
aixiv专栏长期致力于分享学术和技术前沿内容,已发表2000余篇来自全球顶尖高校和企业实验室的文章,为学术交流和传播做出了重要贡献。欢迎各位专家学者投稿或联系报道,投稿邮箱:liyazhou@jiqizhixin.com;zhaoyunfeng@jiqizhixin.com
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

大语言模型的广泛应用带来了大规模推理的巨大挑战。传统注意力机制中的键值缓存(KV Cache)随着批处理大小和序列长度线性增长,成为限制大模型规模化应用和推理效率的瓶颈。
虽然MQA、GQA、MLA等改进方案已出现,但它们或难以在严格的显存限制下保持性能,或引入额外的复杂度,造成工程难题和兼容性问题。
阶跃星辰、清华大学等机构近期发表的论文《Multi-matrix Factorization Attention》提出了一种新型注意力机制——多矩阵分解注意力(MFA)及其变体MFA-Key-Reuse(MFA-KR)。该方法在显著降低推理成本的同时,提升了模型性能。

论文链接:https://www.php.cn/link/aac8f7d518e4300ab8031d6709164f1d
实验表明,MFA和MFA-KR不仅性能超越MLA,而且在KV Cache使用量减少高达93.7%的情况下,性能与传统MHA相当。MFA易于实现和复现,对超参数不敏感,并兼容各种位置编码。
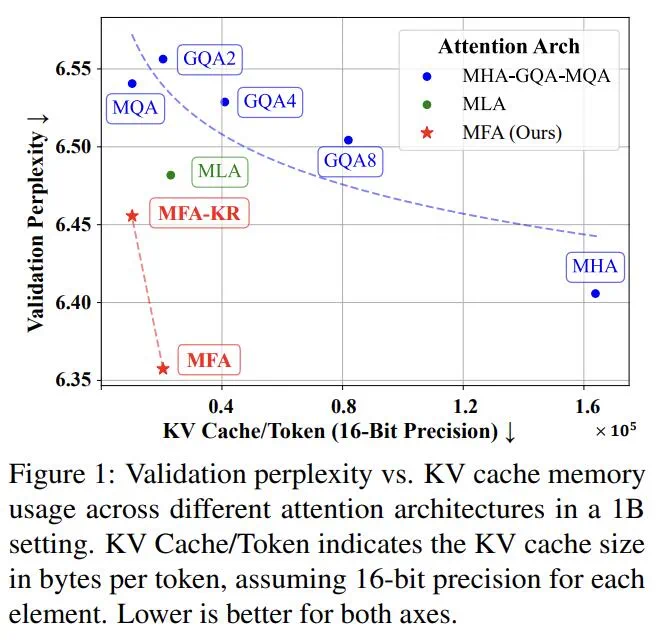
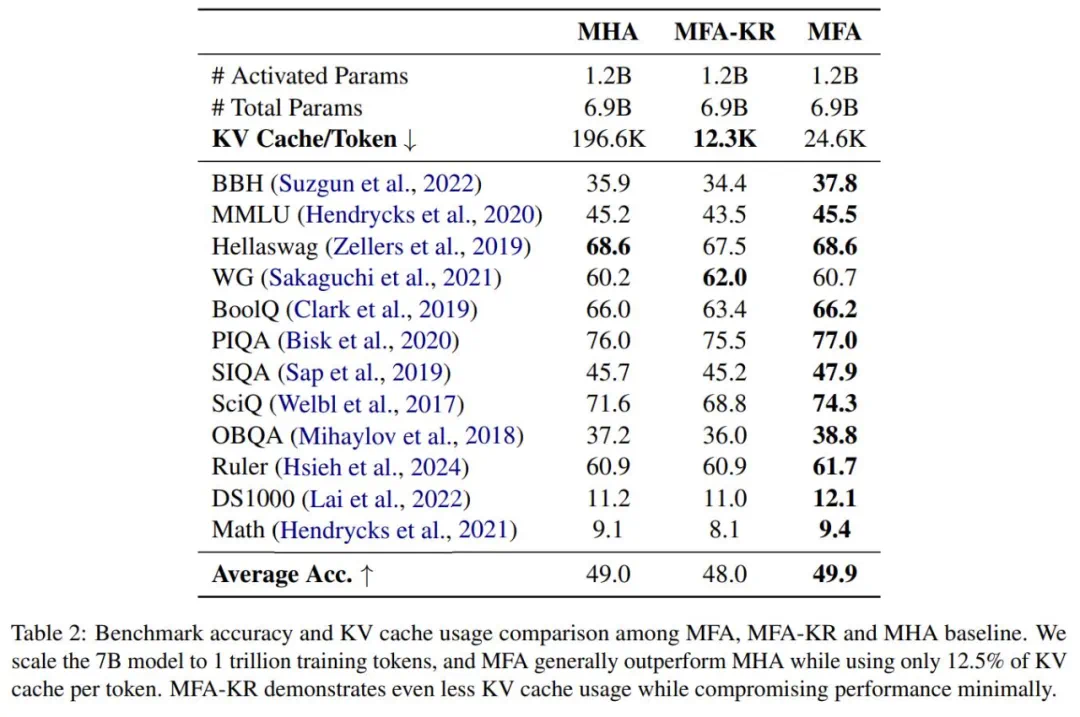
MFA方法及分析
研究团队通过对注意力机制的容量分析,确定了影响其容量的关键维度,并提出了一系列分析方法和设计原则。
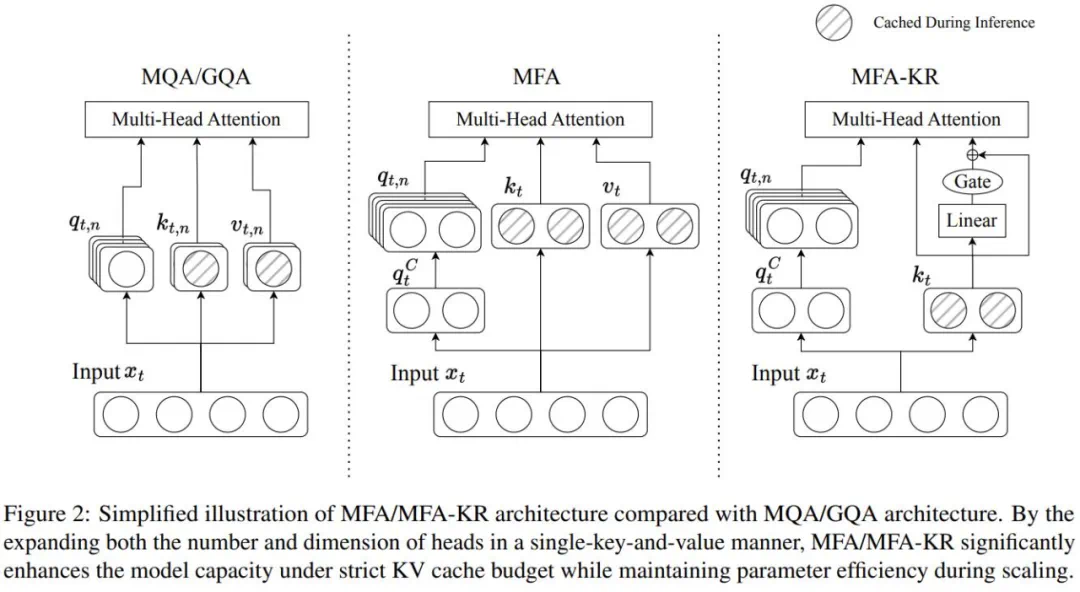
研究团队提出了广义多头注意力(GMHA)框架,统一理解不同MHA变体。他们从推理角度研究键值的计算和存储,从分解角度探讨模型容量特征,为理解不同策略的权衡提供了新视角。
研究团队将完全参数化双线性注意力(FPBA)作为理论性能上限,发现现有MHA及其变体都是FPBA的低秩分解版本。他们分析了MQA和MLA两种代表性改进方案:MQA采用激进的参数共享策略,降低内存使用但可能影响表达能力;MLA引入共享潜在空间,但表达能力受限于最小维度。
 阶跃AI
阶跃AI
阶跃星辰旗下AI智能问答搜索助手
 291 查看详情
291 查看详情 
基于以上分析,研究团队提出了MFA,旨在最大限度地节省资源并接近理论性能上限。MFA的三个关键创新:突破传统设计限制,增加注意力头的数量和维度;采用创新的低秩分解策略,提高参数效率;采用单键值头设计,降低内存使用。
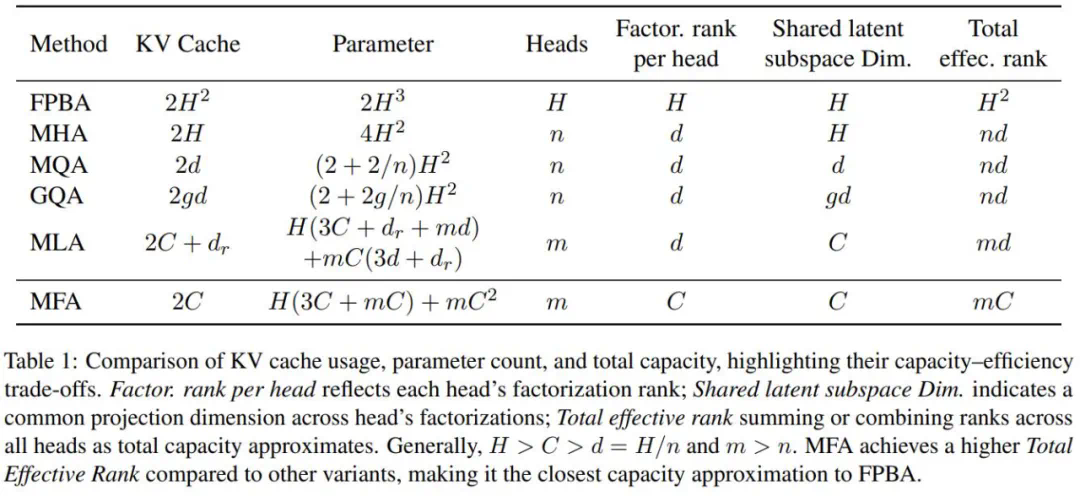
为了对比MFA和其他注意力机制,研究团队引入了两个关键指标:模型总有效秩TER和共享隐空间维度SLSD。TER越高,模型容量越高;SLSD代表所有注意力头共同使用的隐空间维度。KV Cache占用受制于FRH和SLSD中的较大值。
分析表明,MFA在参数预算下比MQA拥有更高的SLSD和TER;比MLA拥有更小的KV Cache尺寸和更高的TER,同时保持相当的SLSD;比MHA拥有更高的TER,解释了其性能优势。
实验结果
研究团队进行了大规模扩展性实验(1B到7B参数,10B到1T训练数据),MFA展现出与传统MHA相当的扩展能力。MFA和MFA-KR在内存节省方面优势显著,最大规模模型上分别实现87.5%和6.25%的内存节省。
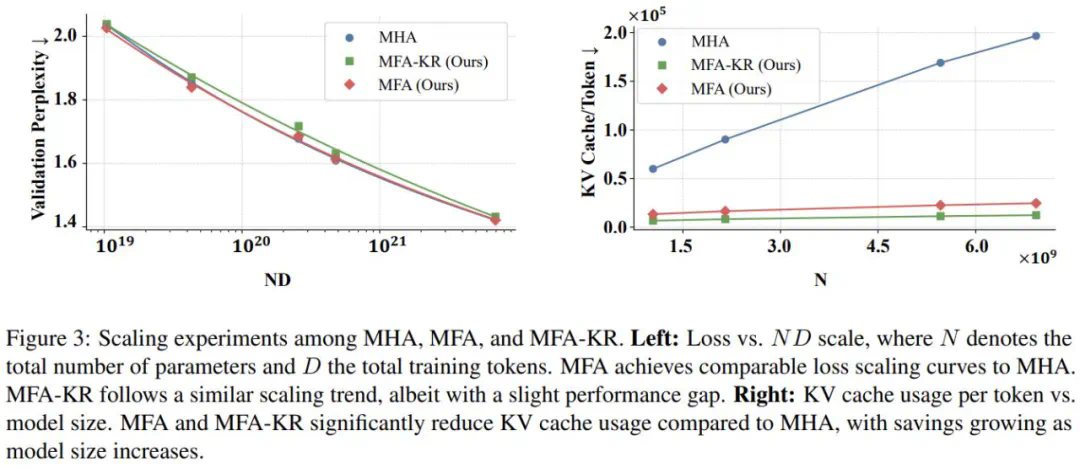
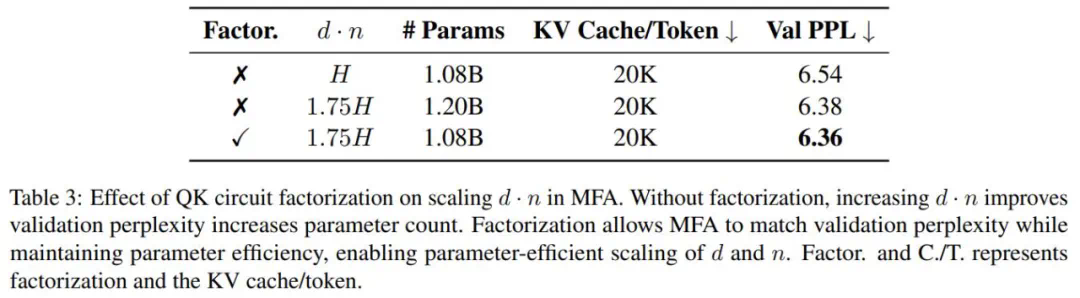
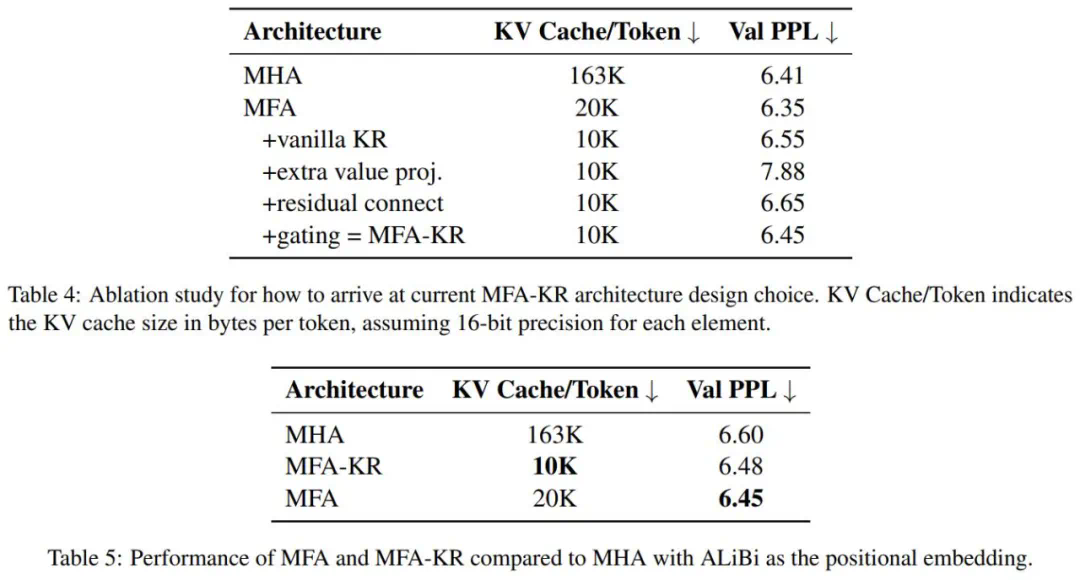
消融实验验证了MFA和MFA-KR设计的有效性,并在其他主流位置编码上也验证了其性能优势。
展望
MFA以简洁的设计解决了LLM高效推理的显存瓶颈问题,并能无缝集成到现有Transformer生态中。这项创新将加速大语言模型的应用。
以上就是阶跃公开了自家新型注意力机制:KV缓存消耗直降93.7%,性能不减反增的详细内容,更多请关注创想鸟其它相关文章!
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 chuangxiangniao@163.com 举报,一经查实,本站将立刻删除。
发布者:程序猿,转转请注明出处:https://www.chuangxiangniao.com/p/363315.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 






















