
centos关闭mysql的方法:1、通过“#chkconfig –list mysqld”命令查看MySQL服务;2、使用“mysqladmin -p -u root shutdown”命令关闭mysql即可。

本教程操作环境:centOS6.8系统、MySQL5.7版本、Dell G3电脑。
centos 怎么关闭mysql?
Centos下启动和关闭MySQL
1、Linux CentOS一般作为服务器使用,因此,MySQL服务器应该随机自启动。查看开机自启动的服务使用chkconfig命令,如下:
#chkconfig --list
或是只查看MySQL服务
#chkconfig --list mysqld
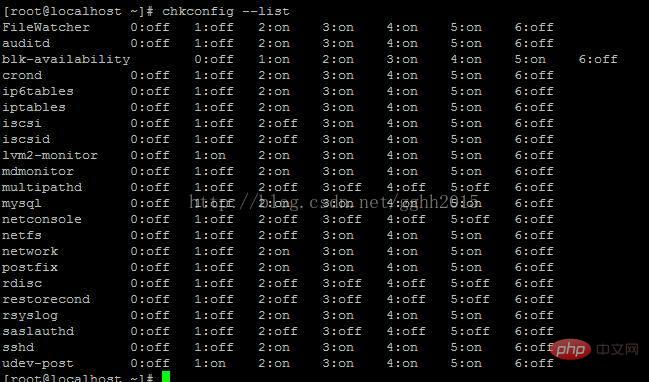
可以看到mysql的2~5为on,说明mysql服务会随机器启动而自动启动。
 H5+CSS3打开关闭灯泡开关动画特效
H5+CSS3打开关闭灯泡开关动画特效
H5+CSS3打开关闭灯泡开关动画特效
 82 查看详情
82 查看详情 
2、配置MySQL的开机自动启动
chkconfig --add mysqlchkconfig mysqld on
3、命令启动/关闭MySQL实例
service mysqld start/stop/etc/init.d/mysqld start/stop
4、命令关闭MySQL
mysqladmin -p -u root shutdown
5、检查mysql是否真正的启动
方法一:查询端口
#netstat -tulpn

MySQL监控的是TCP的3306端口,图中命令操作结果的最后一行即是MySQL服务在运行中。
方法二:查询进程
ps -ef | grep mysqld

如果有mysqld_safe和mysqld两个进程,说明MySQL服务当前在启动状态。
推荐学习:《MySQL视频教程》
以上就是centos 怎么关闭mysql的详细内容,更多请关注创想鸟其它相关文章!
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 chuangxiangniao@163.com 举报,一经查实,本站将立刻删除。
发布者:程序猿,转转请注明出处:https://www.chuangxiangniao.com/p/350268.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 



















