
本文提出了一个简单的 MLP-like 的架构 CycleMLP,它是视觉识别和密集预测的通用主干,不同于现代 MLP 架构,例如 MLP-Mixer、ResMLP 和 gMLP,其架构与图像大小相关,因此是在目标检测和分割中不可行。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

1. 简介
这是一个PaddlePaddle实现的CycleMLP。
本文提出了一个简单的 MLP-like 的架构 CycleMLP,它是视觉识别和密集预测的通用主干,不同于现代 MLP 架构,例如 MLP-Mixer、ResMLP 和 gMLP,其架构与图像大小相关,因此是在目标检测和分割中不可行。
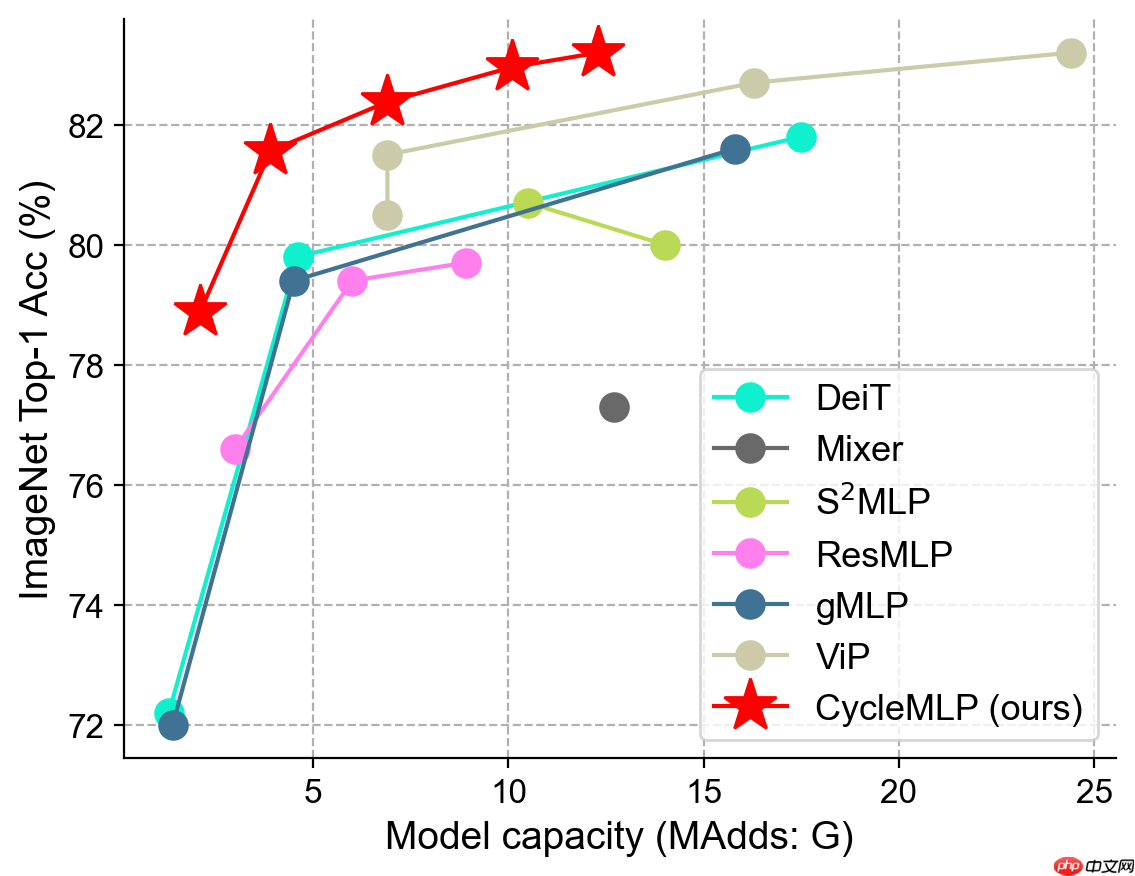
论文: CycleMLP: A MLP-like Architecture for Dense Prediction
参考repo: CycleMLP
在此非常感谢ShoufaChen贡献的CycleMLP,提高了本repo复现论文的效率。
2. 数据集和复现精度
数据集为ImageNet,训练集包含1281167张图像,验证集包含50000张图像。
│imagenet/├──train/│ ├── n01440764│ │ ├── n01440764_10026.JPEG│ │ ├── n01440764_10027.JPEG│ │ ├── ......│ ├── ......├──val/│ ├── n01440764│ │ ├── ILSVRC2012_val_00000293.JPEG│ │ ├── ILSVRC2012_val_00002138.JPEG│ │ ├── ......│ ├── ......
您可以从ImageNet 官网申请下载数据。
CycleMLP-B10.7890.790checkpoint-best.pd | train.log
权重及训练日志下载地址:百度网盘
3. 准备数据与环境
3.1 准备环境
硬件和框架版本等环境的要求如下:
硬件:4 * RTX3090框架:PaddlePaddle >= 2.2.0安装paddlepaddle
# 需要安装2.2及以上版本的Paddle,如果# 安装GPU版本的Paddlepip install paddlepaddle-gpu==2.2.0# 安装CPU版本的Paddlepip install paddlepaddle==2.2.0
更多安装方法可以参考:Paddle安装指南。
下载代码In [ ]
%cd /home/aistudio!git clone https://github.com/flytocc/CycleMLP-paddle.git
安装requirementsIn [ ]
%cd /home/aistudio/CycleMLP-paddle!pip install -r requirements.txt
3.2 准备数据
如果您已经ImageNet1k数据集,那么该步骤可以跳过,如果您没有,则可以从ImageNet官网申请下载。
4. 复现思路
4.1 使用paddle api实现模型结构
CycleFC模块
与现代方法相比,CycleMLP 有两个优势。
(1) 可以应对各种图像尺寸。
(2) 利用局部窗口实现对图像大小的线性计算复杂度。
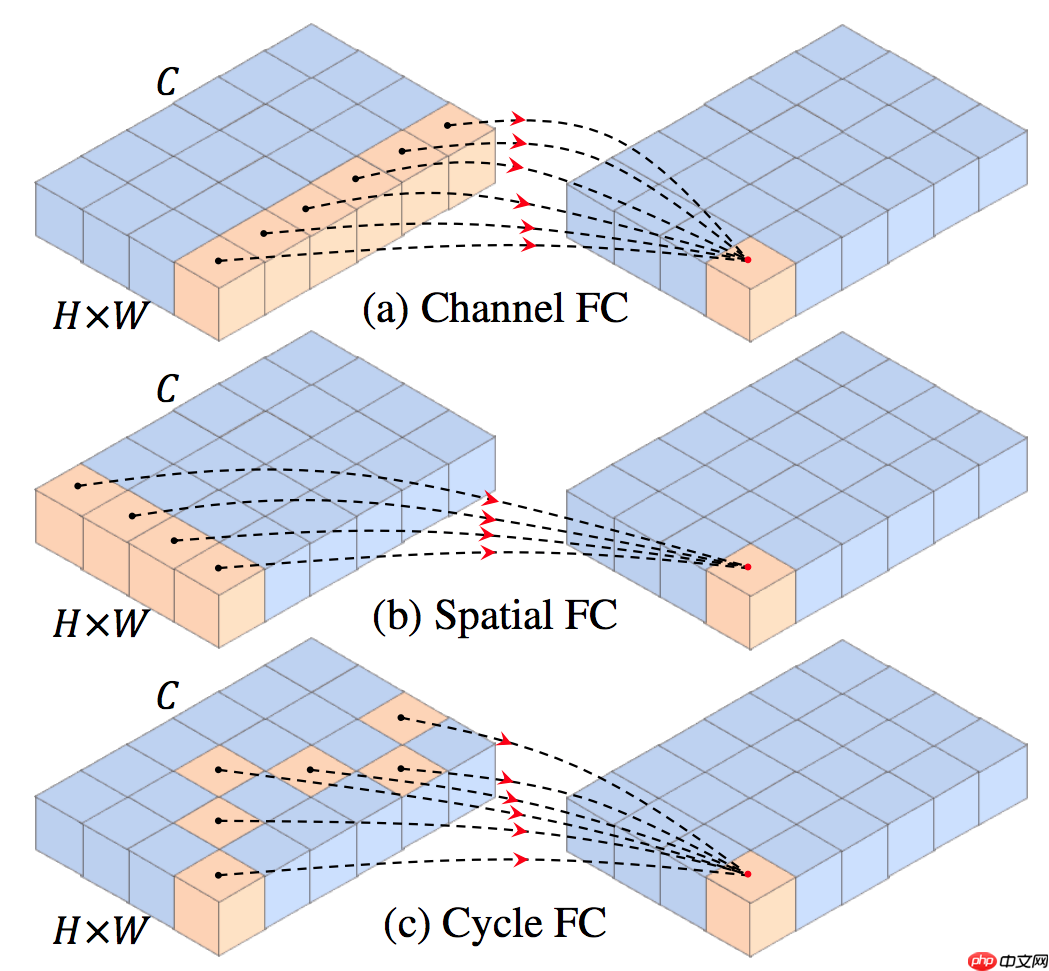
class CycleFC(nn.Layer): def __init__( self, in_channels: int, out_channels: int, kernel_size, # re-defined kernel_size, represent the spatial area of staircase FC stride: int = 1, padding: int = 0, dilation: int = 1, groups: int = 1, bias: bool = True, ): super(CycleFC, self).__init__() if in_channels % groups != 0: raise ValueError('in_channels must be divisible by groups') if out_channels % groups != 0: raise ValueError('out_channels must be divisible by groups') if stride != 1: raise ValueError('stride must be 1') if padding != 0: raise ValueError('padding must be 0') self.in_channels = in_channels self.out_channels = out_channels self.kernel_size = kernel_size self.stride = to_2tuple(stride) self.padding = to_2tuple(padding) self.dilation = to_2tuple(dilation) self.groups = groups self.deformable_groups = self.in_channels self.weight = self.create_parameter( shape=[out_channels, in_channels // groups, 1, 1]) # kernel size == 1 if bias: self.bias = self.create_parameter(shape=[out_channels]) else: self.bias = None self.register_buffer('offset', self.gen_offset()) def gen_offset(self): """ offset (Tensor[batch_size, 2 * offset_groups * kernel_height * kernel_width, out_height, out_width]): offsets to be applied for each position in the convolution kernel. """ offset = paddle.empty([1, self.in_channels * 2, 1, 1]) start_idx = (self.kernel_size[0] * self.kernel_size[1]) // 2 assert self.kernel_size[0] == 1 or self.kernel_size[1] == 1, self.kernel_size for i in range(self.in_channels): if self.kernel_size[0] == 1: offset[0, 2 * i + 0, 0, 0] = 0 offset[0, 2 * i + 1, 0, 0] = (i + start_idx) % self.kernel_size[1] - (self.kernel_size[1] // 2) else: offset[0, 2 * i + 0, 0, 0] = (i + start_idx) % self.kernel_size[0] - (self.kernel_size[0] // 2) offset[0, 2 * i + 1, 0, 0] = 0 return offset def forward(self, input): """ Args: input (Tensor[batch_size, in_channels, in_height, in_width]): input tensor """ B, C, H, W = input.shape return deform_conv2d(input, self.offset.expand([B, -1, H, W]), self.weight, bias=self.bias, stride=self.stride, padding=self.padding, dilation=self.dilation, deformable_groups=self.deformable_groups)
构建CycleMLP模块
class CycleMLP(nn.Layer): def __init__(self, dim, qkv_bias=False, qk_scale=None, attn_drop=0., proj_drop=0.): super().__init__() self.mlp_c = nn.Linear(dim, dim, bias_attr=qkv_bias) self.sfc_h = CycleFC(dim, dim, (1, 3), 1, 0) self.sfc_w = CycleFC(dim, dim, (3, 1), 1, 0) self.reweight = Mlp(dim, dim // 4, dim * 3) self.proj = nn.Linear(dim, dim) self.proj_drop = nn.Dropout(proj_drop) def forward(self, x): B, H, W, C = x.shape h = self.sfc_h(x.transpose([0, 3, 1, 2])).transpose([0, 2, 3, 1]) w = self.sfc_w(x.transpose([0, 3, 1, 2])).transpose([0, 2, 3, 1]) c = self.mlp_c(x) a = (h + w + c).transpose([0, 3, 1, 2]).flatten(2).mean(2) a = self.reweight(a).reshape([B, C, 3]).transpose([2, 0, 1]) a = F.softmax(a, axis=0).unsqueeze(2).unsqueeze(2) x = h * a[0] + w * a[1] + c * a[2] x = self.proj(x) x = self.proj_drop(x) return x
5.2 确定训练超参
参考论文及official code,主要超参如下:
10241e-3300
5. 开始使用
5.1 模型预测

In [ ]
%cd /home/aistudio/CycleMLP-paddle%run infer.py --model=CycleMLP_B1 --infer_imgs=/home/aistudio/CycleMLP-paddle/demo/ILSVRC2012_val_00020010.JPEG --resume=/home/aistudio/CycleMLP_B1.pdparams
最终输出结果为
[{'class_ids': [178, 211, 209, 210, 246], 'scores': [0.9213957190513611, 0.006610415875911713, 0.0018257270567119122, 0.0013606979046016932, 0.001132593140937388], 'file_name': '/home/aistudio/CycleMLP-paddle/demo/ILSVRC2012_val_00020010.JPEG', 'label_names': ['Weimaraner', 'vizsla, Hungarian pointer', 'Chesapeake Bay retriever', 'German short-haired pointer', 'Great Dane']}]
表示预测的类别为Weimaraner(魏玛猎狗),ID是178,置信度为0.9213957190513611。
5.2 模型训练
单机多卡训练
export CUDA_VISIBLE_DEVICES=0,1,2,3python -m paddle.distributed.launch --gpus="0,1,2,3" main.py --model=CycleMLP_B1 --batch_size=256 --data_path=/path/to/imagenet/ --output_dir=./output/ --dist_eval
部分训练日志如下所示。
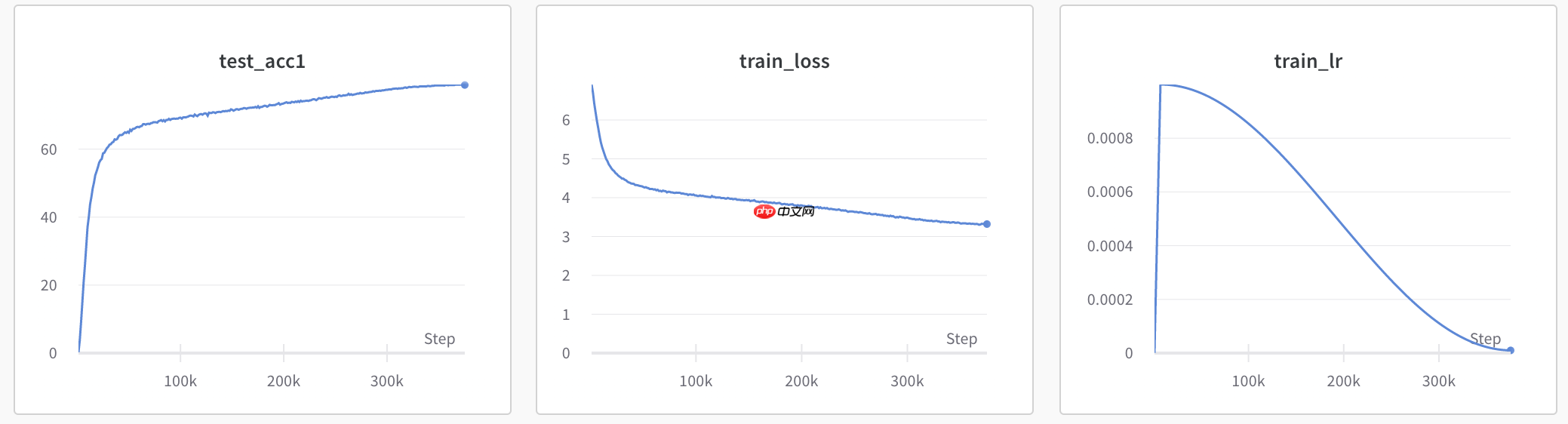
[16:56:29.233819] Epoch: [261] [ 920/1251] eta: 0:05:50 lr: 0.000052 loss: 3.4592 (3.3812) time: 1.0303 data: 0.0012[16:56:49.578909] Epoch: [261] [ 940/1251] eta: 0:05:29 lr: 0.000052 loss: 3.7399 (3.3853) time: 1.0171 data: 0.0015
5.3 模型评估
export CUDA_VISIBLE_DEVICES=0,1,2,3python -m paddle.distributed.launch --gpus="0,1,2,3" eval.py --model=CycleMLP_B1 --batch_size=256 --data_path=/path/to/imagenet/ --dist_eval --resume=$TRAINED_MODEL
5.4 模型导出
python export_model.py --model=CycleMLP_B1 --output_dir=./output/ --resume=$TRAINED_MODEL
6. 代码结构
├── cycle_mlp.py├── demo├── engine.py├── eval.py├── export_model.py├── infer.py├── main.py├── README.md├── requirements.txt├── test_tipc└── util
7. 自动化测试脚本
详细日志在test_tipc/output
TIPC: test_tipc/README.md
首先安装auto_log,需要进行安装,安装方式如下: auto_log的详细介绍参考https://github.com/LDOUBLEV/AutoLog。
git clone https://github.com/LDOUBLEV/AutoLogcd AutoLog/pip3 install -r requirements.txtpython3 setup.py bdist_wheelpip3 install ./dist/auto_log-1.2.0-py3-none-any.whl
进行TIPC:
bash test_tipc/prepare.sh test_tipc/config/CycleMLP/CycleMLP_B1.txt 'lite_train_lite_infer'bash test_tipc/test_train_inference_python.sh test_tipc/config/CycleMLP/CycleMLP_B1.txt 'lite_train_lite_infer'
TIPC结果:
如果运行成功,在终端中会显示下面的内容,具体的日志也会输出到test_tipc/output/文件夹中的文件中。
Run successfully with command - python3.7 eval.py --model=CycleMLP_B1 --data_path=./dataset/ILSVRC2012/ --cls_label_path=./dataset/ILSVRC2012/val_list.txt --resume=./test_tipc/output/norm_train_gpus_0_autocast_null/CycleMLP_B1/checkpoint-latest.pd !Run successfully with command - python3.7 export_model.py --model=CycleMLP_B1 --resume=./test_tipc/output/norm_train_gpus_0_autocast_null/CycleMLP_B1/checkpoint-latest.pd --output=./test_tipc/output/norm_train_gpus_0_autocast_null !Run successfully with command - python3.7 inference.py --use_gpu=True --use_tensorrt=False --precision=fp32 --model_file=./test_tipc/output/norm_train_gpus_0_autocast_null/model.pdmodel --batch_size=2 --input_file=./dataset/ILSVRC2012/val --params_file=./test_tipc/output/norm_train_gpus_0_autocast_null/model.pdiparams > ./test_tipc/output/python_infer_gpu_usetrt_False_precision_fp32_batchsize_2.log 2>&1 !...
更多详细内容,请参考:TIPC测试文档。
以上就是基于PaddlePaddle复现的CycleMLP的详细内容,更多请关注创想鸟其它相关文章!
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 chuangxiangniao@163.com 举报,一经查实,本站将立刻删除。
发布者:程序猿,转转请注明出处:https://www.chuangxiangniao.com/p/39316.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 


























