近日正式推出 mineru2.5 技术白皮书,全面介绍其模型结构、训练方法、数据处理流程及多项评测表现。
MinerU2.5 是一款具备 12 亿参数的解耦式视觉-语言模型,专为高分辨率文档理解而设计。项目团队同步上线了官方 Demo,用户可在线体验其强大功能。

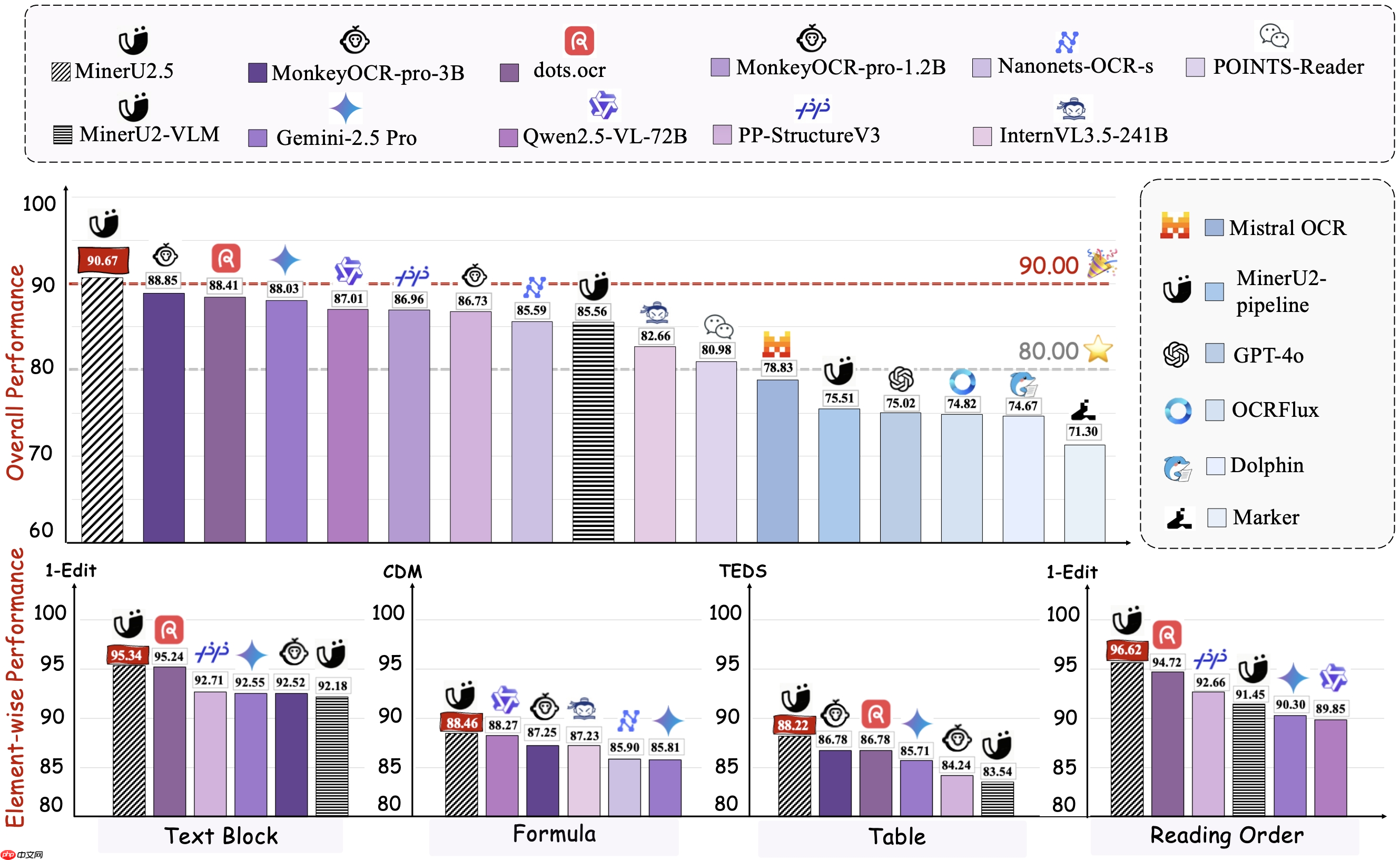
该模型采用创新的两阶段解析机制:第一阶段对降采样图像进行整体版面布局分析;第二阶段则在原始分辨率下,针对局部区域实现文本、数学公式与表格的精细化识别。这一架构在 OmniDocBench 等多个权威基准测试中均达到领先水平(SOTA),同时兼顾高效推理与较低计算资源消耗。
 腾讯混元文生视频
腾讯混元文生视频
腾讯发布的AI视频生成大模型技术
 137 查看详情
137 查看详情 
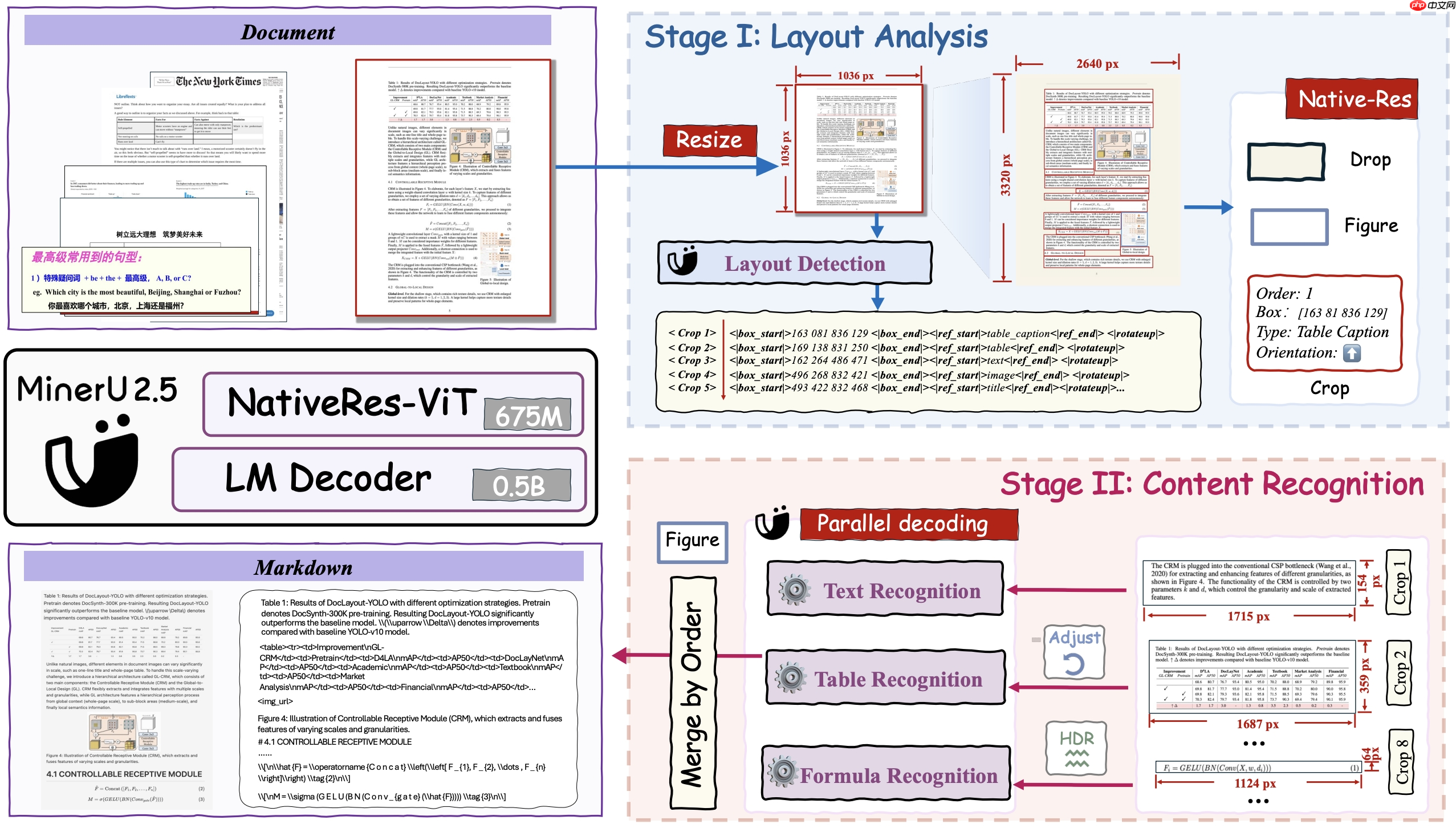
MinerU2.5 能够精准保留页眉、页脚和页码等页面装饰性元素,并进一步优化了对列表项、参考文献、代码段等结构的标注精度。此外,模型支持复杂长公式解析,兼容中英文混合排版的数学表达式,并可准确识别旋转排布、无边框或部分边框的表格结构。
开源项目:https://www.php.cn/link/918b71f2ac42210cfae2f82b777c1f27开源模型:https://www.php.cn/link/607f81b73375b618f549c6c8692c4e88在线使用:https://www.php.cn/link/4612cc4ffdf8a7dbd4174702b9b22afd
源码地址:点击下载
以上就是OpenDataLab 发布文档解析视觉-语言模型 MinerU2.5 技术报告的详细内容,更多请关注创想鸟其它相关文章!
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 chuangxiangniao@163.com 举报,一经查实,本站将立刻删除。
发布者:程序猿,转转请注明出处:https://www.chuangxiangniao.com/p/331589.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 





















