大数据文摘出品
大数据文摘出品
来源:lambdalabs
编译:张秋玥
随着深度学习模型变得更加强大,它们也需要更多的内存空间,但许多GPU的VRAM不足以满足需求。
如果你正准备进入深度学习领域,你应该选择哪种GPU呢?以下是一些适合深度学习模型训练的GPU的横向比较,一起来看看吧!
简要概览
截至2020年2月,以下GPU能够训练所有当前的语言和图像模型:
RTX 8000:48GB VRAM,约5500美元RTX 6000:24GB VRAM,约4000美元Titan RTX:24GB VRAM,约2500美元以下GPU能够训练大多数(但不是全部)模型:
RTX 2080 Ti:11GB VRAM,约1150美元GTX 1080 Ti:11GB VRAM,返厂翻新机约800美元RTX 2080:8GB VRAM,约720美元RTX 2070:8GB VRAM,约500美元以下GPU不适合用于训练当前模型:
RTX 2060:6GB VRAM,约359美元。在此GPU上训练需要较小的批次大小,模型的分布近似会受到影响,从而可能降低模型精度。
图像模型
最大批处理大小(在内存不足之前):
 一览运营宝
一览运营宝
一览“运营宝”是一款搭载AIGC的视频创作赋能及变现工具,由深耕视频行业18年的一览科技研发推出。
 41 查看详情
41 查看详情 
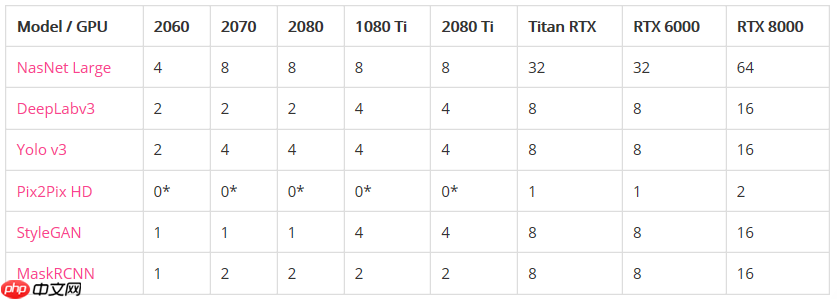 *表示GPU没有足够的内存来运行模型。
*表示GPU没有足够的内存来运行模型。
性能(以每秒处理的图像为单位):
*表示GPU没有足够的内存来运行模型。
语言模型
最大批处理大小(在内存不足之前):
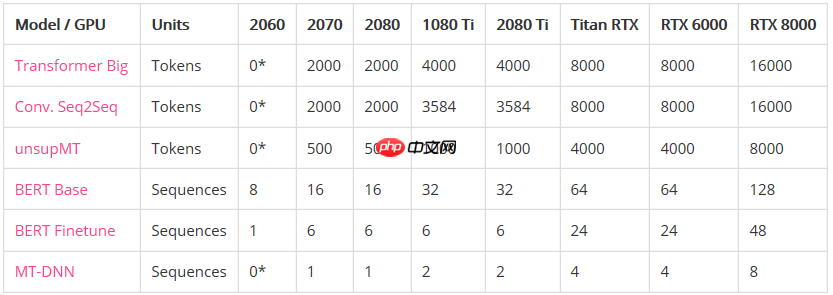 *表示GPU没有足够的内存来运行模型。
*表示GPU没有足够的内存来运行模型。
性能:
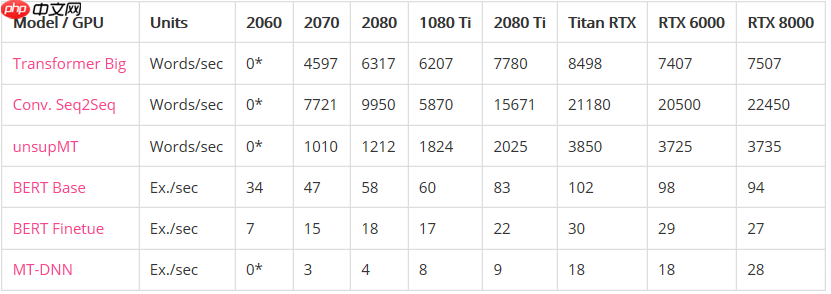 * GPU没有足够的内存来运行模型。
* GPU没有足够的内存来运行模型。
使用Quadro RTX 8000结果进行标准化后的表现
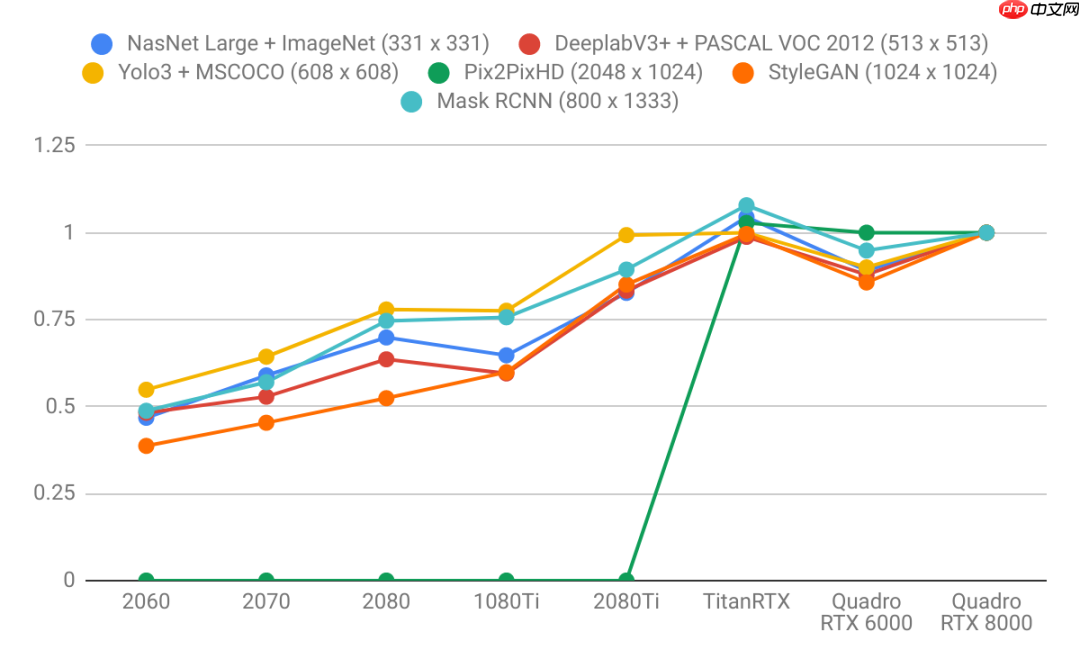
图像模型
 语言模型
语言模型
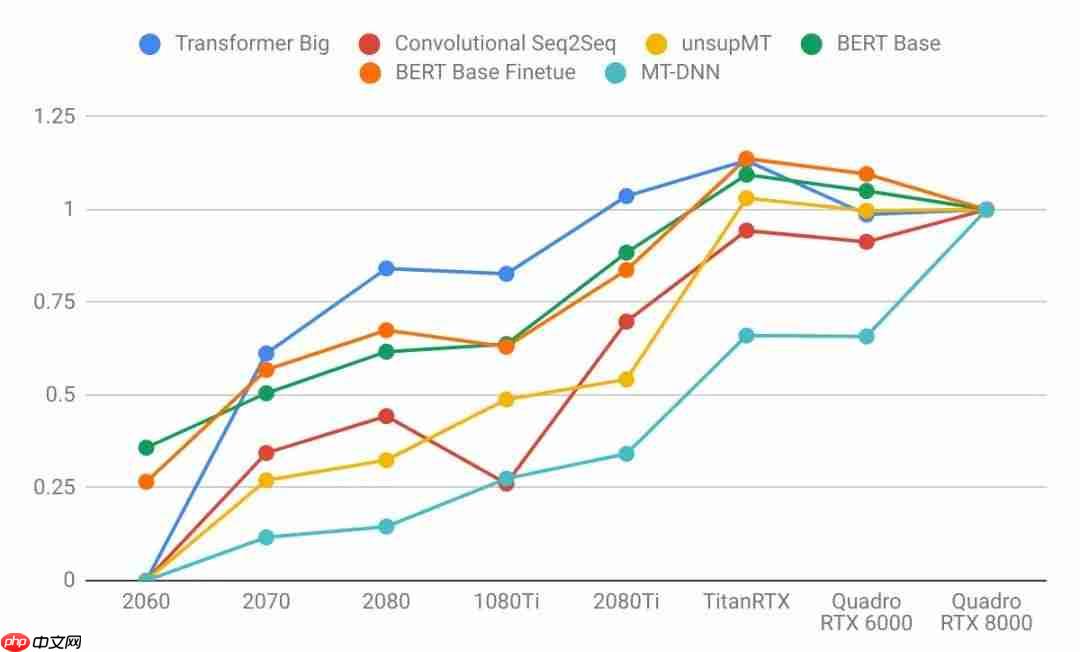 结论
结论
语言模型比图像模型更依赖于大容量的GPU内存。注意右图的曲线比左图更陡。这表明语言模型更受内存大小的限制,而图像模型更受计算能力的限制。具有较大VRAM的GPU性能更好,因为使用较大的批处理大小有助于CUDA内核饱和。具有更大VRAM的GPU可以按比例支持更大的批处理大小。即使是小学数学水平的人也能理解这一点:拥有24 GB VRAM的GPU可以比具有8 GB VRAM的GPU处理三倍大的批次。长序列语言模型不成比例地占用大量内存,因为注意力机制是序列长度的二次函数。GPU购买建议
RTX 2060(6 GB):适合业余时间探索深度学习。RTX 2070或2080(8 GB):适用于认真研究深度学习,但GPU预算在600-800美元之间。8 GB的VRAM适用于大多数模型。RTX 2080 Ti(11 GB):适用于认真研究深度学习且GPU预算约为1,200美元。RTX 2080 Ti比RTX 2080快大约40%。Titan RTX和Quadro RTX 6000(24 GB):适用于广泛使用现代模型,但没有足够的预算购买RTX 8000。Quadro RTX 8000(48 GB):适用于投资未来或研究2020年最新的酷炫模型。附注
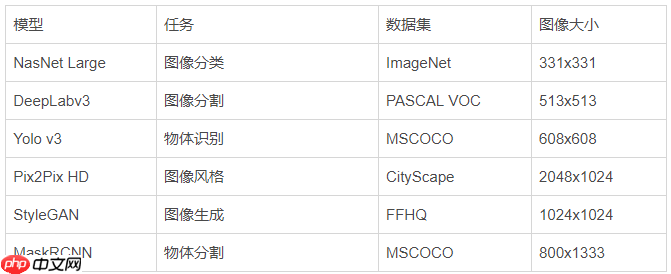
图像模型:
 语言模型:
语言模型:
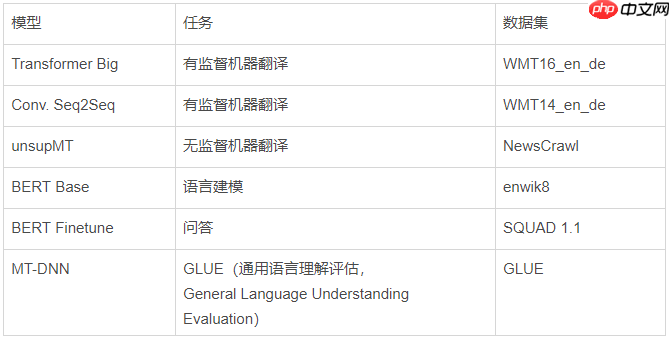 相关报道:
相关报道:
https://www.php.cn/link/c15e1bfe1ac5ed47bec025ca88301b3f
以上就是2020年深度学习最佳GPU一览,看看哪一款最适合你!的详细内容,更多请关注创想鸟其它相关文章!
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 chuangxiangniao@163.com 举报,一经查实,本站将立刻删除。
发布者:程序猿,转转请注明出处:https://www.chuangxiangniao.com/p/346987.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫