
基于PaddlePaddle3.0搭建神经网络,来实现36类时间段动作的识别,目前测试集准确度约为91.25%,识别输入的手势,可遥控开灯开空调以及开原神
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

项目起源
项目起源于同学在进行魔法棒控制灯光开关、空调开关、原神启动等诸多功能的实现,但是要实现多类手势的分类,单纯通过硬件部分定义各类手势十分困难;
本人在查询资料的过程中发现,可以结合轻量级神经网络进行实现,完成端侧部分的集成使用,快速实现手势的识别,同时也好奇对于手势这种时间段的动作,如何才能实现精确的识别?
因此开展了本项目,自行基于PaddlePaddle3.0搭建神经网络,来实现36类时间段动作的识别,识别输入的手势,可遥控开灯开空调以及开原神;
目前测试集准确度约为91.25%,可识别字符(当前为字母 A ~ Z,数字 0 ~ 9)更多的模型;

数据集处理
数据集介绍
数据上采用 BMI088 采集挥棒手势数据,单次采集时间 2s,包括有字母 A ~ Z,数字 0 ~ 9这些手势数据,每类各有80个CSV文件进行存储

采集数据如下所示,共3列数据,因设置的采集时间为2s,2s足够完成一个动作,每个CSV文件内约有128条左右的数据
本部分数据集已经上传至AI studio星河社区,各位可自行下载研究使用,【数据集链接】https://aistudio.baidu.com/datasetdetail/296940
In [ ]
!unzip /home/aistudio/data/data296940/rawData.zip -d work/
类别映射
本部分主要实现三方面操作
1、首先实现从指定数据集文件夹中批量读取加速度计数据,并对数据进行预处理,包括行数标准化、低通滤波去噪和结构重组,以确保数据的一致性和质量;
2、这些处理后的数据及其标签被存储在列表中,以便后续用于机器学习模型的训练或数据分析,为后续数据进一步处理和分析打下基础;
3、因文件夹名字被读取后会转换为随机的数字作为数字标签存储,每次都是随机,因此本部分使用class_name字典存储数据处理存储标签和类别的映射;
In [13]
import osimport pandas as pdimport numpy as npfrom scipy import signal, fftimport matplotlib.pyplot as plt# 创建一个空列表来存储所有数据total_data = []# 设定标准的数据行数为 128 行STANDARD_ROWS = 128# 初始化滤波器b, a = signal.butter(8, 0.2, 'lowpass')''' signal.butter 是用于设计巴特沃斯数字滤波器的函数,本部分初始化了一个8阶巴特沃斯低通滤波器。 第一个参数8表示滤波器的阶数,阶数越高,滤波器的截止频率越陡峭,但计算量也越大。 第二个参数0.2表示归一化截止频率。归一化截止频率是指截止频率与采样频率的一半之比。在这个例子中,截止频率是采样频率的0.2倍。 第三个参数'lowpass'表示滤波器的类型为低通滤波器,它允许低于截止频率的信号通过,并衰减高于截止频率的信号。 作用:巴特沃斯低通滤波器通常用于去除信号中的高频噪声,同时保留低频信号。在代码中,它用于对加速度计数据进行滤波,以减少噪声的影响。'''lab_i = 0class_name={}# 遍历文件夹,folder这里代表文件夹for folder in os.listdir('work/rawData'): # 通过正则表达式判断文件夹名是否是字母和数字的组合 if folder.isalnum(): print("folder name:%c, label:%d"%(folder, lab_i)) class_name[lab_i] = folder # 拼接完整的文件夹路径 folder_path = os.path.join('work/rawData', folder) # print(folder_path)# # 遍历文件夹中的文件 for file in os.listdir(folder_path): if file.endswith('.csv'): # 确保只处理csv文件 # 获取文件的标签(文件夹名) label = lab_i# # 读取csv文件 df = pd.read_csv(os.path.join(folder_path, file)) # 检查数据行数,处理异常情况 rows = df.shape[0] # 获取数据行数 if rows STANDARD_ROWS: # 数据行数多于128行,忽略多余的数据 df = df[:STANDARD_ROWS] # 将每行三个数据分别命名为gx,gy,gz 并滤波处理 gx = signal.filtfilt(b, a, df.iloc[:, 0].tolist()) gy = signal.filtfilt(b, a, df.iloc[:, 1].tolist()) gz = signal.filtfilt(b, a, df.iloc[:, 2].tolist()) # 使用np.dstack重新组织数据,并reshape为(128, 3)的形状 data = np.dstack((gx, gy, gz)).reshape((128, 3)) # 128 datapoints with 3 channels # print(data) # 将处理后的数据和标签添加到total_data列表中 total_data.append((data, label)) lab_i = lab_i+1print(f"导入了 {np.array(total_data, dtype=object).shape[0]} 个动作数据样本,每个动作样本有 2秒×64Hz×3轴 个数据")
folder name:P, label:0folder name:N, label:1folder name:A, label:2folder name:H, label:3folder name:3, label:4folder name:1, label:5folder name:2, label:6folder name:R, label:7folder name:6, label:8folder name:F, label:9folder name:U, label:10folder name:0, label:11folder name:X, label:12folder name:7, label:13folder name:D, label:14folder name:Z, label:15folder name:K, label:16folder name:S, label:17folder name:L, label:18folder name:4, label:19folder name:I, label:20folder name:J, label:21folder name:M, label:22folder name:B, label:23folder name:C, label:24folder name:T, label:25folder name:Y, label:26folder name:E, label:27folder name:5, label:28folder name:9, label:29folder name:W, label:30folder name:Q, label:31folder name:O, label:32folder name:V, label:33folder name:8, label:34folder name:G, label:35导入了 2916 个动作数据样本,每个动作样本有 2秒×64Hz×3轴 个数据
数据集分析
本部分代码操作有如下三方面:
1、通过随机种子打乱数据集,并将其分割为训练集、验证集和测试集,然后分别提取每个集合的数据和标签,并转换为NumPy数组以供后续使用;
Train data shpae is (1749, 128, 3)Train label shpae is (1749, 1)Validation data shpae is (584, 128, 3)Validation label shpae is (584, 1)Test data shpae is (583, 128, 3)Test label shpae is (583, 1)
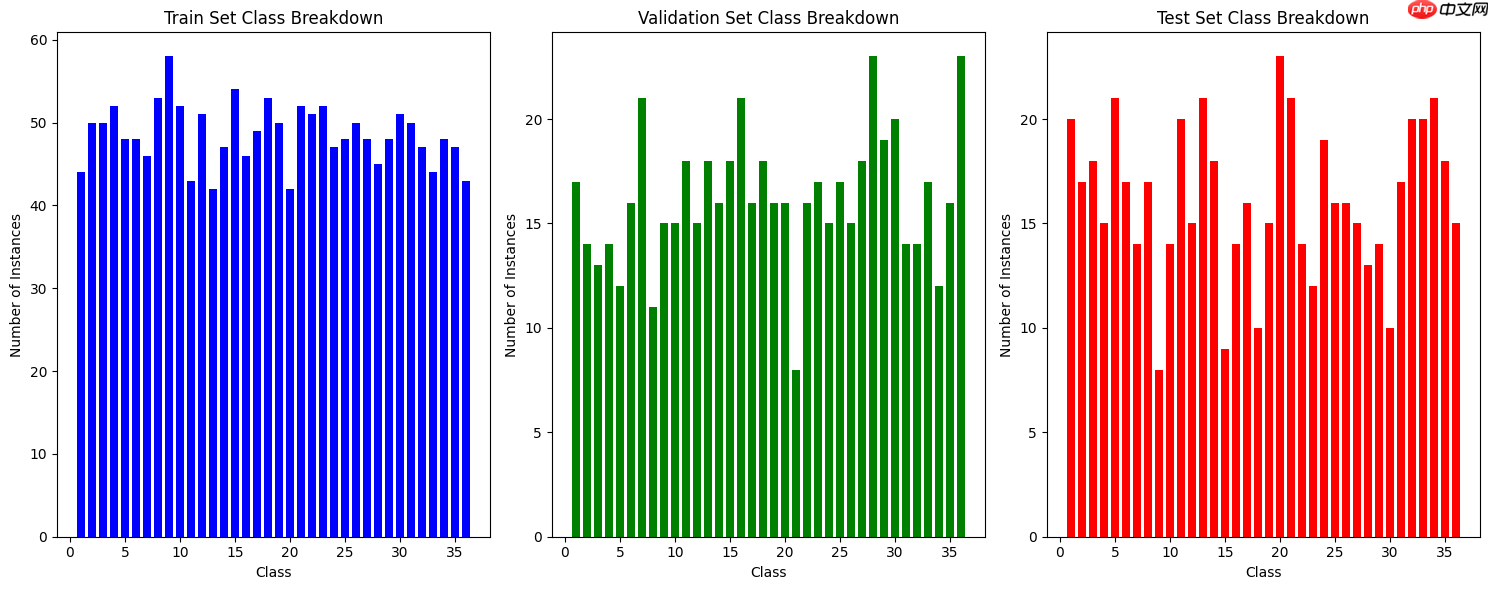
2、定义用于统计和可视化数据集中类别分布的函数,并应用这些函数来输出训练集、验证集和测试集中每个类别的实例数量及其百分比,并通过条形图进行可视化展示;
3、将标签数据从NumPy数组转换为PaddlePaddle的Tensor,并使用one-hot编码将这些标签转换为可用于分类任务的格式;
In [14]
np.random.seed(25682568)np.random.shuffle(total_data) # 打乱数据集train = total_data[0:1749] # 60%val = total_data[1749:2333] # 20%test = total_data[2333:2916] # 20%test_data = []test_label = []train_data = []train_label = []val_data = []val_label = []for i in range(len(test)): test_data.append(test[i][0]) test_label.append([test[i][1]])for i in range(len(train)): train_data.append(train[i][0]) train_label.append([train[i][1]])for i in range(len(val)): val_data.append(val[i][0]) val_label.append([val[i][1]])test_data=np.array(test_data)test_label=np.array(test_label)train_data=np.array(train_data)train_label=np.array(train_label)val_data=np.array(val_data)val_label=np.array(val_label)print("Train data shpae is ",train_data.shape,)print("Train label shpae is ",train_label.shape,)print("Validation data shpae is ",val_data.shape,)print("Validation label shpae is ",val_label.shape,)print("Test data shpae is ",test_data.shape,)print("Test label shpae is ",test_label.shape,)
Train data shpae is (1749, 128, 3)Train label shpae is (1749, 1)Validation data shpae is (584, 128, 3)Validation label shpae is (584, 1)Test data shpae is (583, 128, 3)Test label shpae is (583, 1)
In [ ]
train_counts=[]val_counts=[]test_counts=[]import pandas as pdimport matplotlib.pyplot as pltdef class_breakdown(data): df = pd.DataFrame(data) counts = df.groupby(0).size() counts = counts.values for i in range(len(counts)): percent = counts[i] / len(df) * 100 print('Class=%d, total=%d, percentage=%.3f' % (i+1, counts[i], percent)) def class_breakdown(data): df = pd.DataFrame(data) counts = df.groupby(0).size() counts = counts.values summary = {} for i in range(len(counts)): percent = counts[i] / len(df) * 100 summary[i+1] = {'total': counts[i], 'percentage': percent} print('Class=%d, total=%d, percentage=%.3f' % (i+1, counts[i], percent)) return summarydef plot_class_breakdown(train_summary, val_summary, test_summary): num_classes = len(train_summary) classes = list(range(1, num_classes + 1)) plt.figure(figsize=(15, 6)) # Train set plt.subplot(1, 3, 1) plt.bar(classes, [train_summary[c]['total'] for c in classes], color='blue') plt.title('Train Set Class Breakdown') plt.xlabel('Class') plt.ylabel('Number of Instances') # Validation set plt.subplot(1, 3, 2) plt.bar(classes, [val_summary[c]['total'] for c in classes], color='green') plt.title('Validation Set Class Breakdown') plt.xlabel('Class') plt.ylabel('Number of Instances') # Test set plt.subplot(1, 3, 3) plt.bar(classes, [test_summary[c]['total'] for c in classes], color='red') plt.title('Test Set Class Breakdown') plt.xlabel('Class') plt.ylabel('Number of Instances') # Adjust layout plt.tight_layout() plt.show()# Assuming train_label, val_label, and test_label are defined and are numpy arraysprint("Train set:")train_summary = class_breakdown(train_label)print("")print("Validation set:")val_summary = class_breakdown(val_label)print("")print("Test set:")test_summary = class_breakdown(test_label)print("")# Plot the class breakdownplot_class_breakdown(train_summary, val_summary, test_summary)
In [16]
import paddlenum_classes = 36 # 假设你已经知道类别数# 将NumPy数组转换为PaddlePaddle的Tensortest_label_tensor = paddle.to_tensor(test_label)train_label_tensor = paddle.to_tensor(train_label)val_label_tensor = paddle.to_tensor(val_label)# 使用paddle.nn.functional.one_hot进行one-hot编码test_label = paddle.nn.functional.one_hot(test_label_tensor, num_classes=num_classes)train_label = paddle.nn.functional.one_hot(train_label_tensor, num_classes=num_classes)val_label = paddle.nn.functional.one_hot(val_label_tensor, num_classes=num_classes)
数据集迭代器构建
本部分段打印测试标签的前三个元素,显示并绘制了一个名为gx的变量,并定义了一个输入规格用于PaddlePaddle的静态图模型,测试数据情况;
确认无误后,接着将NumPy数组转换为PaddlePaddle的Tensor,调整数据维度,并创建用于训练、验证和测试的DataLoader,以便在模型训练过程中高效地加载数据。
In [17]
import paddleimport numpy as npimport matplotlib.pyplot as plt# 打印前3个test_labelprint(test_label[:3])# 打印gxprint(gx)# 打印gx的长度print(len(gx))# 绘制gxplt.plot(gx)plt.show()# 假设train_data是已经存在的数据# 使用paddle.static.InputSpec定义输入input_spec = paddle.static.InputSpec([None] + list(train_data.shape[1:]), 'float32', name='train_data')print(input_spec)
Tensor(shape=[3, 1, 36], dtype=float32, place=Place(gpu:0), stop_gradient=True, [[[0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 1., 0., 0., 0., 0., 0., 0., 0., 0.]], [[0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 1.]], [[0., 0., 0., 1., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.]]])[ 1.20875555e+02 2.01146993e+02 2.48668160e+02 2.40243576e+02 1.67564358e+02 3.83636316e+01 -1.27368545e+02 -3.04559146e+02 -4.70936913e+02 -6.12849609e+02 -7.27189817e+02 -8.19217004e+02 -8.97661820e+02 -9.69422417e+02 -1.03605784e+03 -1.09326700e+03 -1.13313758e+03 -1.14782125e+03 -1.13290861e+03 -1.08920064e+03 -1.02247078e+03 -9.41686157e+02 -8.56621264e+02 -7.75753085e+02 -7.04938648e+02 -6.46923398e+02 -6.01428452e+02 -5.65489059e+02 -5.33815137e+02 -4.99122576e+02 -4.52559806e+02 -3.84469519e+02 -2.85726703e+02 -1.49732327e+02 2.51876163e+01 2.33634833e+02 4.62189477e+02 6.90548335e+02 8.95107687e+02 1.05443222e+03 1.15508853e+03 1.19577653e+03 1.18793474e+03 1.15208205e+03 1.11074304e+03 1.08024981e+03 1.06436995e+03 1.05222841e+03 1.02150403e+03 9.45967568e+02 8.04851064e+02 5.90911554e+02 3.14578752e+02 2.98543830e+00 -3.05619501e+02 -5.70222207e+02 -7.55724662e+02 -8.39781605e+02 -8.16469212e+02 -6.96481416e+02 -5.04363599e+02 -2.73714167e+02 -4.13519920e+01 1.58652983e+02 3.00274016e+02 3.69349378e+02 3.65182394e+02 2.99429431e+02 1.92353723e+02 6.72985326e+01 -5.50846157e+01 -1.61088669e+02 -2.45360656e+02 -3.09167698e+02 -3.56441482e+02 -3.89421689e+02 -4.05877308e+02 -3.99199661e+02 -3.61401595e+02 -2.87753940e+02 -1.81003076e+02 -5.31879455e+01 7.60075435e+01 1.84045124e+02 2.51862392e+02 2.69487376e+02 2.38919975e+02 1.73279182e+02 9.25852160e+01 1.77201878e+01 -3.53501178e+01 -5.92648177e+01 -5.59205581e+01 -3.42633793e+01 -6.32134030e+00 1.69957777e+01 2.89602563e+01 2.81808340e+01 1.78343539e+01 3.59500538e+00 -8.80595121e+00 -1.55148380e+01 -1.54496581e+01 -1.00725954e+01 -2.35161738e+00 4.56924931e+00 8.48008110e+00 8.66457132e+00 5.83315611e+00 1.58273950e+00 -2.33434373e+00 -4.64284985e+00 -4.88278899e+00 -3.39845196e+00 -1.05423734e+00 1.16898348e+00 2.53406301e+00 2.74992057e+00 1.97928348e+00 6.89325620e-01 -5.71200463e-01 -1.37679146e+00 -1.54550246e+00 -1.15095065e+00 -4.44274748e-01 2.68576782e-01 7.42907490e-01 8.66262532e-01]128
InputSpec(shape=(-1, 128, 3), dtype=paddle.float32, name=train_data, stop_gradient=False)
In [18]
from paddle.io import DataLoader# 将numpy数组转换为paddle.Tensor,并确保数据类型为float32train_data = paddle.to_tensor(train_data, dtype='float32', stop_gradient=True)train_label = paddle.to_tensor(train_label.squeeze(), dtype='float32', stop_gradient=True)val_data = paddle.to_tensor(val_data, dtype='float32', stop_gradient=True)val_label = paddle.to_tensor(val_label.squeeze(), dtype='float32', stop_gradient=True)test_data = paddle.to_tensor(test_data, dtype='float32', stop_gradient=True)test_label = paddle.to_tensor(test_label.squeeze(), dtype='float32', stop_gradient=True)# 调整数据维度print(train_data.shape)# 创建DataLoadertrain_loader = DataLoader(list(zip(train_data, train_label)), batch_size=100, shuffle=True)val_loader = DataLoader(list(zip(val_data, val_label)), batch_size=100, shuffle=False)test_loader = DataLoader(list(zip(test_data, test_label)), batch_size=100, shuffle=False)
[1749, 128, 3]
模型训练
训练网络构建
本部分代码定义了一个名为ConvNet的卷积神经网络类,包含两个卷积层、一个最大池化层、两个全连接层,并使用ReLU激活函数;
同时设置交叉熵损失函数和带权重衰减的Adam优化器,用于模型的训练过程;
(conv1): Conv1D(3, 64, kernel_size=[3], padding=1, data_format=NCL) (conv2): Conv1D(64, 64, kernel_size=[3], padding=1, data_format=NCL) (pool): MaxPool1D(kernel_size=2, stride=None, padding=0) (fc1): Linear(in_features=4096, out_features=128, dtype=float32) (fc2): Linear(in_features=128, out_features=36, dtype=float32) (softmax): Softmax(axis=1)
In [19]
import paddleimport paddle.nn as nnimport paddle.nn.functional as Fimport paddle.optimizer as optimfrom paddle.nn import Conv1D, MaxPool1D, Flatten, Linear, ReLU, Softmax# 定义模型类class ConvNet(nn.Layer): def __init__(self): super(ConvNet, self).__init__() # 添加一维卷积层,卷积核大小为3,数量为64,输入形状为(128,3) self.conv1 = nn.Conv1D(in_channels=3, out_channels=64, kernel_size=3, stride=1, padding=1) # 添加一维卷积层,卷积核大小为3,数量为64 self.conv2 = Conv1D(in_channels=64, out_channels=64, kernel_size=3, stride=1, padding=1) # 添加一维最大池化层,池化窗口大小为2 self.pool = nn.MaxPool1D(kernel_size=2) # 添加全连接层,节点数为128 self.fc1 = nn.Linear(64 * 64, 128) # 64是池化后的特征数 # 添加输出层,节点数为类别数 self.fc2 = nn.Linear(128, 36) # 如果有其他数量的类别,请修改这里的节点数 self.softmax = Softmax(axis=1) # 创建Softmax实例 def forward(self, x): # 通过卷积层、激活函数和池化层 x = F.relu(self.conv1(x)) # print(x.shape) x = F.relu(self.conv2(x)) # print(x.shape) x = self.pool(x) # print(x.shape) # 展平层 x = paddle.flatten(x, 1) # 通过全连接层和激活函数 x = F.relu(self.fc1(x)) x = self.fc2(x) # print(x.shape) # x = self.softmax(x) return x# 实例化模型model = ConvNet()# 定义损失函数和优化器criterion = nn.CrossEntropyLoss(soft_label=False)optimizer = optim.Adam(parameters=model.parameters(),weight_decay=paddle.regularizer.L2Decay(coeff=1e-4),learning_rate=0.0001)model
ConvNet( (conv1): Conv1D(3, 64, kernel_size=[3], padding=1, data_format=NCL) (conv2): Conv1D(64, 64, kernel_size=[3], padding=1, data_format=NCL) (pool): MaxPool1D(kernel_size=2, stride=None, padding=0) (fc1): Linear(in_features=4096, out_features=128, dtype=float32) (fc2): Linear(in_features=128, out_features=36, dtype=float32) (softmax): Softmax(axis=1))
训练进行
主要进行如下三部分操作:
1、实现了模型的训练和评估过程,通过train函数进行迭代训练,并计算每个epoch的损失和准确率,同时保存训练过程中的迭代次数和损失值;
2、在训练结束时,代码保存了模型参数、优化器参数以及最后一个epoch的检查点信息,以便后续进行模型恢复和继续训练;
3、在最后绘制出训练过程中Loss的变化曲线,便于观察训练过程有无问题出现;
Epoch 297, Loss: 0.0018434367246097988Epoch 297, Val Loss: 45.983871936798096, Val Acc: 89.73%Epoch 298, Loss: 0.0018418160163693959Epoch 298, Val Loss: 45.983682791392006, Val Acc: 89.73%Epoch 299, Loss: 0.0018405009888940388Epoch 299, Val Loss: 45.98337427775065, Val Acc: 89.73%Epoch 300, Loss: 0.001838982105255127Epoch 300, Val Loss: 45.98327096303304, Val Acc: 89.73%
In [ ]
iters=[]losses=[]final_checkpoint = dict()# 评估模型def evaluate(model, loader): model.eval() # 设置模型为评估模式 total_loss = 0.0 correct = 0 total = 0 for inputs, labels in loader: # 转换数据形状为 (batch_size, channels, length) inputs = paddle.transpose(inputs, perm=[0, 2, 1]) outputs = model(inputs) labels = paddle.argmax(labels, axis=1) loss = criterion(outputs, labels) total_loss += loss.item() # 获取预测结果 # print(outputs[1]) # print(labels) predicted = paddle.argmax(outputs, axis=1) # print(predicted) # 计算准确率 correct += (predicted == labels).sum().item() total += labels.shape[0] avg_loss = total_loss / len(loader) accuracy = correct / total return avg_loss, accuracy# 训练模型def train(model, train_loader, val_loader, epochs): for epoch in range(epochs): model.train() running_loss = 0.0 for i, data in enumerate(train_loader, 0): inputs, labels = data # print(inputs.shape) # 转换数据形状为 (batch_size, channels, length) inputs = paddle.transpose(inputs, perm=[0, 2, 1]) optimizer.clear_grad() outputs = model(inputs) labels = paddle.argmax(labels, axis=1) loss = criterion(outputs, labels) avg_loss = paddle.mean(loss) # 累计迭代次数和对应的loss iters.append(epoch*len(labels)) losses.append(avg_loss) loss.backward() optimizer.step() running_loss += loss.item() print(f'Epoch {epoch+1}, Loss: {running_loss/len(train_loader)}') # 在验证集上评估模型 val_loss, val_accuracy = evaluate(model, val_loader) print(f'Epoch {epoch+1}, Val Loss: {val_loss}, Val Acc: {val_accuracy*100:.2f}%') # 最后一个epoch保存检查点checkpoint if epoch == 149: final_checkpoint["epoch"] = epoch final_checkpoint["loss"] = loss # #保存模型参数 # paddle.save(model.state_dict(), 'mnist_regul.pdparams') # 保存model参数 paddle.save(model.state_dict(), "linear_net.pdparams") # 保存优化器参数 paddle.save(optimizer.state_dict(), "adam.pdopt") # 保存检查点checkpoint信息 paddle.save(final_checkpoint, "final_checkpoint.pkl")# 假设train_loader和val_loader是已经定义好的DataLoadertrain(model, train_loader, val_loader, 300)
In [21]
#画出训练过程中Loss的变化曲线plt.figure()plt.title("train loss", fontsize=24)plt.xlabel("iter", fontsize=14)plt.ylabel("loss", fontsize=14)plt.plot(iters, losses,color='red',label='train loss') plt.grid()plt.show()
模型整体评估
本部分段定义了一个名为 evaluate 的函数,接受一个模型、一个测试数据加载器以及一个损失函数作为输入,用于在测试数据集上评估模型的性能;
函数内部将模型设置为评估模式,初始化总损失和正确预测计数器,然后遍历测试数据加载器中的每个批次;
在每个批次中调整输入数据的形状,通过模型获取输出,计算损失并更新总损失,并比较预测结果与标签以更新正确预测的计数;
最后计算并返回平均损失和准确率,并在调用该函数后打印测试损失和准确率;
Test Loss: 46.4569943745931, Test Accuracy: 91.25%
In [22]
import paddledef evaluate(model, test_loader, criterion): model.eval() # 将模型设置为评估模式 total_loss = 0.0 correct = 0 total = 0 for inputs, labels in test_loader: inputs = paddle.transpose(inputs, perm=[0, 2, 1]) # 调整输入数据的形状 outputs = model(inputs) labels = paddle.argmax(labels, axis=1) loss = criterion(outputs, labels) # 计算损失 total_loss += loss.item() predicted = paddle.argmax(outputs, axis=1) # 获取预测结果 correct += (predicted == labels).sum().item() total += labels.shape[0] avg_loss = total_loss / len(test_loader) accuracy = correct / total return avg_loss, accuracy# test_loader 是测试数据加载器# criterion 是损失函数# 调用 evaluate 函数来测试模型test_loss, test_accuracy = evaluate(model, test_loader, criterion)print(f"Test Loss: {test_loss}, Test Accuracy: {test_accuracy * 100:.2f}%")
Test Loss: 49.052333196004234, Test Accuracy: 87.82%
推理测试
模型加载
首先加载了之前训练的卷积神经网络模型参数、优化器参数以及最终的训练检查点,并重新关联到模型和优化器上,然后打印保存的检查点信息。
Loaded Final Checkpoint. Epoch : 149, Loss : 0.0
In [23]
import pandas as pdimport numpy as npimport paddlefrom scipy import signal# 实例化模型model = ConvNet()# param_dict = paddle.load('/home/aistudio/mnist_regul.pdparams')# model.set_state_dict(param_dict)# 载入模型参数、优化器参数和最后一个epoch保存的检查点model_state_dict = paddle.load("linear_net.pdparams")opt_state_dict = paddle.load("adam.pdopt")final_checkpoint_dict = paddle.load("final_checkpoint.pkl")# 将load后的参数与模型关联起来model.set_state_dict(model_state_dict)optimizer.set_state_dict(opt_state_dict)# 打印出来之前保存的 checkpoint 信息print( "Loaded Final Checkpoint. Epoch : {}, Loss : {}".format( final_checkpoint_dict["epoch"], final_checkpoint_dict["loss"].numpy() ))
Loaded Final Checkpoint. Epoch : 149, Loss : 0.0
推理实现
本部分定义了一个滤波器函数filter_data,用于对输入数据进行低通滤波处理,通过定义的predict_from_csv函数,读取CSV文件中的数据,根据数据行数进行适当的填充或裁剪;
接着应用滤波器,将处理后的数据转换为PaddlePaddle的Tensor,然后将模型设置为评估模式,禁用梯度计算以进行推理,并返回模型的预测结果;
最后使用softmax函数将预测的logits转换为概率分布,并通过argmax找到预测的类别索引,打印出预测的类别名称;
Prediction: Tensor(shape=[1, 36], dtype=float32, place=Place(gpu:0), stop_gradient=True, [[ 74.05798340 , -3079.14428711, -980.79516602 , -651.90545654 , -445.17956543 , 754.55334473 , 1467.66772461, -4221.56884766, 1359.46069336, -6019.58886719, -3092.41357422, -2200.08032227, 2534.37011719, -2090.34619141, -1726.27294922, -1667.51159668, 520.28381348 , -2390.97949219, 1313.23974609, 4192.66796875, -1726.86071777, 484.49822998 , -3699.26684570, 3221.54736328, -1274.19323730, -4175.11718750, -2077.25366211, -36.47094727 , 2935.93505859, 1057.33081055, 4233.02539062, -455.59204102 , 490.94299316 , 15.99664307 , -1210.64855957, 2860.55053711]])Predicted class index: 30Predicted class: I
In [24]
# 定义滤波器def filter_data(data): b, a = signal.butter(8, 0.2, 'lowpass') gx = signal.filtfilt(b, a, data.iloc[:, 0].tolist()) gy = signal.filtfilt(b, a, data.iloc[:, 1].tolist()) gz = signal.filtfilt(b, a, data.iloc[:, 2].tolist()) return np.dstack((gx, gy, gz))# 读取CSV文件并进行推理def predict_from_csv(model, csv_file_path): # 读取 CSV 文件 df = pd.read_csv(csv_file_path) # 检查数据行数,处理异常情况 rows = df.shape[0] # print(rows) # 读取csv文件 if rows 128: # 数据行数多于128行,忽略多余的数据 df = df[:128] # print(df) # 预处理数据 # data = df.values.astype('float32') # print(data) data = filter_data(df) # # 将数据转换为 PaddlePaddle 的 Tensor data_tensor = paddle.to_tensor(data).astype('float32') # 增加一个批次维度 data_tensor =paddle.transpose(data_tensor, perm=[0, 2, 1]) # 确保模型处于评估模式 model.eval() # 禁用梯度计算 with paddle.no_grad(): # 进行预测 prediction = model(data_tensor) # # 返回预测结果 return prediction# 假设你的模型已经加载并且路径已经设置好csv_file_path = '/home/aistudio/work/rawData/A/A-042.csv'prediction = predict_from_csv(model, csv_file_path)print("Prediction:", prediction)# 使用 softmax 函数将 logits 转换为概率分布probabilities = paddle.nn.functional.softmax(prediction, axis=1)# 使用 argmax 找到最高概率的类别索引predicted_class = paddle.argmax(probabilities, axis=1)print("Predicted class index:", predicted_class.numpy()[0])print("Predicted class:", class_name[predicted_class.numpy()[0]])
Prediction: Tensor(shape=[1, 36], dtype=float32, place=Place(gpu:0), stop_gradient=True, [[-742.07122803, 433.16378784, 2300.90014648, 692.43029785, -261.68905640, 359.95938110, 7.98300982 , -476.44030762, -114.69995880, -813.12304688, 497.81570435, 265.21386719, -778.95989990, -106.62953186, 1078.16625977, -802.24346924, -542.18072510, 219.70364380, 302.81433105, -341.49166870, -211.36538696, 676.91662598, 592.84680176, 830.86907959, 44.48839188 , -1603.02880859, -1100.03125000, 1314.32409668, 506.53070068, 252.42399597, -288.21667480, 535.08489990, 40.10396957 , 805.63195801, -591.93084717, -273.43447876]])Predicted class index: 2Predicted class: A
以上就是【赛博魔杖】PaddlePaddle3.0助力36类魔法手势识别的详细内容,更多请关注创想鸟其它相关文章!
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 chuangxiangniao@163.com 举报,一经查实,本站将立刻删除。
发布者:程序猿,转转请注明出处:https://www.chuangxiangniao.com/p/40426.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 
























