本篇文章主要从InnoDB数据存储结构的角度分析,在何种情况下,SQL查询效率会降低。经常在网上看到一些文章在吐槽,数据量大的情况下,查询效率会降低很多。表关联的多的时候,查询效率会降低。单表数据量不要超过百万等等。

数据库版本: 8.0引擎:InnoDB参考资料:掘金小册 《从根上理解Mysql》,有时间的建议亲自看一下。
样例表:
CREATE TABLE `hospital_info` ( `pk_id` bigint unsigned NOT NULL AUTO_INCREMENT COMMENT '主键', `id` varchar(36) NOT NULL COMMENT '外键', `hospital_code` varchar(36) NOT NULL COMMENT '医院编码', `hospital_name` varchar(36) NOT NULL COMMENT '医院名称', `is_deleted` tinyint DEFAULT NULL COMMENT '是否删除 0否 1是', `gmt_created` datetime DEFAULT NULL COMMENT '创建时间', `gmt_modified` datetime DEFAULT NULL COMMENT 'gmt_modified', `gmt_deleted` datetime(3) DEFAULT '9999-12-31 23:59:59.000' COMMENT '删除时间', PRIMARY KEY (`pk_id`), KEY `hospital_code` (`hospital_code`)) ENGINE=InnoDB AUTO_INCREMENT=2 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci COMMENT='医院信息';
InnoDB 行格式
从一行数据开始看起,先了解一下单行数据的存储格式。目前行格式有4种,分别是Compact、Redundant、Dynamic和Compressed行格式。在创建表的时候一般不需要刻意指定,5.7以上的版本会默认Dynamic。每种行格式大同小异,这里以Compact作为一个样例,简单的了解一下,每行数据是如何记录的。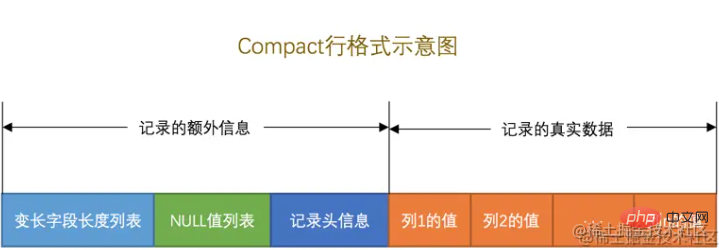
如上图所示。分为“额外信息”和“真实数据”两个部分。
变长字段列表
这个比较有意思,一般在定义字段的时候都需要指定字段的类型和长度,
比如:样例表中的hospital_code字段定义VARCHAR(36)。在实际使用中hospital_code字段长度只用了32位。
那剩下的4个字符长度会怎么办?若强行填充空字符,岂不是白白浪费4个字符的内存。若不填充,怎么判断当前字段到底保存了多少个字符?占用多少内存?
此时,变长字段列表就会按字段反序,用1~2个字节,记录每个变长字段实际的长度。这样可以有效的利用内存空间。
与之类似的字段:VARBINARY、各种TEXT类型,各种BLOB类型。
相对的也存在“定长字段”,比如:CHAR(10),该类型的字段,在初始化的时候就会默认占用指定字符长度的空间,若不够则填充空字符,因此对空间上是比较浪费的,一般建议按需设置长度。
当然“变长字段列表”不是必定存在的,若定义的字段类型没有“变长字段”则不会有。
拓展:对于TEXT或BLOB类型的字段,长度很可能一页无法存下,这时会将大部分数据记录在其他页中,在当前记录中保留下一页数据的地址。
NULL值列表
在实际保存数据的时候,某些列可能存储的是NULL值,如果这些值都记录在真实的数据中,则会浪费存储空间。在Compact格式中,会把这些值为NULL的列统一管理,存储到NULL值列表中。
若一行数据中,没有字段为NULL则不会产生此列。
存储的方式也比较有意思,是二进制方式倒序记录。
以样例表来分析,表中存在is_deleted、gmt_created、gmt_modified三个字段可能为空。假设在一条记录中gmt_created、gmt_modified都为空,那对应到NULL值列表中应该是下面的样子。
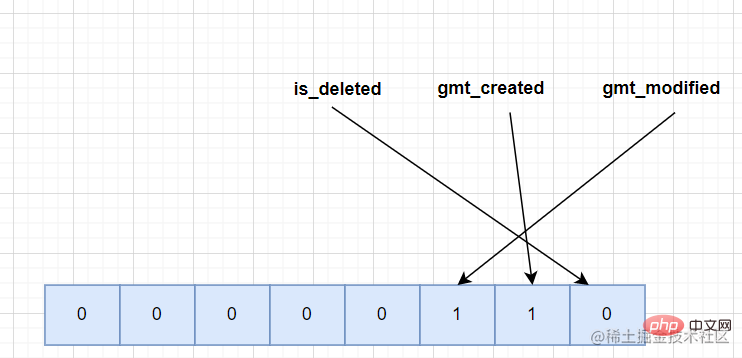
拓展:Mysql是支持二进制数据存储的,充分利用,可以减少很大的存储空间。
记录头信息
记录头信息由固定的5个字符组成,即40个二进制位长度。
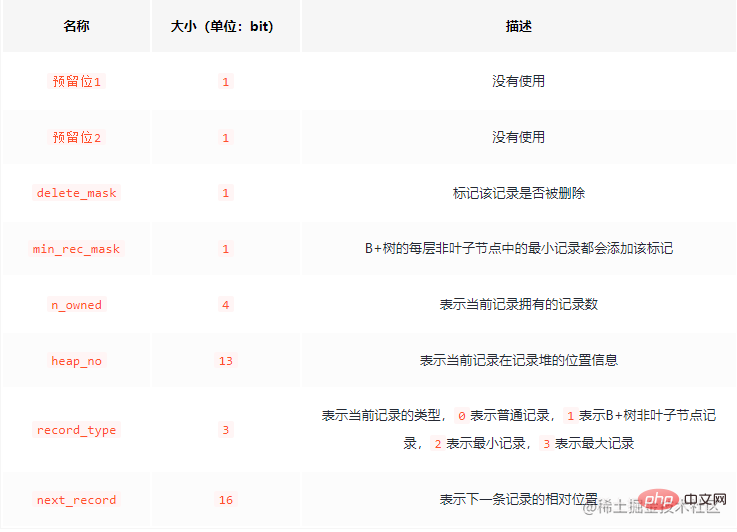
先作为一个了解,这里有一个比较有意思标识:delete_mask用过redis的都知道,redis的中被删除的数据不会被立刻清除,相同的mysql中也一样,被删除的数据不会立刻被清理,因为清理的过程会引发IO操作,这是很影响效率的。被删除的数据会组成一个链表,想当与一个可复用的空间。
记录真实数据数据
这个其实没啥好说的,就是记录真实的非NULL数据。
有一个网上经常能看到的问题:若没有设置主键会怎样?
InnoDB下,主键是一条记录的唯一标识,如果用户没有指定,mysql会从Unique(唯一)键中选取一个作为主键,如果没有Unique键,则会添加一个名为row_id隐藏列,作为主键。
此外还会添加添加 transaction_id(事务ID) 和 roll_pointer(回滚指针) 这两个列。
小结
4种行格式大同小异,就不一一介绍了,都分为“额外信息”和“真实数据”两个部分。区别主要在与“额外信息”记录的内容,以及变长字段的保存上的些许不同。
InnoDB数据页
数据页的概念,相信已经耳熟能详了。它是InnoDB管理存储空间的基本单位,单页大小一般是16KB。根据不同的目的设计了许多不同类型的页,如:存放表空间头部信息的页,存放Insert Buffer信息的页,存放INODE信息的页,存放undo日志信息的页等等。
页空间划分如下: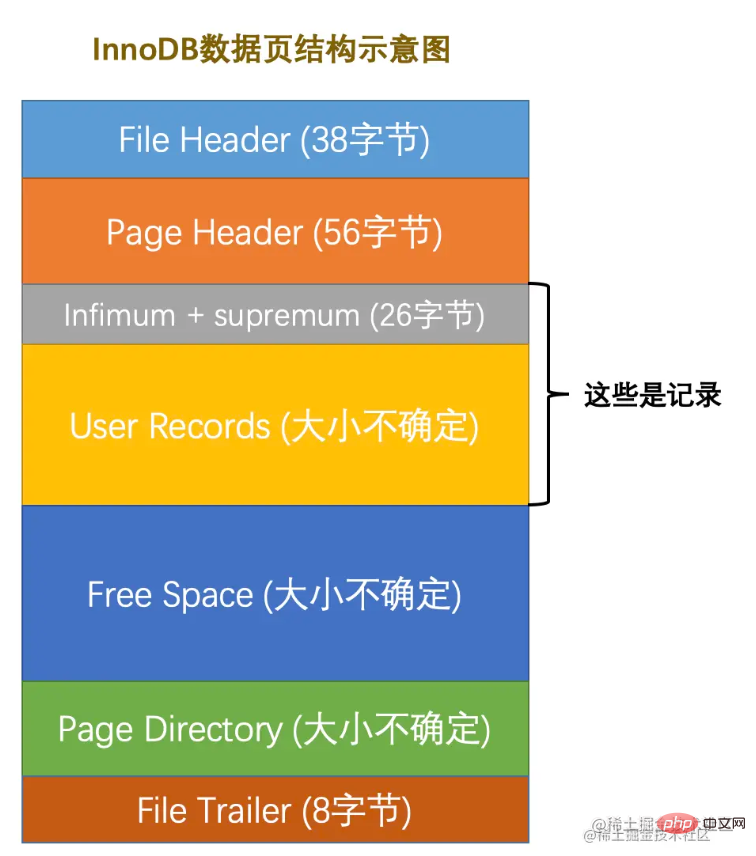
总共7个组成部分,大致描述一下7个部分。
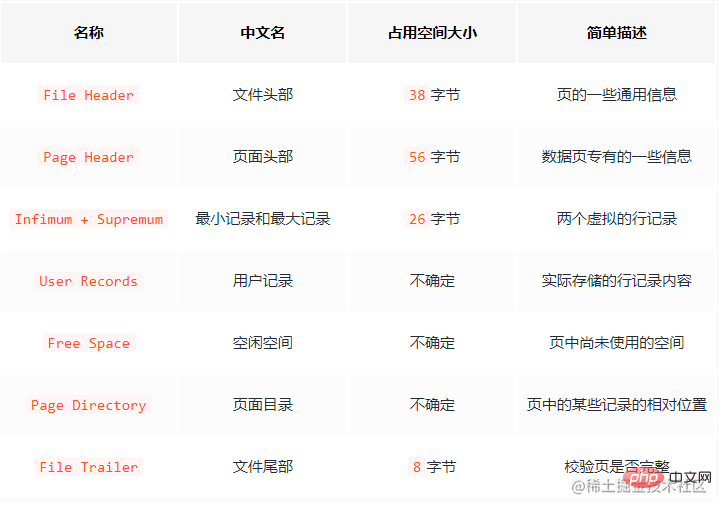
其中File header和Page header中的属性非常多,这里不一一介绍,只要知道这两个地方记录页的一些属性,比如:页号,上一页和下一页的页号,页的类型,以及页的内存占用等等。这里说一下,页与页之间是双向链表进行连接的。数据记录是单项链表。
File Trailer是校验页数据完整性的,当页数据从内存重新写入磁盘的时候需要校验,防止数据页损坏。
重点关注下User Records(已用空间)和Free Space(剩余空间),这里是保存真实的数据记录。
此外 Infimum 和 Supremum,分别标识最小记录和最大记录。即一个页产生的时候,就默认包含这两条记录,不过不用担心这两条记录只是作为数据链表的头和尾,不影响真实数据。
综上,记录在页中的存储如下:
 即构数智人
即构数智人
即构数智人是由即构科技推出的AI虚拟数字人视频创作平台,支持数字人形象定制、短视频创作、数字人直播等。
 36 查看详情
36 查看详情 
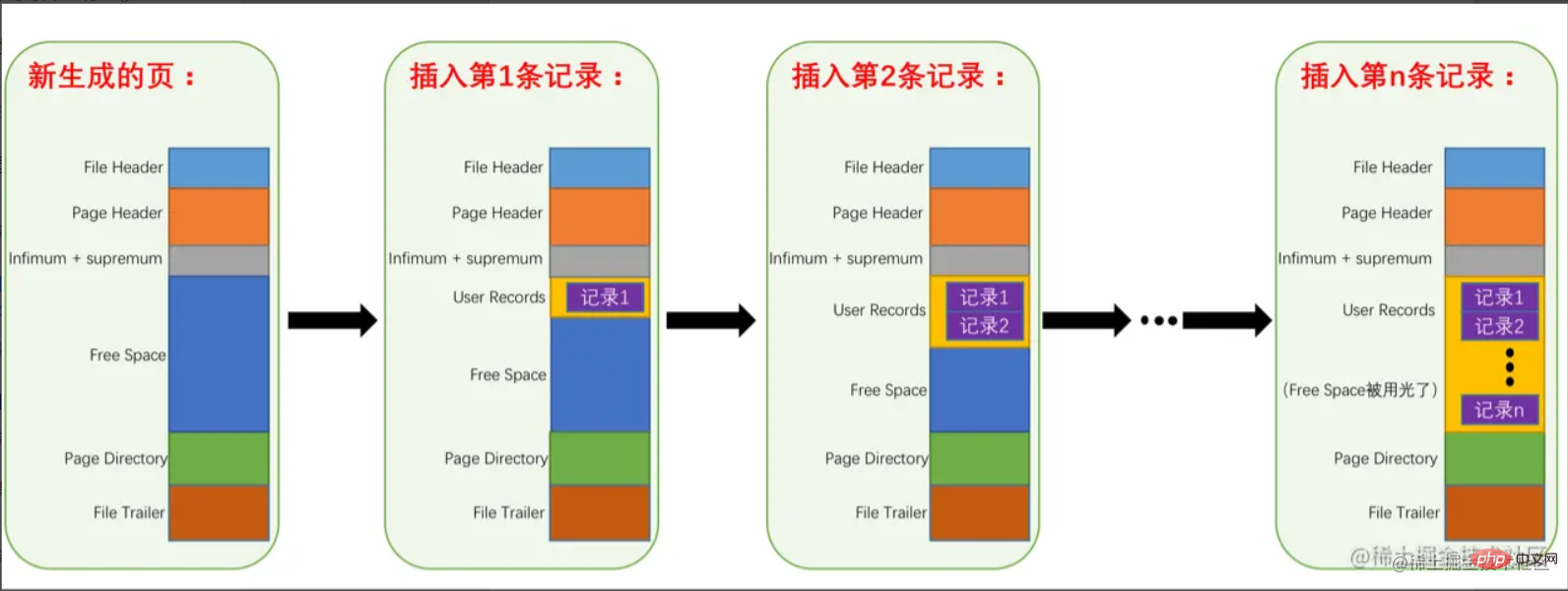 简单的来说,就是Free Space到User Records的转化,当Free Space耗尽时则视为数据页已经满了。
简单的来说,就是Free Space到User Records的转化,当Free Space耗尽时则视为数据页已经满了。
到此,数据已经写入了数据页中。那该怎么取出呢?上面知道了数据记录是单项链表组成的,难道要从Infimum(最小)记录开始沿着链表遍历吗?
显然,mysql的开发大佬不可能这么蠢,否则我上我也行,哈哈。
这里就要提到 Page Directory(页目录)了。在页中,对数据进行了分组,每组最后一条记录的地址偏移量单独提取出来按顺序存储到靠近页尾的“页目录”中,页目录中的这些地址偏移量被称为“槽”,此外最后一条记录头部(n_owned)还要保存所在分组中有多少条记录。
页目录是由一个个的槽组成的。整体结构图如下:
有了目录之后,查询就比较简单了。可以使用二分法进行快查。上图中,知道最小槽为0,最大为4.举个栗子:
假设要查询主键记录为6的数据。
1)计算中间槽位置即(0+4)/ 2 = 2。取出槽对应的记录主键为8,因为8>6。
2)同理,将最大的槽设置为2,即(0+2)/2 =1,槽1对应的主键为4,因为 4 < 6, 所以可以确定数据就在槽2中。
为了方便后续的描述,将页的数据形式简化为如下图所示的样子。
B+树索引
不妨思考一个问题,前面说了。数据页之间使用的是双向链表链接的,大致如下图所示: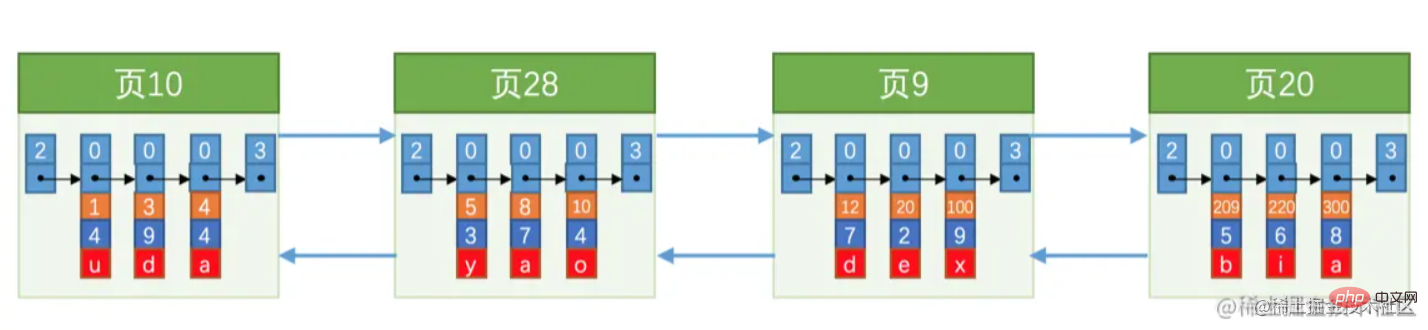 上图可以看能出页号并非连续的,也并不一定是连续的内存空间(记住这句话后面会说到)。
上图可以看能出页号并非连续的,也并不一定是连续的内存空间(记住这句话后面会说到)。
假设每页能存放3条记录,现在有10w条记录需要保存,则需要3w多个数据页,此时会面对和单页数据过多一样的查询问题,总不能逐个遍历吧。此时也需要一个能快速快查询的目录,这个目录就是“索引”。
在上图所示的数据页基础上,可以形成如下的索引结构: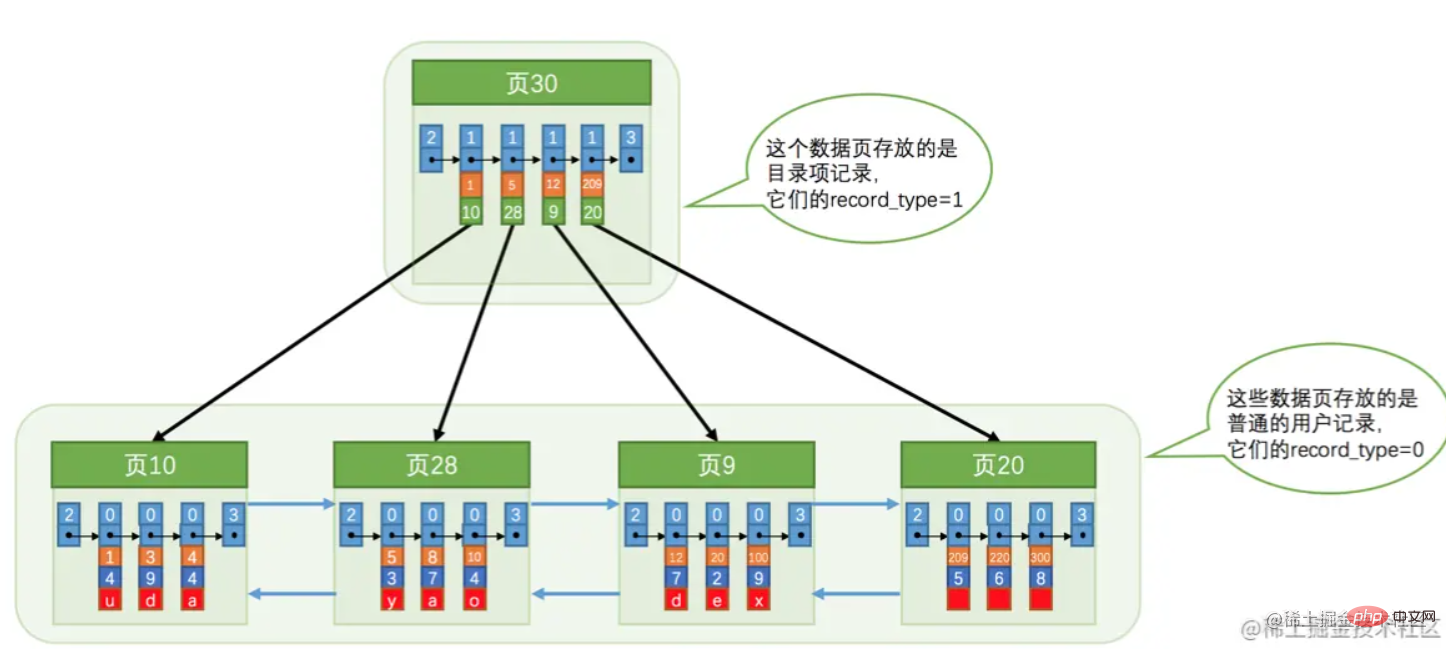 这种就是常说的聚簇索引,叶子即数据。这里要注意的一点,“页30”中存放的是主键以及其所在的页号。如果说单个索引页满了,则会进行分裂。产生如下所示的树形结构。
这种就是常说的聚簇索引,叶子即数据。这里要注意的一点,“页30”中存放的是主键以及其所在的页号。如果说单个索引页满了,则会进行分裂。产生如下所示的树形结构。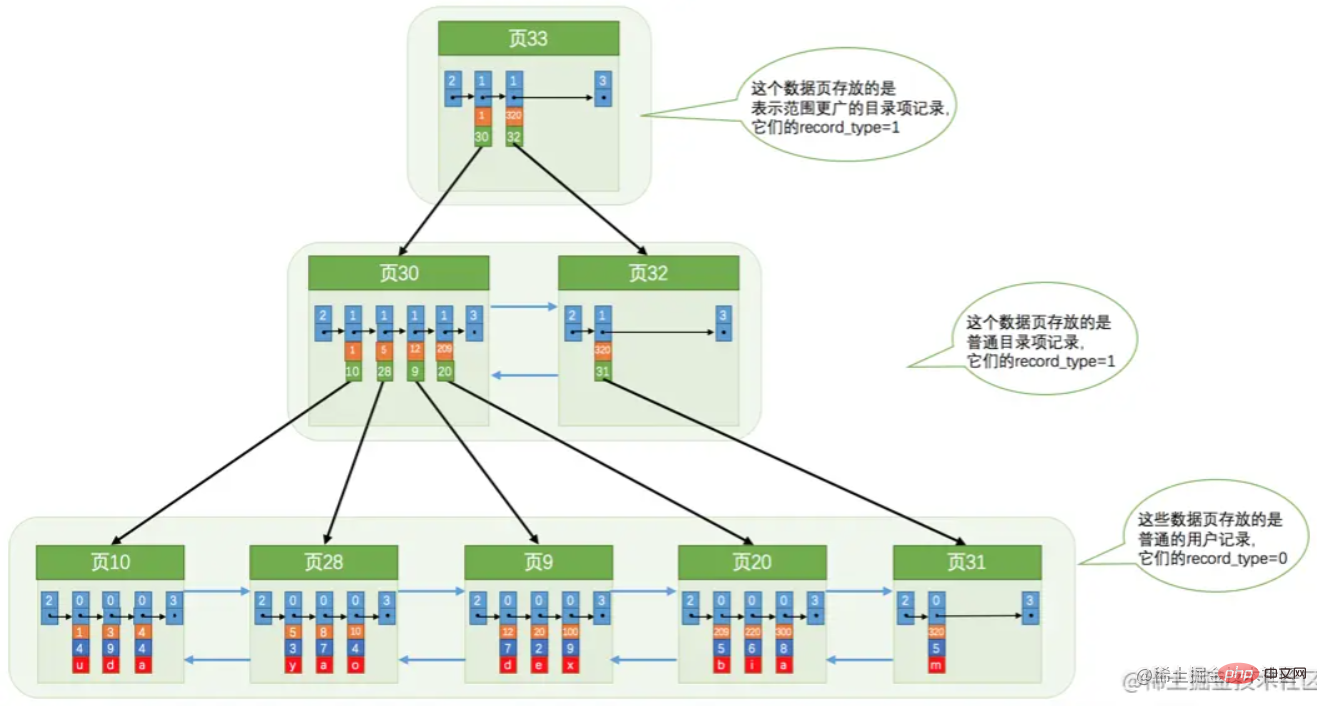 不过上图为了标识方便,是不完全准确的。应该是先产生一个根节点,当根节点满了,则会进行分裂。根节点则记录分裂后的索引页信息。
不过上图为了标识方便,是不完全准确的。应该是先产生一个根节点,当根节点满了,则会进行分裂。根节点则记录分裂后的索引页信息。
简单的来说就跟树木成长一样,先从根再到树干、树枝、树叶等。
二级索引与聚簇索引的思路是一样的,差别在于二级索引的叶子节点不是真实数据,而是数据的主键。需要进行回表操作才能获取真实数据。
表空间
到目前为止,已经知道单条数据的存储结构,以及最小的存储数据单元页。数据页之间通过双向链表进行连接,并且数据页之间是不一定连续的。
此时,产生了一个问题,同一个表的记录,如果所在的页在内存地址上相距过远怎么办?设想一下为了找3个人,他们分别再北京、纽约、伦敦。你要挨个去找,中间要浪费大量的时间在旅途中。如果把他们聚集在一个国家,甚至一个城市,那就要快很多。
于是区的概念诞生了。区是由连续的64个页组成,默认情况下一个区占用1M的内存。在申请内存的时候,一次性占用1M的空间,其中的数据页都是相邻的,一定程度上解决了随机IO的问题。
在区的基础上,为了更有效的提升查询效率,将B+树的叶子节点和非叶子节点记录在不同的区中,这些区的集合被成为“段(segment)”。在此概念下,插入第一条记录,就需要申请2个区空间,一个聚簇索引根节点,一个数据页,这一次就需要申请2M的空间!啥也没干呢,2M空间就没了,这合理吗?显然,这很不合理。
因此又搞出一个”碎片区“的概念。碎片区直属于表空间,不属于任何一个段。分配内存的流程转变成:
1)刚开始插入数据时,从碎片区以单个页面来分配存储空间。
2)当某个段已经占用了32个碎片区页面后,就会以完整的区来分配空间。
表空间还分为:系统表空间和独立表空间,此外还有区的XDES Entry数据结构。内容过多且复杂,需要了解的可以去看原书。
思考
1)索引越多越好吗?多了会有 什么影响?
那肯定不是越多越好,上面可以知道,索引的记录也是需要内存损耗的。每个索引都会对应一个B+树,每个树有需要2个段分别记录叶子节点和非叶子节点。这么下来会带来很多内存的浪费。仅仅是这样的话也不是不能接受,毕竟索引本身的意义就是用空间换时间。但我们要知道,数据的增删改,会导致索引的变化,需要索引重新分配节点,以及页内存的回收分配。这些都是IO操作,若索引过多,势必导致性能的降低。
因此合理的利用联合索引,可以解决单个索引过多的问题。此外索引有长度限制,过长的字段不适合作为索引。
2)索引为何查询效率这么高?
这个其实属于算法问题,以聚簇索引为例,假设非叶子节点的索引页,每个能记录1000条数据,叶子节点每个能记录500条数据,一个3层的B+树(不算根节点),能存放10001000500条记录。一个3层结构的索引能存放这么多记录,每次只需几次查询就能定位数据,效率自然也就高了。
实际上单个索引页所能记录的数据要比这大的多。
同样的这里可以思考一个问题,若叶子节点中的单条数据非常大,大到一个数据页只能存放3条记录,这时B+树的深度就会增加,因此合理的减少表中单条记录的大小,也是一种优化。
3)数据量大,sql会执行缓慢?
其实这个问题真的很想吐槽,动不动就百万数据查询效率xx秒,太慢了。不否认mysql的性能的确弱于一些数据库,但是百万的数据量就慢的,想想自己的SQL和表结构设计是否合理。别说百万级,就是千万级的也能实现毫秒级的查询。只谈数量都是扯淡,要实际看看锁占用的内存大小,若你的表中有上百个字段,或者存在字符超长的字段。那么神仙也救不了你。
总结
文章主要是介绍MySql数据结构的概念,大部分内容都来自于《从根上理解Mysql》一书。做了很多简化,可以作为基础了解一些概念。
如有错漏,感谢指正。
【相关推荐:mysql视频教程】
以上就是浅析MySQL中的数据存储结构的详细内容,更多请关注创想鸟其它相关文章!
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 chuangxiangniao@163.com 举报,一经查实,本站将立刻删除。
发布者:程序猿,转转请注明出处:https://www.chuangxiangniao.com/p/350985.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫