

作者 徐麟
本文经授权转自公众号数据森麟(ID: shujusenlin)
房价高是北漂们一直关心的话题,本文就对北京的二手房数据进行了分析。
本文主要分为两部分:Python爬取赶集网北京二手房数据,R对爬取的二手房房价做线性回归分析,适合刚刚接触Python&R的同学们学习参考。
01
立即学习“Python免费学习笔记(深入)”;
Python爬取赶集网北京二手房数据
入门爬虫一个月,所以对每一个网站都使用了Xpath、Beautiful Soup、正则三种方法分别爬取,用于练习巩固。数据来源如下:
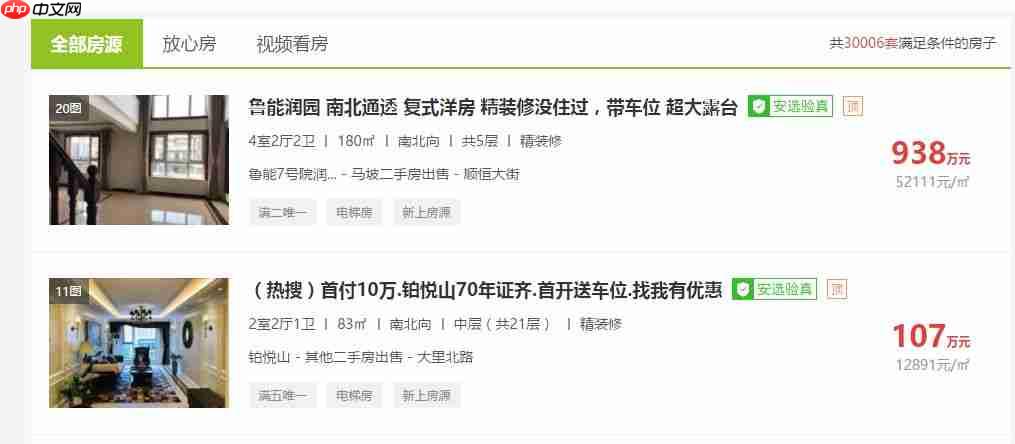
Xpath爬取:
这里主要解决运用Xpath如何判断某些元素是否存在的问题,比如如果房屋没有装修信息,不加上判断,某些元素不存在就会导致爬取中断。
代码语言:javascript代码运行次数:0运行复制
import requestsfrom lxml import etreefrom requests.exceptions import RequestExceptionimport multiprocessingimport timeheaders = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36'}def get_one_page(url): try: response = requests.get(url, headers=headers) if response.status_code == 200: return response.text return None except RequestException: return Nonedef parse_one_page(content): try: selector = etree.HTML(content) ALL = selector.xpath('//*[@id="f_mew_list"]/div[6]/div[1]/div[3]/div[1]/div') for div in ALL: yield { 'Name': div.xpath('dl/dd[1]/a/text()')[0], 'Type': div.xpath('dl/dd[2]/span[1]/text()')[0], 'Area': div.xpath('dl/dd[2]/span[3]/text()')[0], 'Towards': div.xpath('dl/dd[2]/span[5]/text()')[0], 'Floor': div.xpath('dl/dd[2]/span[7]/text()')[0].strip().replace('', ""), 'Decorate': div.xpath('dl/dd[2]/span[9]/text()')[0], #地址需要特殊处理一下 'Address': div.xpath('dl/dd[3]//text()')[1]+div.xpath('dl/dd[3]//text()')[3].replace('','')+div.xpath('dl/dd[3]//text()')[4].strip(), 'TotalPrice': div.xpath('dl/dd[5]/div[1]/span[1]/text()')[0] + div.xpath('dl/dd[5]/div[1]/span[2]/text()')[0], 'Price': div.xpath('dl/dd[5]/div[2]/text()')[0] } if div['Name','Type','Area','Towards','Floor','Decorate','Address','TotalPrice','Price'] == None:##这里加上判断,如果其中一个元素为空,则输出None return None except Exception: return Nonedef main(): for i in range(1, 500):#这里设置爬取500页数据,在数据范围内,大家可以自设置爬取的量 url = 'http://bj.ganji.com/fang5/o{}/'.format(i) content = get_one_page(url) print('第{}页抓取完毕'.format(i)) for div in parse_one_page(content): print(div)if __name__ == '__main__': main()Beautiful Soup爬取:
代码语言:javascript代码运行次数:0运行复制
import requestsimport refrom requests.exceptions import RequestExceptionfrom bs4 import BeautifulSoupimport csvimport timeheaders = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36'}def get_one_page(url): try: response = requests.get(url,headers = headers) if response.status_code == 200: return response.text return None except RequestException: return Nonedef parse_one_page(content): try: soup = BeautifulSoup(content,'html.parser') items = soup.find('div',class_=re.compile('js-tips-list')) for div in items.find_all('div',class_=re.compile('ershoufang-list')): yield { 'Name':div.find('a',class_=re.compile('js-title')).text, 'Type': div.find('dd', class_=re.compile('size')).contents[1].text,#tag的 .contents 属性可以将tag的子节点以列表的方式输出 'Area':div.find('dd',class_=re.compile('size')).contents[5].text, 'Towards':div.find('dd',class_=re.compile('size')).contents[9].text, 'Floor':div.find('dd',class_=re.compile('size')).contents[13].text.replace('',''), 'Decorate':div.find('dd',class_=re.compile('size')).contents[17].text, 'Address':div.find('span',class_=re.compile('area')).text.strip().replace(' ','').replace('',''), 'TotalPrice':div.find('span',class_=re.compile('js-price')).text+div.find('span',class_=re.compile('yue')).text, 'Price':div.find('div',class_=re.compile('time')).text } #有一些二手房信息缺少部分信息,如:缺少装修信息,或者缺少楼层信息,这时候需要加个判断,不然爬取就会中断。 if div['Name', 'Type', 'Area', 'Towards', 'Floor', 'Decorate', 'Address', 'TotalPrice', 'Price'] == None: return None except Exception: return Nonedef main(): for i in range(1,50): url = 'http://bj.ganji.com/fang5/o{}/'.format(i) content = get_one_page(url) print('第{}页抓取完毕'.format(i)) for div in parse_one_page(content): print(div) with open('Data.csv', 'a', newline='') as f: # Data.csv 文件存储的路径,如果默认路径就直接写文件名即可。 fieldnames = ['Name', 'Type', 'Area', 'Towards', 'Floor', 'Decorate', 'Address', 'TotalPrice', 'Price'] writer = csv.DictWriter(f, fieldnames=fieldnames) writer.writeheader() for item in parse_one_page(content): writer.writerow(item) time.sleep(3)#设置爬取频率,一开始我就是爬取的太猛,导致网页需要验证。if __name__=='__main__': main()正则爬取:我研究了好久,还是没有解决。
这一过程中容易遇见的问题有:
有一些房屋缺少部分信息,如缺少装修信息,这个时候需要加一个判断,如果不加判断,爬取就会自动终止(我在这里跌了很大的坑)。Data.csv知识点存储文件路径默认是工作目录,关于Python中如何查看工作目录:代码语言:javascript代码运行次数:0运行复制
import os #查看pyhton 的默认工作目录print(os.getcwd())#修改时工作目录os.chdir('e:workpython')print(os.getcwd())#输出工作目录e:workpython爬虫打印的是字典形式,每个房屋信息都是一个字典,由于Python中excel相关库是知识盲点,所以爬虫的时候将字典循环直接写入了CSV。
Pycharm中打印如下:

将字典循环直接写入CSV效果如下:
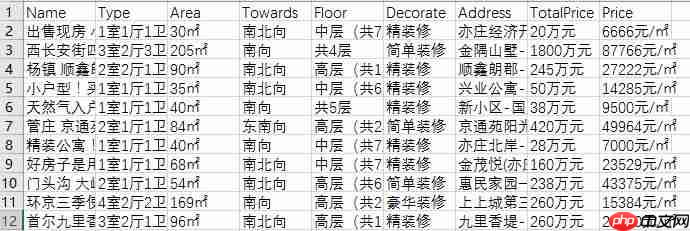
很多初学者对于Address不知如何处理,这里强调一下Beautiful Soup 中.contents的用法,亲身体会,我在这里花了好多时间才找到答案。

02
R对爬取的二手房房价做一般线性回归分析
下面我们用R对抓取的赶集网北京二手房数据做一些简单的分析。
数据的说明
数据清洗
代码语言:javascript代码运行次数:0运行复制
data<-read.csv("E://Data For R/RData/data.csv")DATA<-data[,-c(1,7)]#将Name和Address两列去掉DATA[sample(1:nrow(DATA),size=10),]
代码语言:javascript代码运行次数:0运行复制
#在爬取的时候加入了判断,所以不知道爬取的数据中是否存在缺失值,这里检查一下colSums(is.na(DATA))
代码语言:javascript代码运行次数:0运行复制
#这里将Type的卧室客厅和卫生间分为三个不同的列##这里需要注意,有一些房屋没有客厅如:1室1卫这时候需要单独处理,还有一些没有厕所信息。library(tidyr)library(stringr)DATA=separate(data=DATA,col=Type,into = c("Bedrooms","Halls"),sep="室")DATA=separate(data=DATA,col=Halls,into = c("Halls","Toilet"),sep="厅")##将卫生间后面的汉字去掉DATA$Toilet<-str_replace(DATA$Toilet,"卫","")###如图六,将Halls中带有汉字去掉,因为有一些房屋信息没有客厅,如:1室1厅,在分成卧室和客厅时,会将卫生间分到客厅一列。DATA$Halls<-str_replace(DATA$Halls,"卫","")##取出没有客厅信息的数据,这些数据被separate到Halls列newdata<-DATA[which(DATA$Toilet %in% NA),2]newdata##将没有客厅的房屋信息Halls列填充为0DATA[which(DATA$Toilet %in% NA),2]<-0DATA[which(DATA$Toilet %in% NA),3]<-newdatacolSums(DATA=="") Bedrooms Halls Toilet Area Towards Floor Decorate 0 0 2 0 0 0 0 TotalPrice Price 0 0 ##发现有2个厕所没有信息,将其填写为0。DATA$Toilet[DATA$Toilet == ""]<-0
代码语言:javascript代码运行次数:0运行复制
##这里将Area后的㎡去掉DATA$Area<-str_replace(DATA$Area,"㎡","")##查看Towards的类型table(DATA$Towards)Towards 北向 东北向 东南向 东西向 东向 南北向 南向 西北向 51 25 23 50 65 32 1901 678 38 西南向 西向 28 26 ##将Floor信息带括号的全部去除DATA$Floor<-str_replace(DATA$Floor,"[(].*[)]","")##正则表达式#查看Floor的类别信息 低层 地下 高层 共1层 共2层 共3层 共4层 共5层 中层 632 32 790 36 61 101 68 130 1016 #分别将TotalPrice和Price后面的万元、元/㎡去掉DATA$TotalPrice<-str_replace(DATA$TotalPrice,"万元","")DATA$Price<-str_replace(DATA$Price,"元/㎡","")head(DATA)
代码语言:javascript代码运行次数:0运行复制
##将数据转换格式DATA$Bedrooms<-as.factor(DATA$Bedrooms)DATA$Halls<-as.factor(DATA$Halls)DATA$Toilet<-as.factor(DATA$Toilet)DATA$Area<-as.numeric(DATA$Area)DATA$TotalPrice<-as.numeric(DATA$TotalPrice)DATA$Price<-as.numeric(DATA$Price)DATA$Towards<-as.factor(DATA$Towards)DATA$Decorate<-as.factor(DATA$Decorate)str(DATA)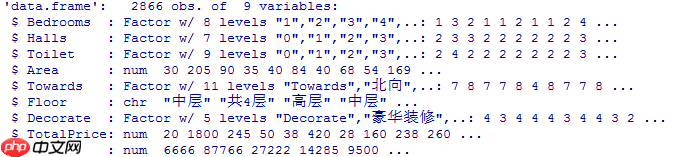
以上就是Python 爬取北京二手房数据,分析北漂族买得起房吗? | 附完整源码的详细内容,更多请关注创想鸟其它相关文章!
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 chuangxiangniao@163.com 举报,一经查实,本站将立刻删除。
发布者:程序猿,转转请注明出处:https://www.chuangxiangniao.com/p/40653.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 























